

 外贸B2B建站
外贸B2B建站  高端定制设计
高端定制设计  系统功能优势
系统功能优势 


 Google SEO优化
Google SEO优化  Google SEM广告
Google SEM广告  网站内容营销
网站内容营销  优化案例
优化案例  设计赏析
设计赏析  搜索引擎优化
搜索引擎优化  付费广告
付费广告  社媒运营
社媒运营  公司介绍
公司介绍  渠道共赢
渠道共赢  联系我们
联系我们 如果你想了解一个网站的内容,特别是大型出版商,你会从哪里开始?
我通常对以下问题感兴趣:
- 他们多久发布一次,发布多少?
- 他们的出版活动是否有每日,每周,每月或每年的趋势?
- 他们写什么主题,或者他们销售什么产品?
- 他们的主题有什么趋势? 哪些主题的数量在增加,哪些不是?
- 内容或产品如何跨语言、地区、类别或作者进行拆分?
在最基本的形式中,站点地图是要求只有"loc"标签(在父"url"标签下)。
本质上,一个网站地图被允许只是一个Url列表。 其他可选标签是允许的,最重要的是:
- "最后一个",
- "changefreq",
- "优先权",
- 而且,在某些情况下,"备用"。
如果您在站点地图中有"lastmod"(以及大多数信誉良好的网站),那么您可以获得与发布活动和趋势相关的所有信息。 然后,Url的丰富性决定了您可以提取多少信息,但请记住,如果Url的结构没有像example.com/product/12345,那么你将无法从站点地图中获得太多。
本教程的目标是使网站地图s不那么无聊!
我将分析BuzzFeed的站点地图,并且由于它们具有"lastmod"以及一致和丰富的Url,我们将能够回答上面提出的所有问题。
这将被用作"发布日期"的代理,因为页面得到更新,所以它不是100%准确。 一般来说,我发现,如果事情发生变化,他们倾向于在一两天内这样做以进行一些更正,而大多数人则没有。
Python进行分析
我将使用Python进行分析,这篇文章的交互式版本可以在这里找到. 如果你想跟着做,我鼓励你去看看。 通过这种方式,您可以进行更改并探索您可能会好奇的其他内容。
数据可视化也是交互式的,因此您将能够更好地缩放,悬停和探索。 如果你不知道任何编程,你可以安全地忽略所有的代码片段(无论如何我都会解释)。
那么让我们开始吧。
要以表格格式获取站点地图,我将使用网站地图_to_df功能从广告包。 "df"是DataFrame的简称,它基本上是一个数据表。
您只需将站点地图的URL(或站点地图索引URL)传递给函数,它就会以表格格式返回站点地图。 如果你给它一个站点地图索引,那么它将通过所有的子站点地图并提取Url和任何其他可用的数据。 除了广告工具,我将使用pandas进行数据操作,以及plotly进行数据可视化。
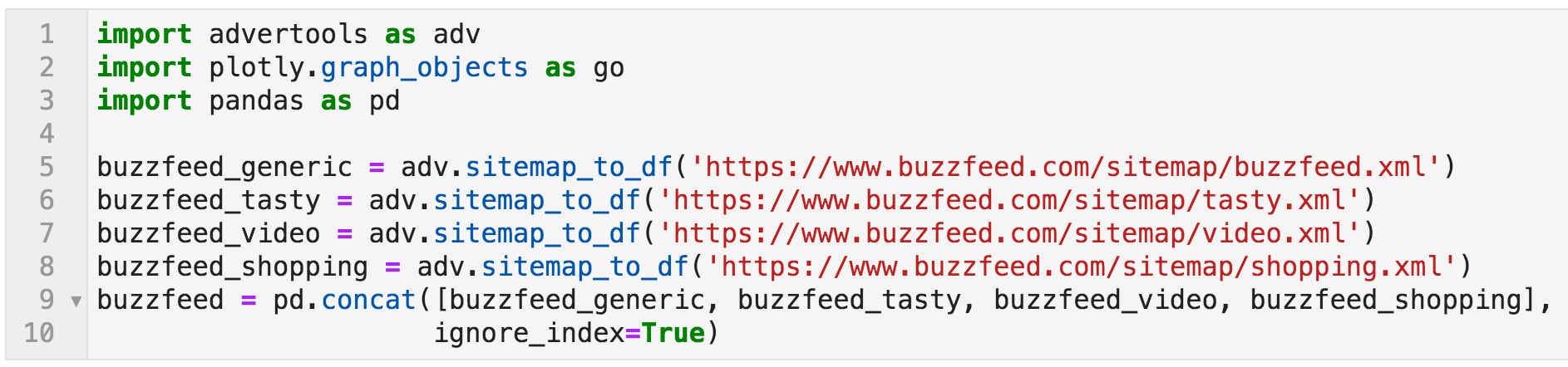 检索BuzzFeed的站点地图,并将它们合并到一个DataFrame中
检索BuzzFeed的站点地图,并将它们合并到一个DataFrame中
 来自"蜂鸣器,蜂鸣器"数据框的示例行
来自"蜂鸣器,蜂鸣器"数据框的示例行
上面是我们的DataFrame的一个子集-"lastmod"是索引,我们有两列;"loc"是Url,"网站地图"是从中检索URL的站点地图的URL。
"NaT"代表"not-a-time",它是日期/时间对象的缺失值表示。 正如你所看到的,我们有大约50万个Url要通过。
提取站点地图类别
如果您查看站点地图的Url,您将看到它们包含网站类别,例如:
https://www.蜂鸣器,蜂鸣器.com/网站地图/蜂鸣器,蜂鸣器/2019_5.xml
https://www.蜂鸣器,蜂鸣器.com/网站地图/购物/2018_13.xml
这有助于了解URL属于哪个类别。
要从这些Url中提取类别,以下行按正斜杠字符拆分XML Url,并采用结果列表的第五个元素(索引4)。 提取的文本将被分配到一个名为网站地图_cat.
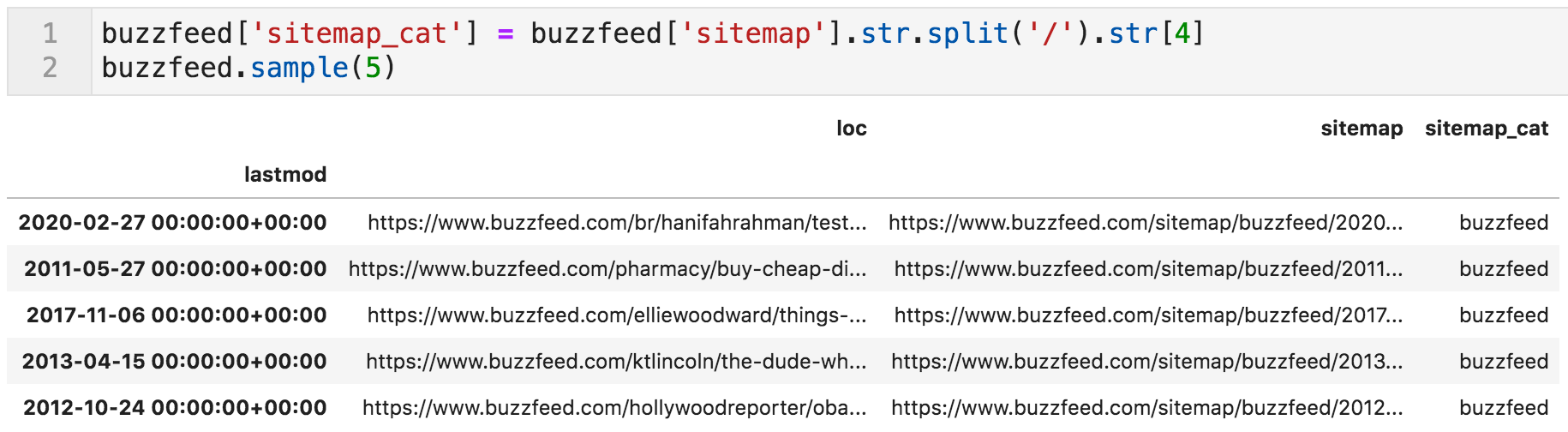 网站地图类别提取并放置在一个新的列"网站地图_cat"
网站地图类别提取并放置在一个新的列"网站地图_cat"
现在我们有了一个显示类别的列,我们可以计算它们有多少个Url,并获得每个Url下的相对内容量的概述。
下面的代码简单地计算该列中的值并格式化生成的DataFrame。
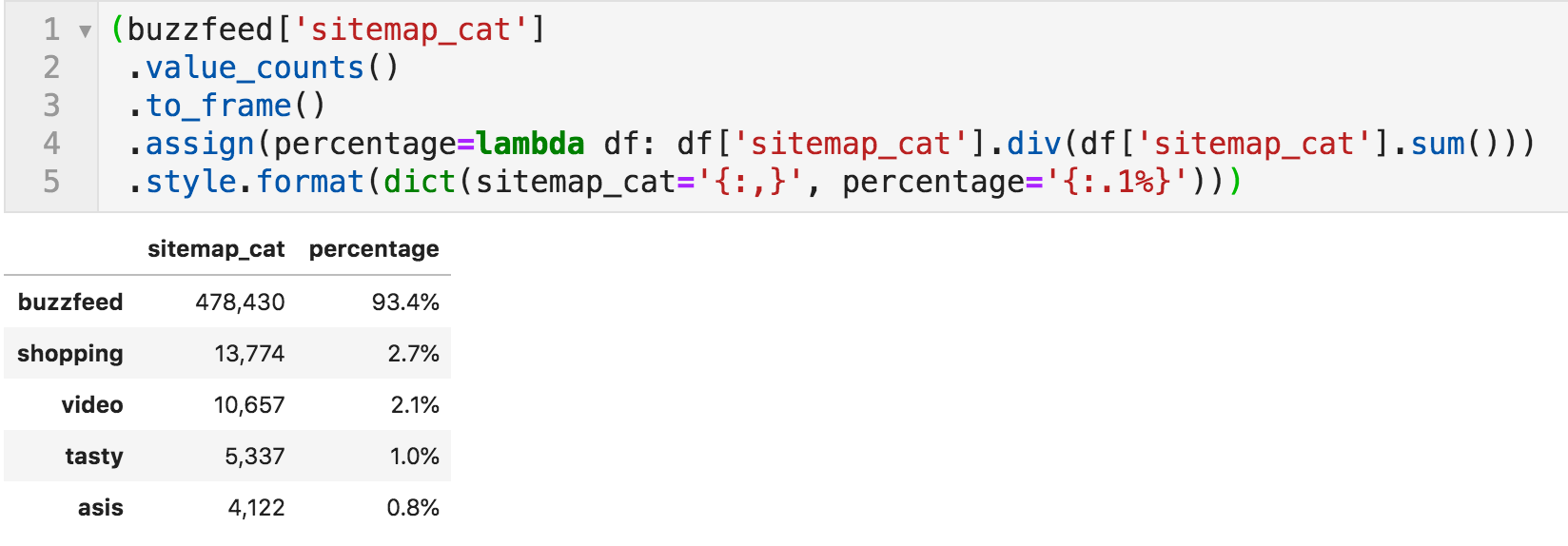 每个类别的文章数目及百分比
每个类别的文章数目及百分比
很明显,"蜂鸣器,蜂鸣器"是主要的类别,基本上是主要的网站,其他的比较起来非常小。
在继续之前,重要的是要更好地理解我们在开始时看到的NaT值。 让我们看看他们属于哪一类。
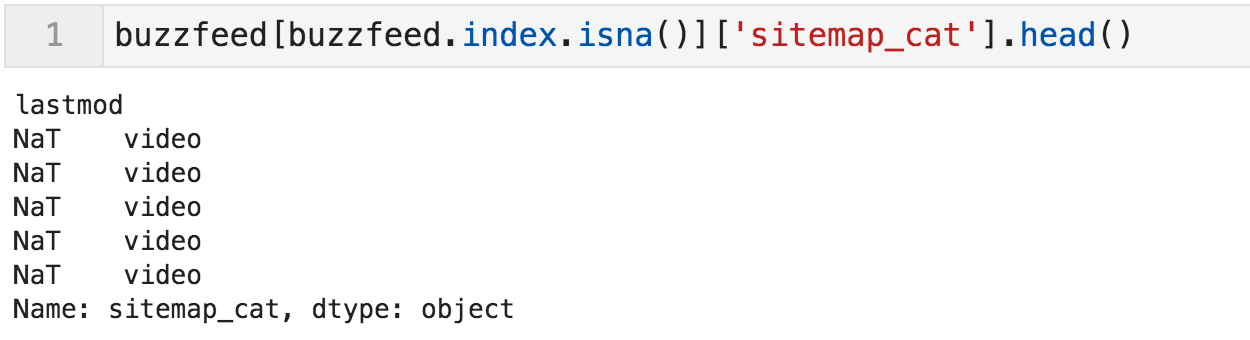 "Lastmod"不可用的类别(前五个)
"Lastmod"不可用的类别(前五个)
前五个属于"视频",但所有缺失值都是如此吗?
以下行采用DataFrame Buzzfeed的子集(索引包含缺失值的子集),然后采用网站地图_cat列,并统计唯一值的个数。 由于我们看到一些值是"视频",如果唯一值的数量是一个,那么缺失日期的所有类别都属于"视频"。
 "Lastmod"不可用的唯一类别数
"Lastmod"不可用的唯一类别数
我们现在发现了数据集中的一个限制,我们知道它会影响2.1%的Url。
但是,我们无法知道它们代表的流量和/或收入的百分比。 我们将无法分析与视频Url日期相关的问题。 我们也无法获得有关这些Url内容的任何信息:
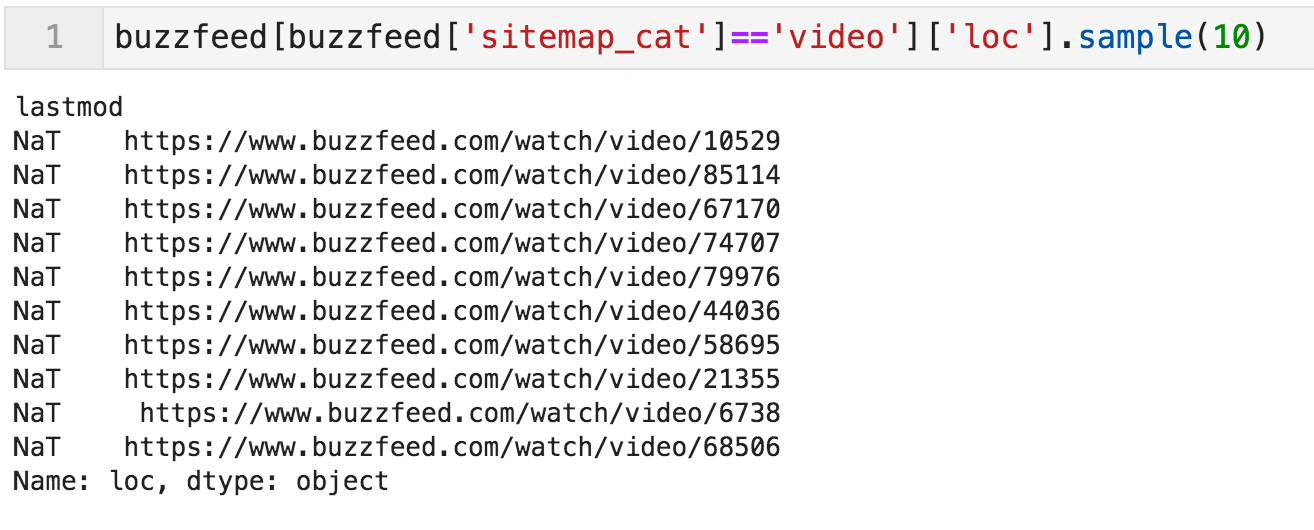 视频Url示例
视频Url示例
出版趋势
现在让我们检查他们每年发布多少篇文章,以及是否有更高/更低的出版年份。
下面的代码通过"a"(对于年度)重新采样DataFrame,并计算每年的行。 如果您更熟悉电子表格,它基本上是一个数据透视表。
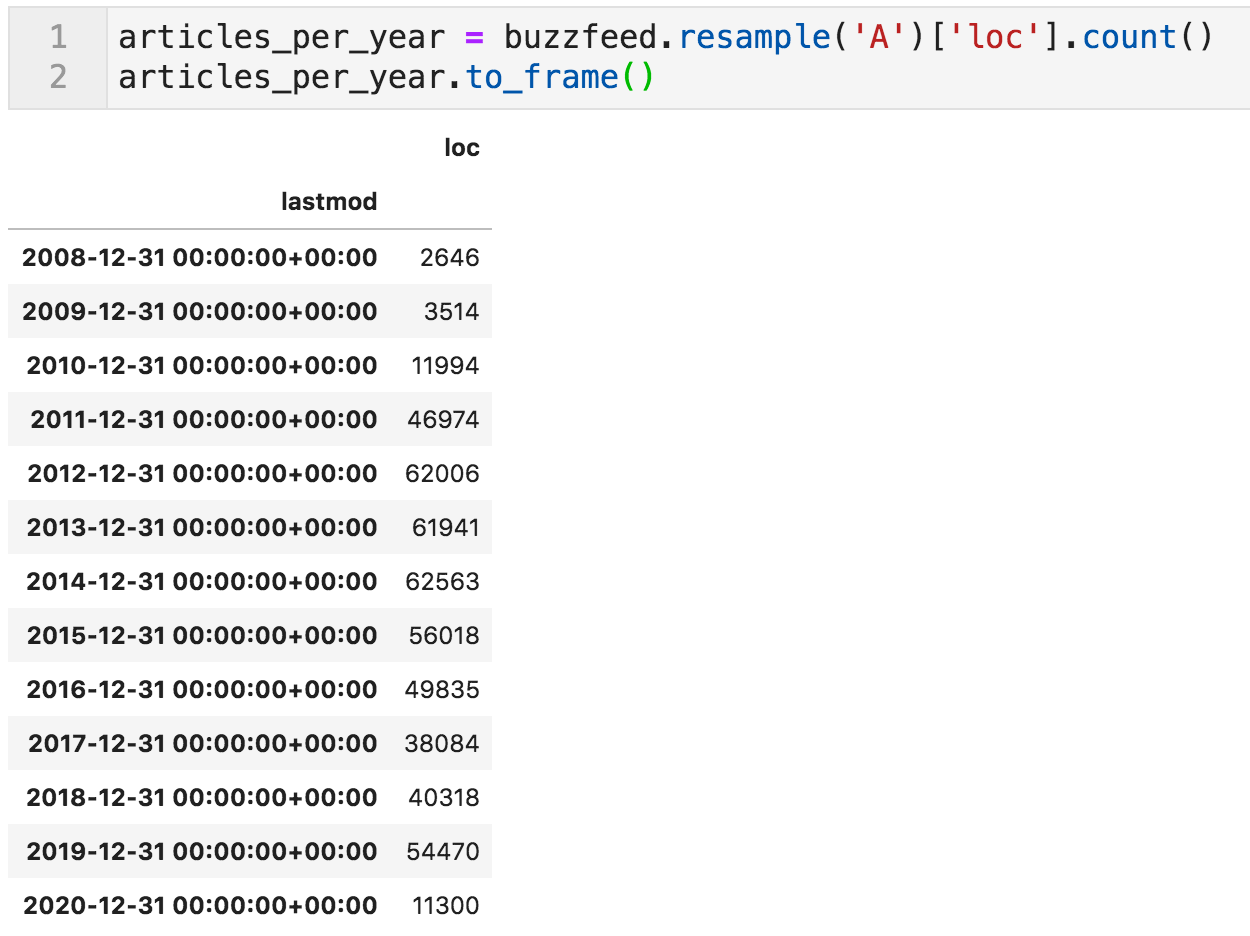 每年文章
每年文章
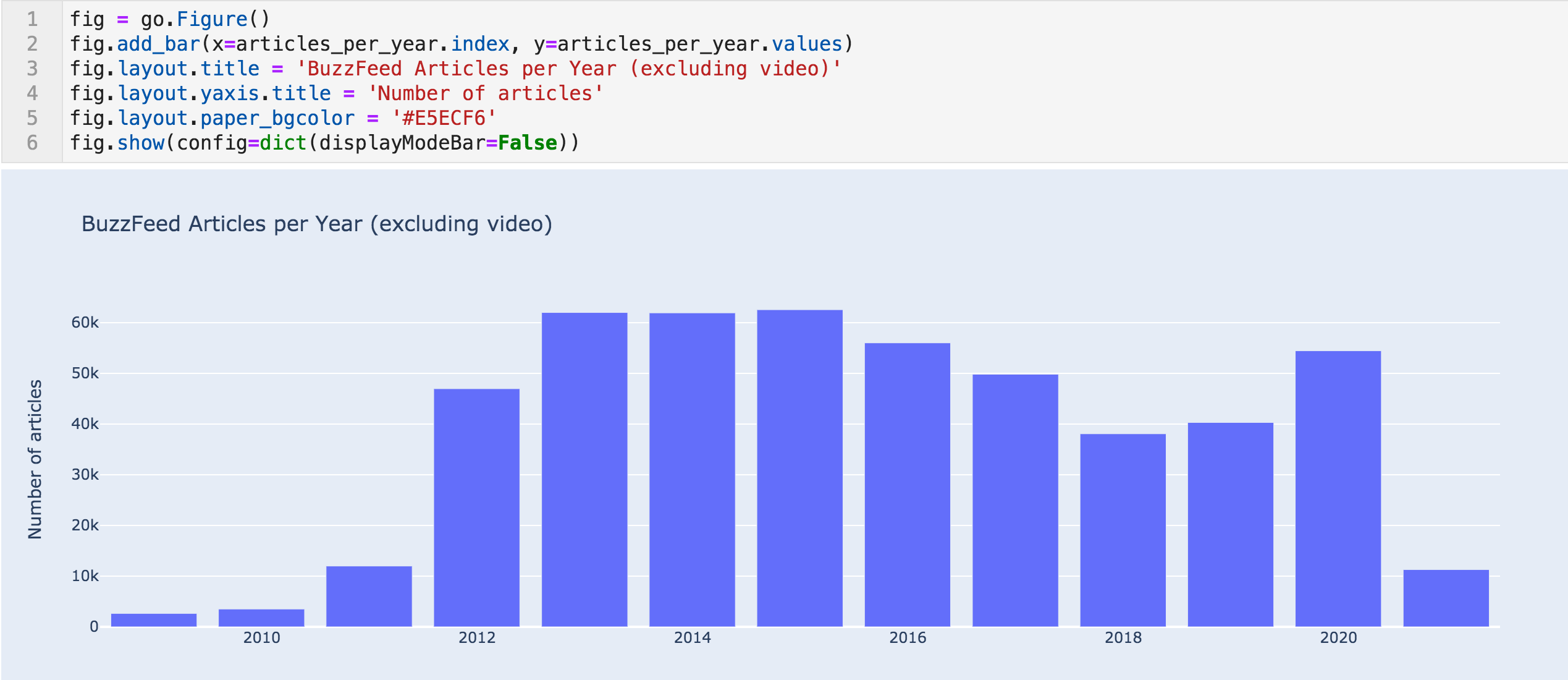 每年文章条形图
每年文章条形图
我们可以看到从2010(3,514)到2011(12k)以及从2011到2012(46k)的文章急剧增加。
这是极不可能的,一个网站可以增加它是出版活动几乎四倍,两次,并在连续两年。 他们可能已经进行了一些收购,内容合作,或者数据集存在问题。
每月趋势
当我们稍后检查作者时,我们会看到这种突然增加的可能答案。 让我们进一步放大,看看月度趋势。
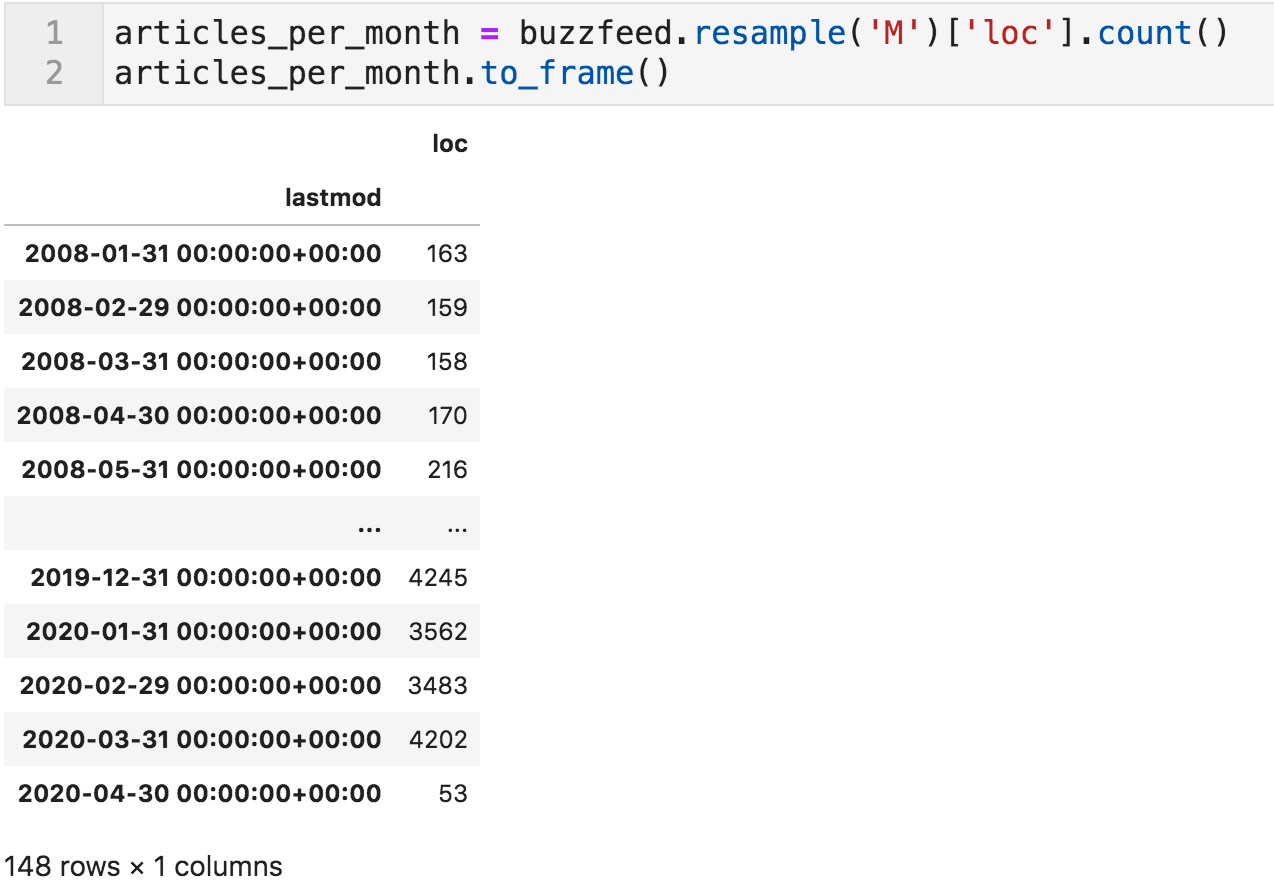 每月文章样本
每月文章样本
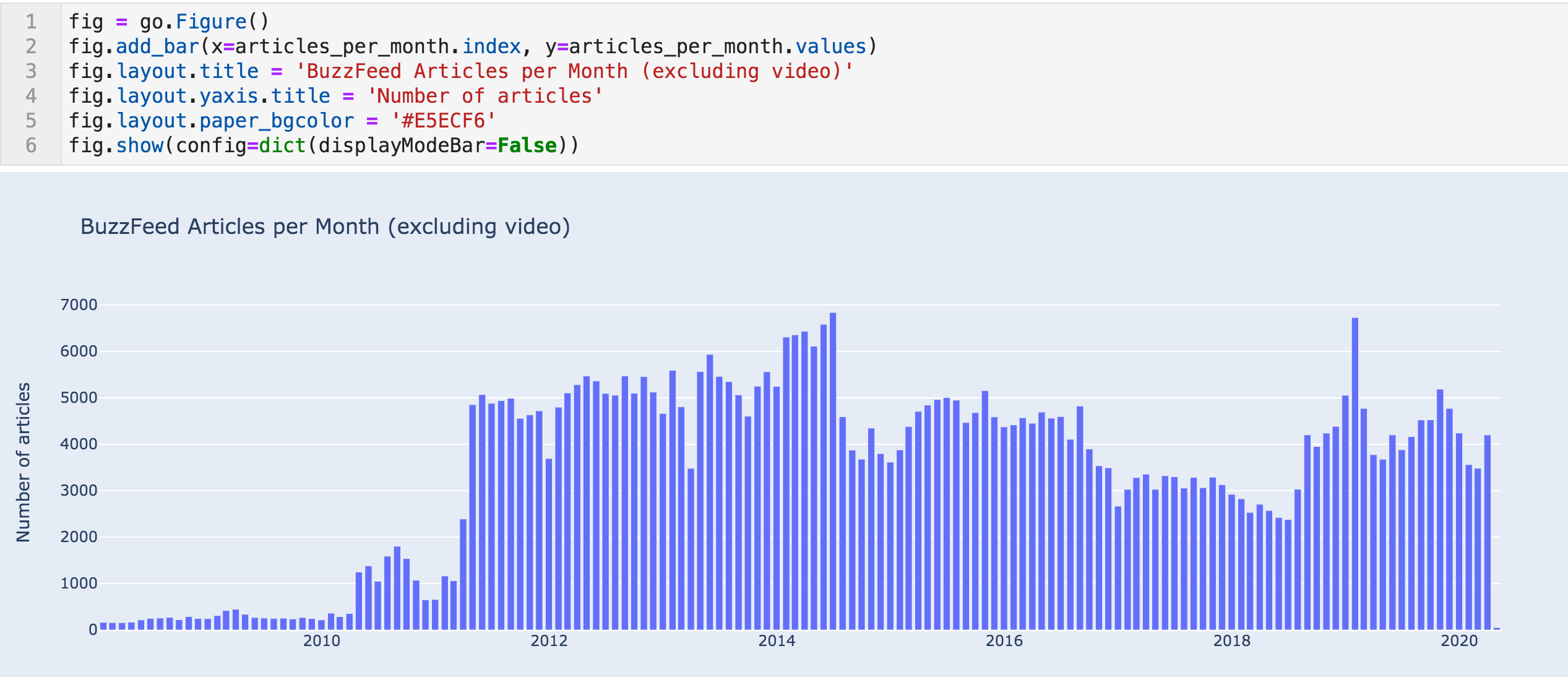 每月文章条形图
每月文章条形图
这些数据证实了上述趋势,并显示出更突然的变化。
2010年4月,他们发表了1,249篇文章,此前上个月发表了354篇文章。 我们可以看到类似的事情发生在2011年4月。 现在几乎可以肯定的是,这不是他们出版活动的自然自然增长。
每周趋势
我们也可以按星期几看一下趋势。
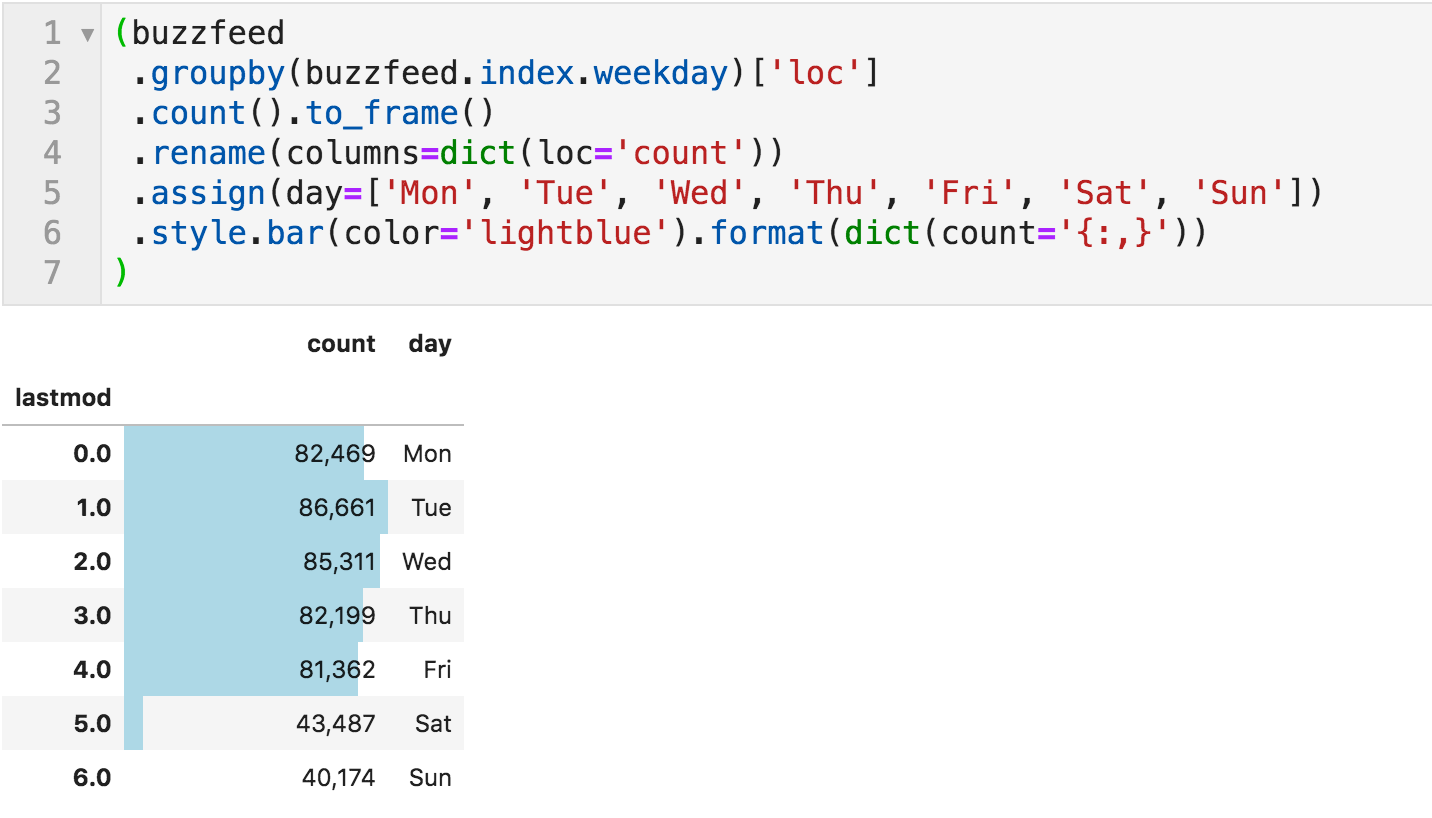 按星期几发表的文章
按星期几发表的文章
这里没什么令人惊讶的。 他们在工作日生产相当一致的文章数量,这几乎是他们在周末生产的两倍。 例如,您可以在不同的时间段内运行此功能,以查看跨年份或月份是否有任何更改。
类别的年度趋势
我们还可以按类别查看年度趋势,看看是否会出现一些东西。 下面的代码遍历所有类别,并为每年的文章数量创建一个图。
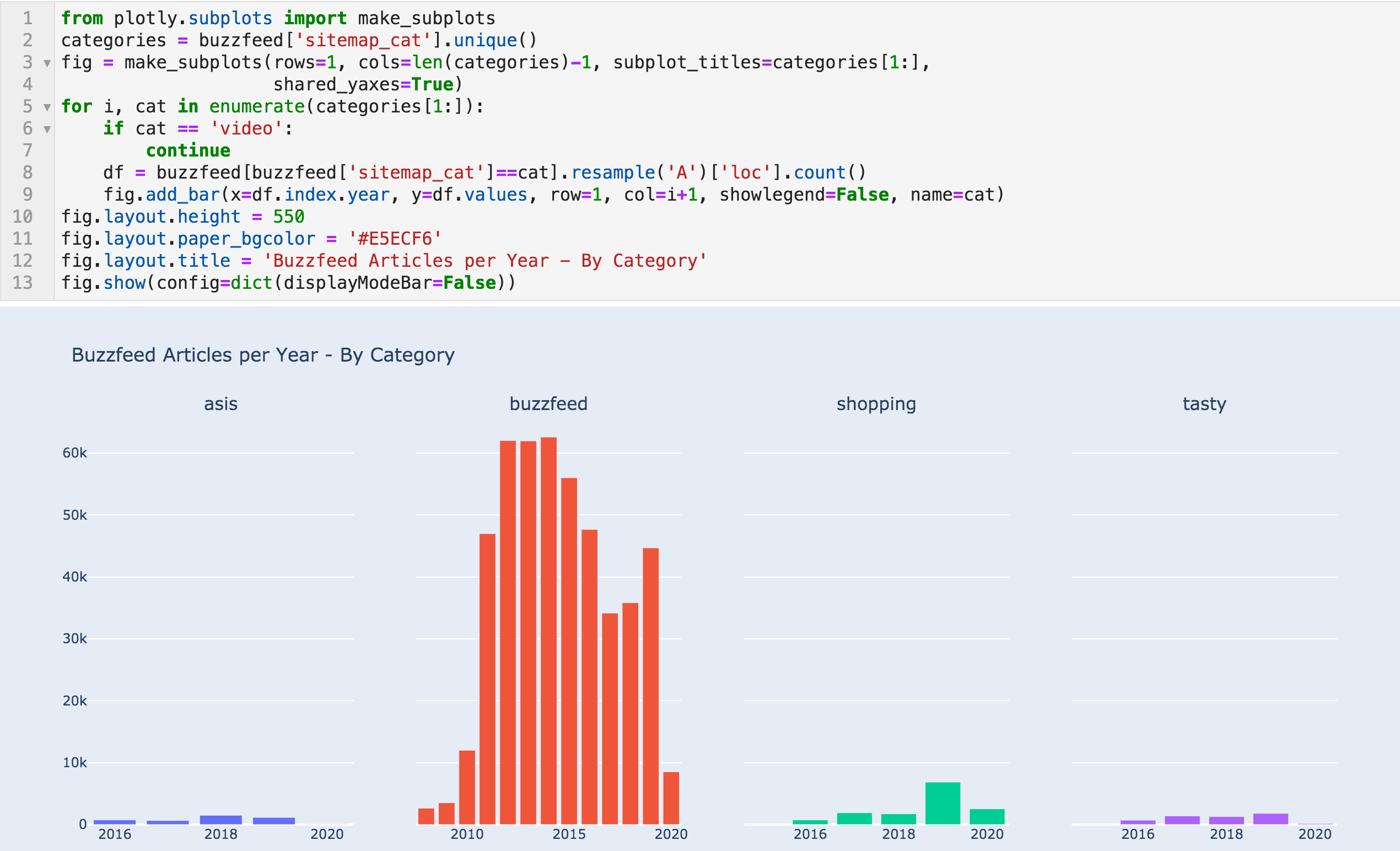 按类别划分的年度文章
按类别划分的年度文章
我可以在这里看到两件事。 首先是2019年"购物"文章从1,732篇跃升至6,845篇,2020年有望达到这一水平。 似乎它对他们来说工作得很好。 检查其中一些文章,您可以看到他们正在运行联盟计划并推广一些产品。
其次是这个图表的误导性. 例如,Tasty最近被BuzzFeed收购,在这里你可以看到它占据了一小部分内容。 但如果你检查他们的Facebook专页,你会看到他们有近一亿的追随者。 因此,请记住这一点,持怀疑态度,并尝试在可能的情况下验证来自其他来源的信息。
URL结构
我们现在可以分析我们可以从Url中获得的任何信息,这里是一个随机样本:
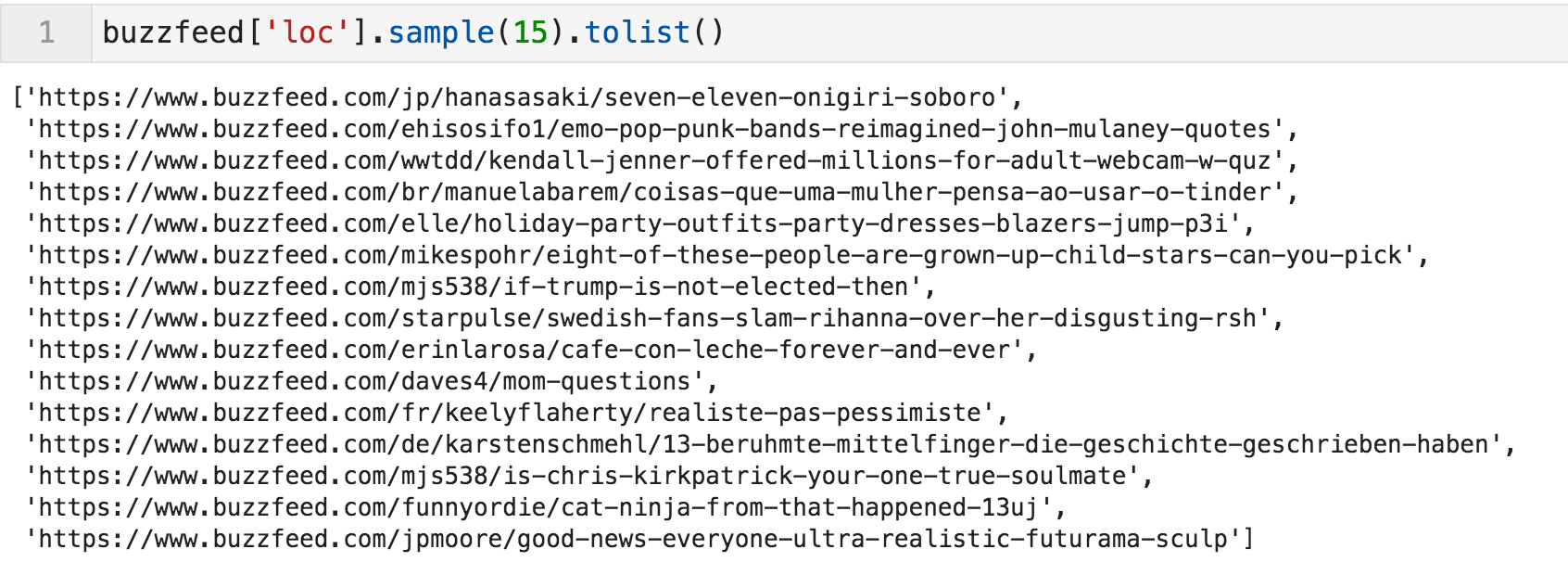 Url的随机样本
Url的随机样本
一般模板似乎在表单中蜂鸣器,蜂鸣器.com/{语言}/{作者}/{文章标题},而英文文章中没有"/en/"。
现在让我们为语言创建一个新列,这可以通过提取两个斜杠之间出现的任何两个字母的模式来完成。 如果没有可用,它将填充"en"。 现在我们可以看到每种语言(或某些情况下的国家/地区)的文章数量。
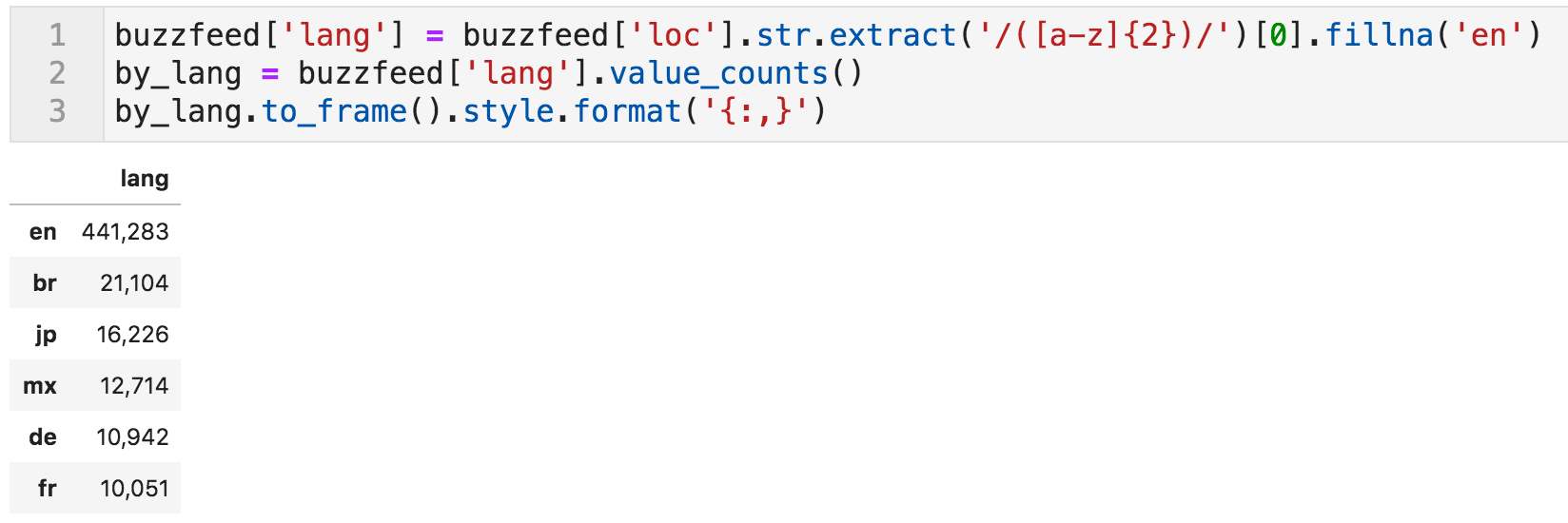 每种语言的文章数量
每种语言的文章数量
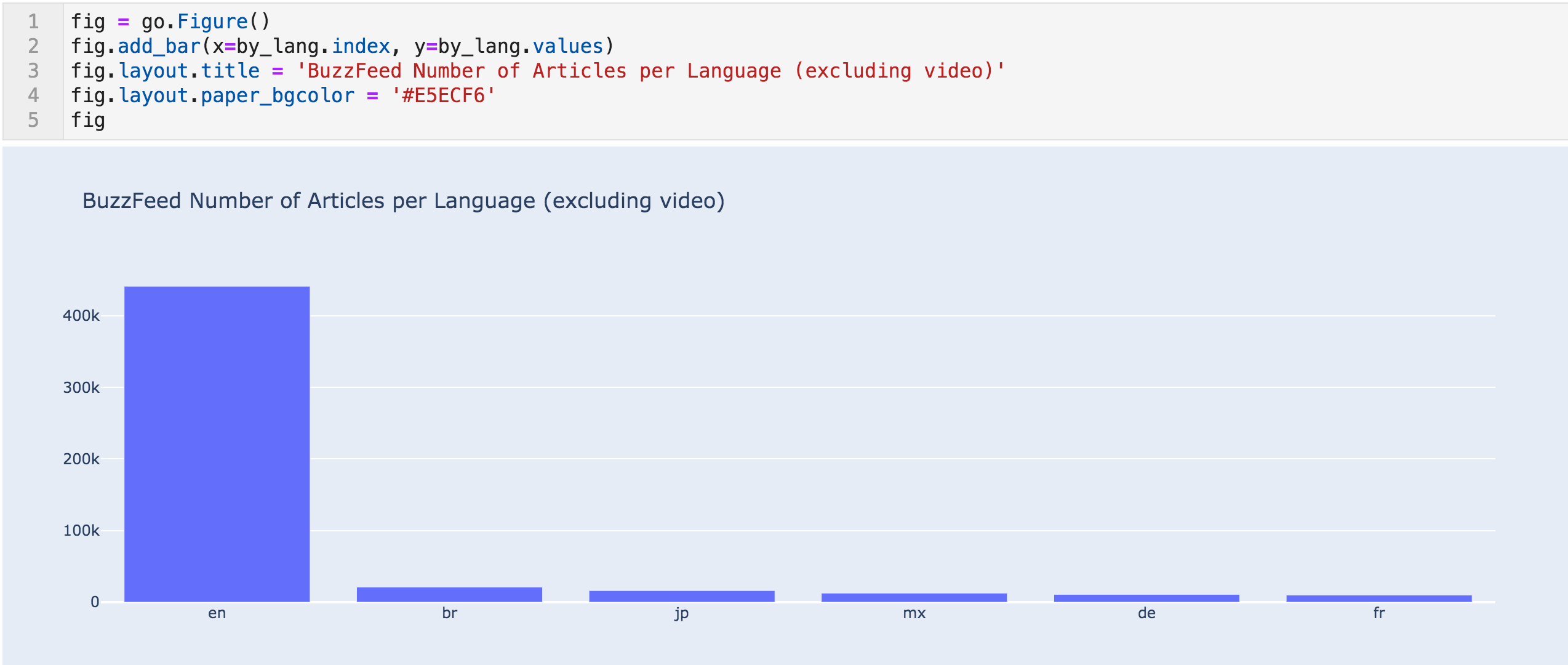 每种语言的文章条形图
每种语言的文章条形图
我们还可以查看每种语言的每月文章数量以获得更好的视图。
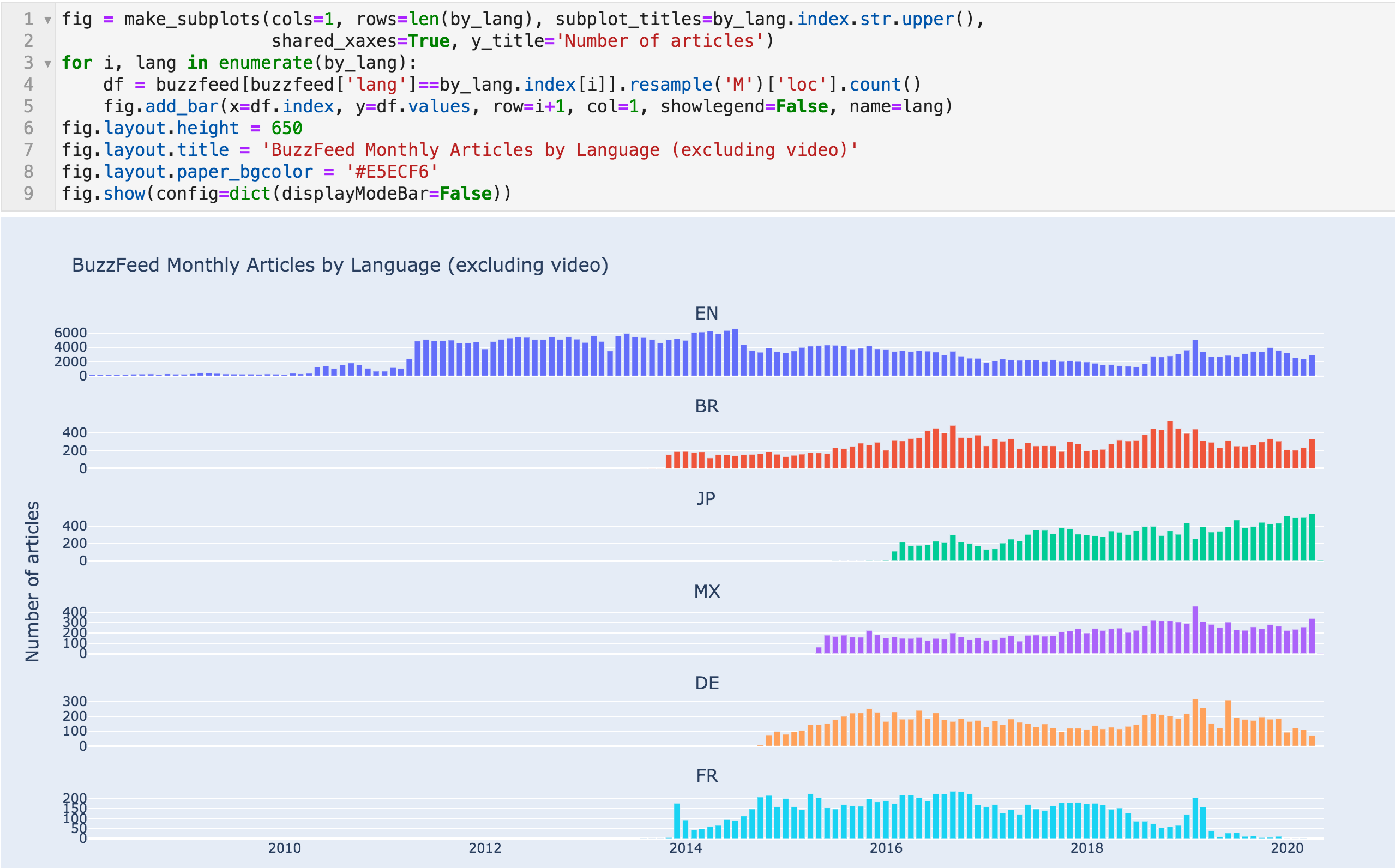 每月文章数目-按语文划分
每月文章数目-按语文划分
提取作者的数据
现在让我们为作者完成相同的过程。 和以前一样,我们通过"/"分割"loc"列并提取第二个到最后一个元素,并将其放置在一个新的"作者"列中。 之后,我们可以按作者统计文章。
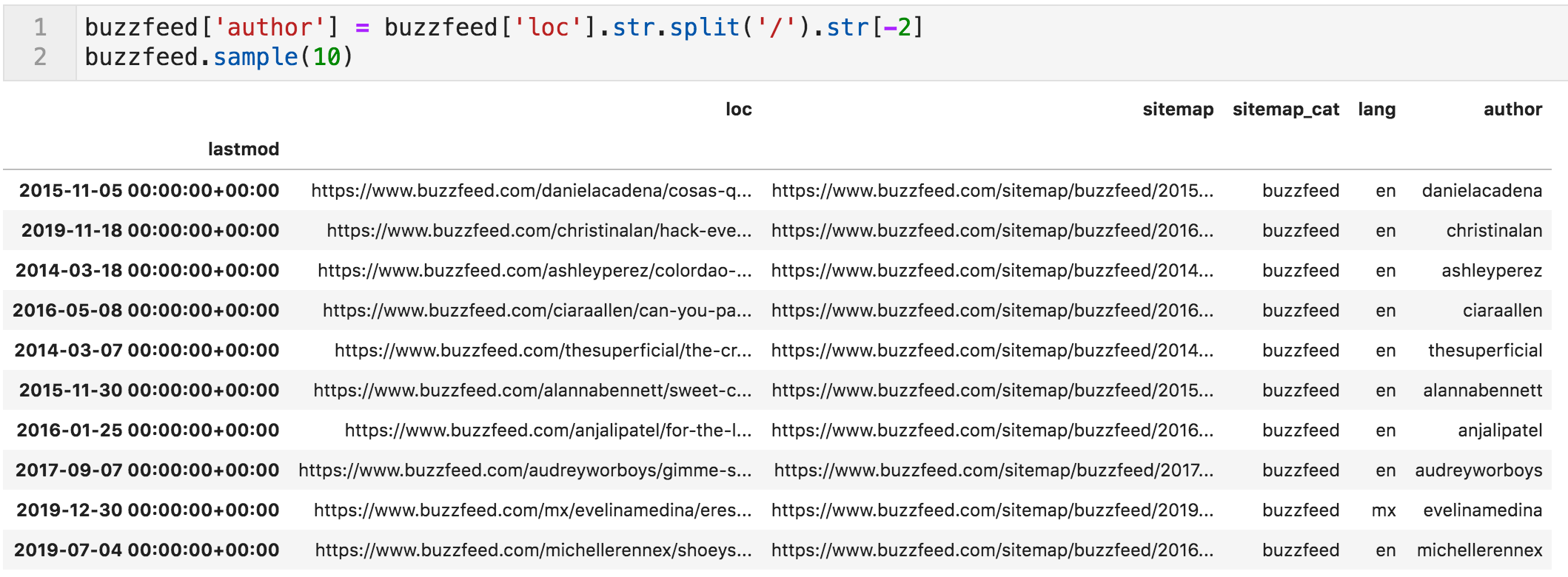 新栏目新增"作者"
新栏目新增"作者"
 计算和格式化每个作者的文章数量的代码
计算和格式化每个作者的文章数量的代码
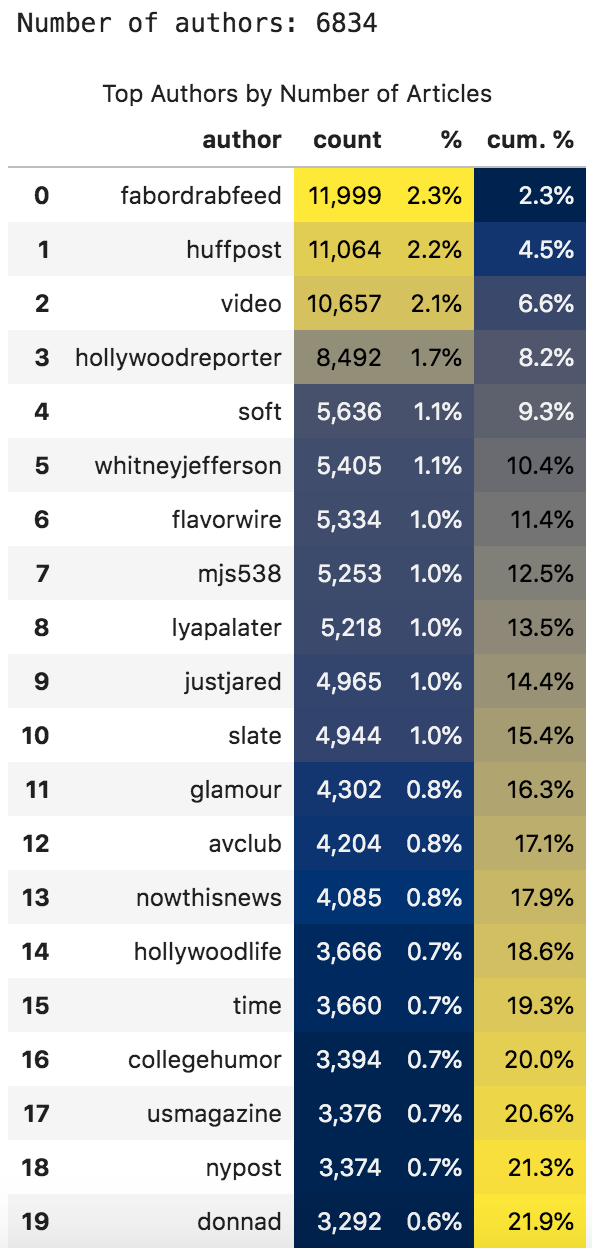 每位作者的文章数量(所有时间)
每位作者的文章数量(所有时间)
"暨。 %"显示作者到当前行为止的文章数量的累积百分比。
例如,前三位作者产生了总文章的6.6%(当然,"视频"不是作者,所以我们会忽略它)。 您还可以看到一些顶级作者实际上是其他新闻机构而不是人。
我通过"huffpost"手动检查了几篇文章,并得到了404错误。 下面的代码片段通过一个随机的url样本,其中作者是"huffpost",并打印URL和响应。
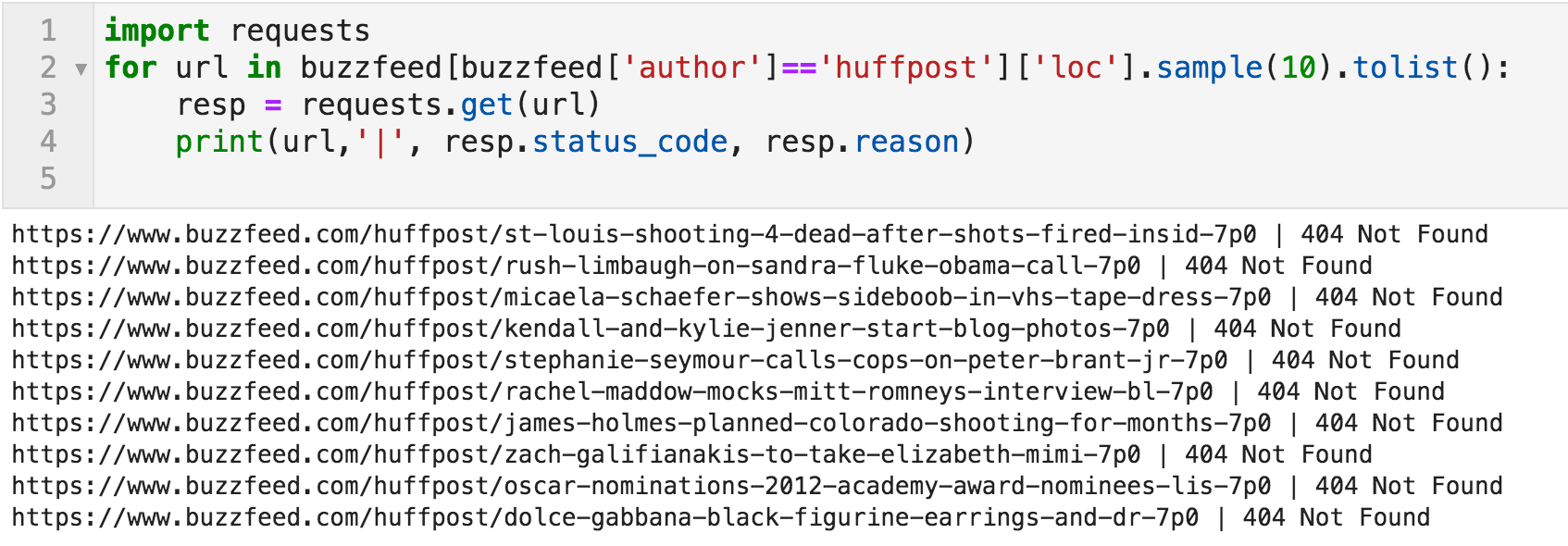 Url及其响应的随机样本
Url及其响应的随机样本
这是数据集中的另一个问题。
顶级贡献者的文章已经不存在了。 我没有检查它们,正确的方法是通过所有50万个Url来量化这个问题。
大型新闻机构存在如此大量的文章可能是BuzzFeed上内容量突然增加的问题的答案。
在你的站点地图中有404绝对是一个问题,但在我们的例子中,他们没有删除它们是很棒的,因为我们对网站的历史有更好的了解,即使很多Url已经不存在了。 这也意味着可能还有其他不存在的Url被删除,我们不知道。我说过怀疑吗?
有了这么大的网站,你可以期待一些问题,特别是回到七八年前,许多事情发生了变化,许多事情不再相关。 因此,让我们在最近的一段时间,即2019年和2020年(第一季度)做同样的练习。
 计算2019-2020年第一季每位作者文章的代码
计算2019-2020年第一季每位作者文章的代码
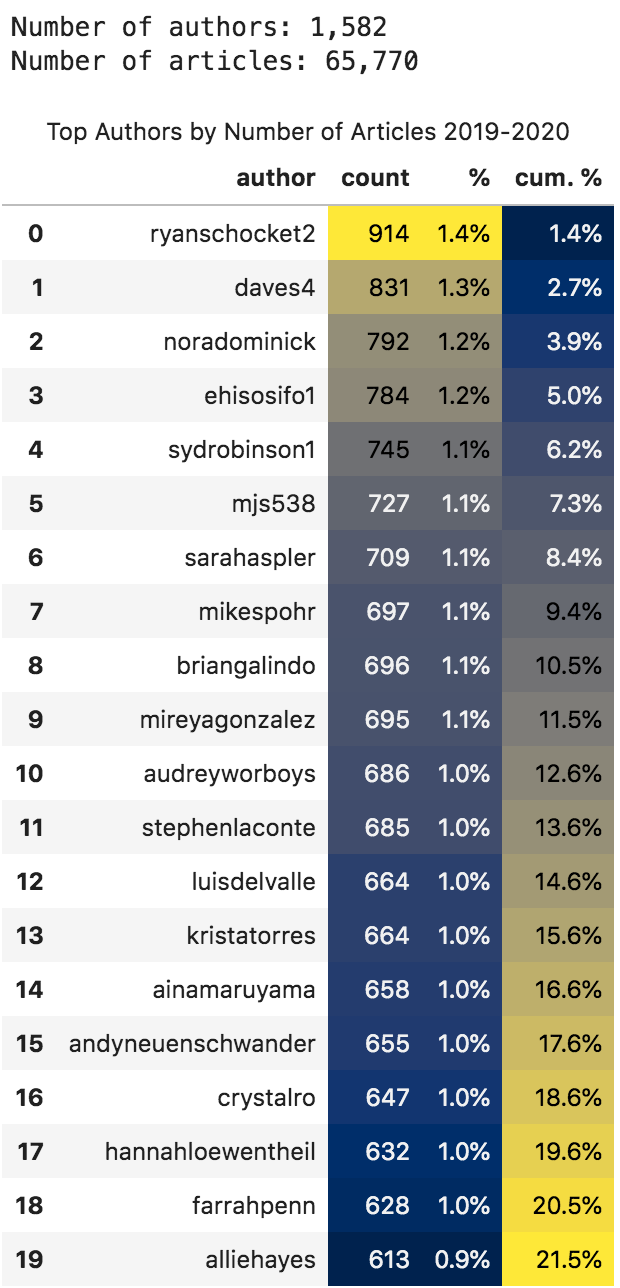 按2019-2020年第一季文章数量划分的主要作者
按2019-2020年第一季文章数量划分的主要作者
现在所有的顶级作者似乎都是人而不是组织。
我们还可以看到,前二十名在这一时期产生了21.5%的内容。 我们可以看到每个作者制作了多少篇文章,以及这个数字在这段时间的文章总数中所占的百分比。
如果你想知道每个月有多少篇文章,每个作者都写了:
 每个作者生成每月文章的代码
每个作者生成每月文章的代码
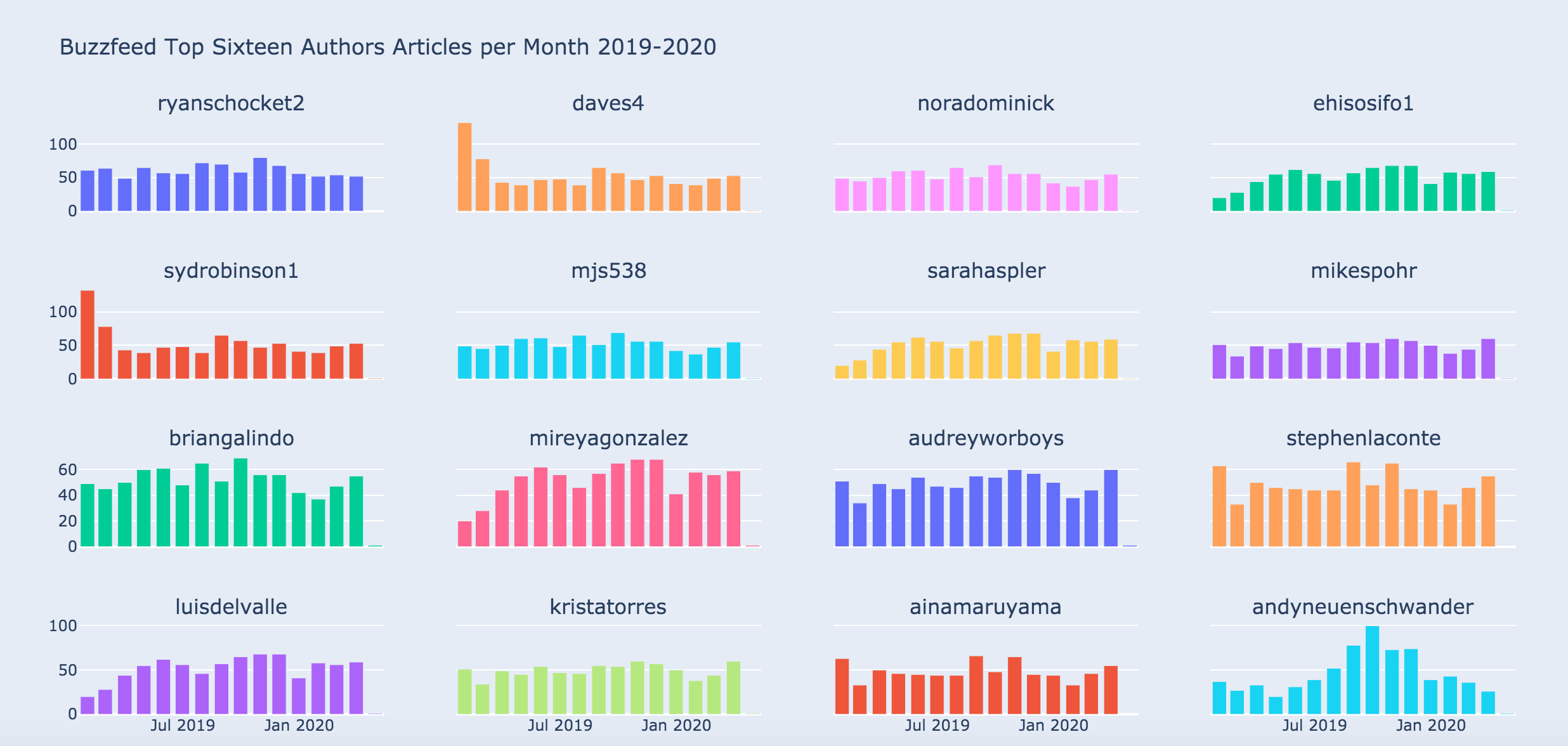 作者每月文章
作者每月文章
自上而下的方法
以上是一种探索性的方法,我们对作者一无所知。 现在我们知道了一点,我们可以使用自上而下的方法。
以下函数采用任意数量的作者名称,并绘制每个作者的每月文章数量,因此您可以比较任何两个或更多作者。 所以让我们从顶级新闻机构开始。
 功能绘制和比较作者的出版活动(每月文章)
功能绘制和比较作者的出版活动(每月文章)
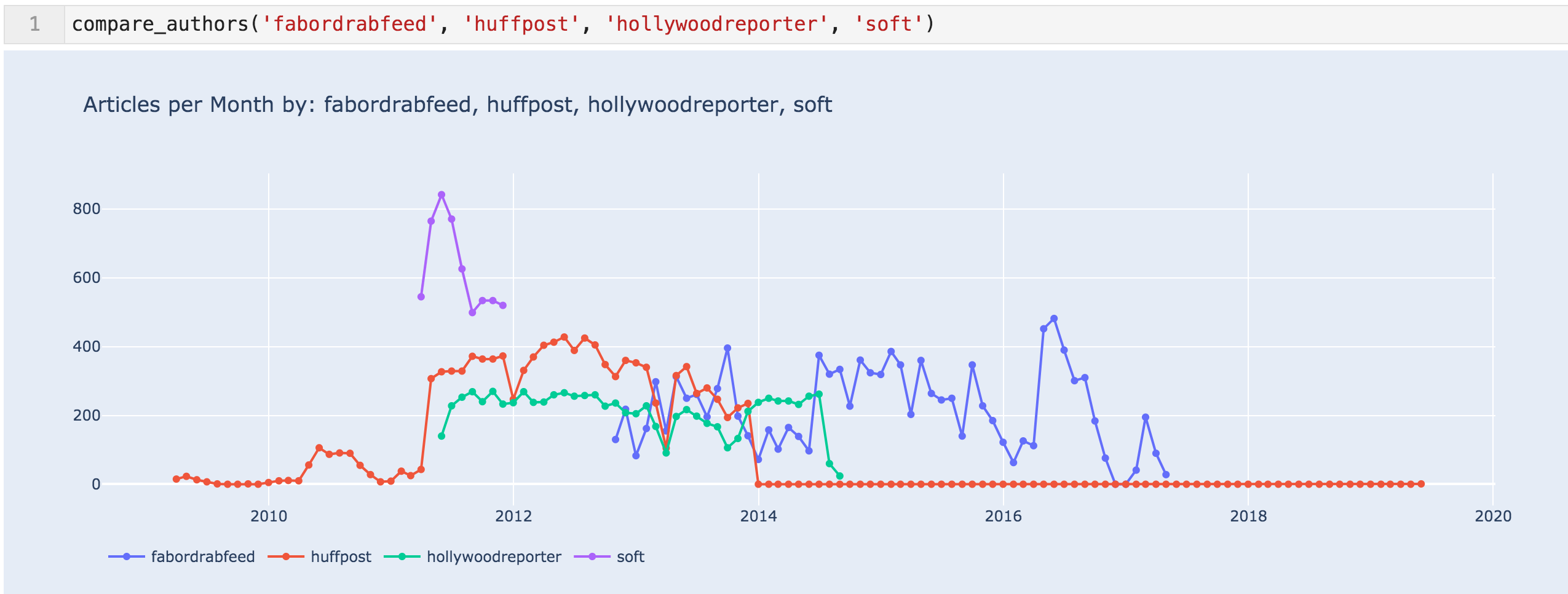 "Fabordrabfeed"、"huffpost"、"hollywoodreporter"及"soft"每月文章
"Fabordrabfeed"、"huffpost"、"hollywoodreporter"及"soft"每月文章
有了所有数据,2011年4月文章的跳跃似乎更有可能是由于内容合作伙伴关系。 我们还可以看到,与HuffingtonPost的合作关系在2013年11月结束,至少根据网站地图。
以下是过去五个季度前三位作者的趋势。
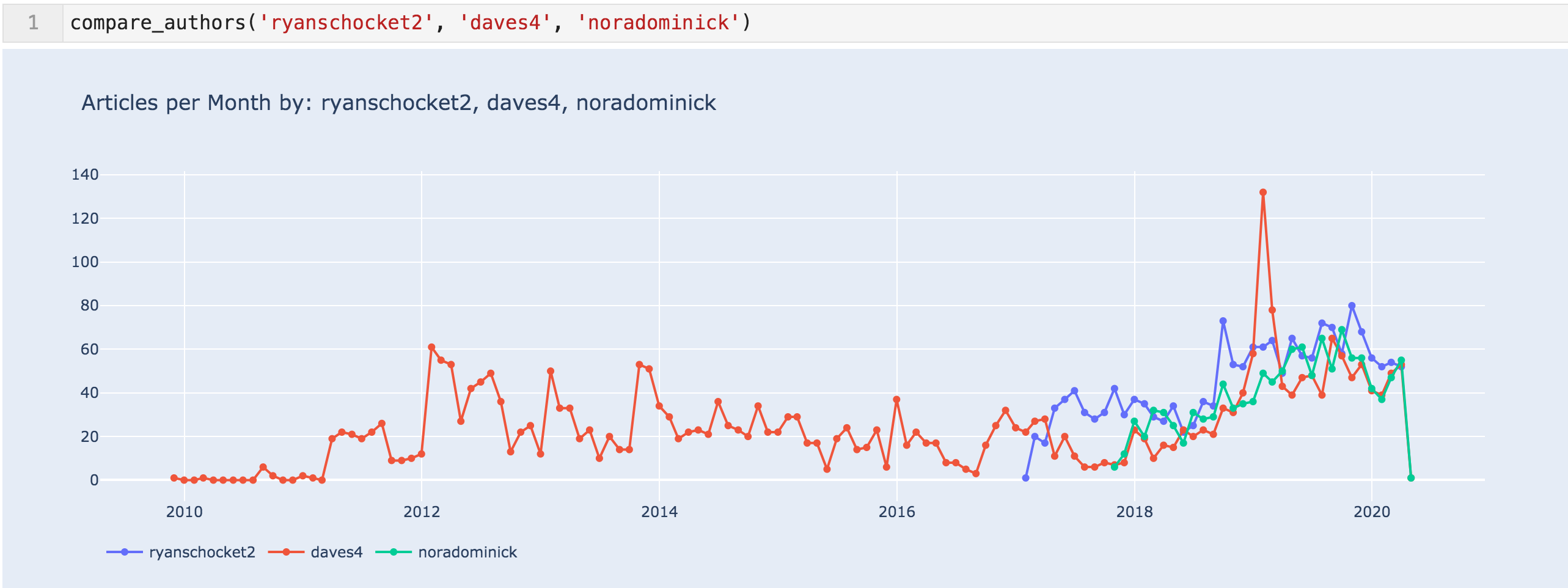 "Ryanschocket2"、"daves4"及"noradominick"每月文章
"Ryanschocket2"、"daves4"及"noradominick"每月文章
内容分析
我们现在进入URL的最后一部分-包含文章标题的slug。 到目前为止,一切基本上都是通过按日期,类别,语言和作者对内容进行分类来创建元数据。
Slu也可以使用相同的方法提取到自己的列中。 我还用空格替换了破折号,以便更轻松地拆分和分析。
 新专栏增加了"slu"
新专栏增加了"slu"
为了看看slu,我创建了一个子集,其中只包含英文文章。
 文章蛞蝓的随机样本
文章蛞蝓的随机样本
'Word_frequency'函数
最简单的做法是数数蛞蝓中的单词。 该word_频率函数为我们做了这件事。
请注意,此功能在默认情况下删除停用词,这是可用的是一组探索。 在许多情况下,您可能想要编辑此列表,因为在某个上下文中可能是停用词的内容不在另一个上下文中。
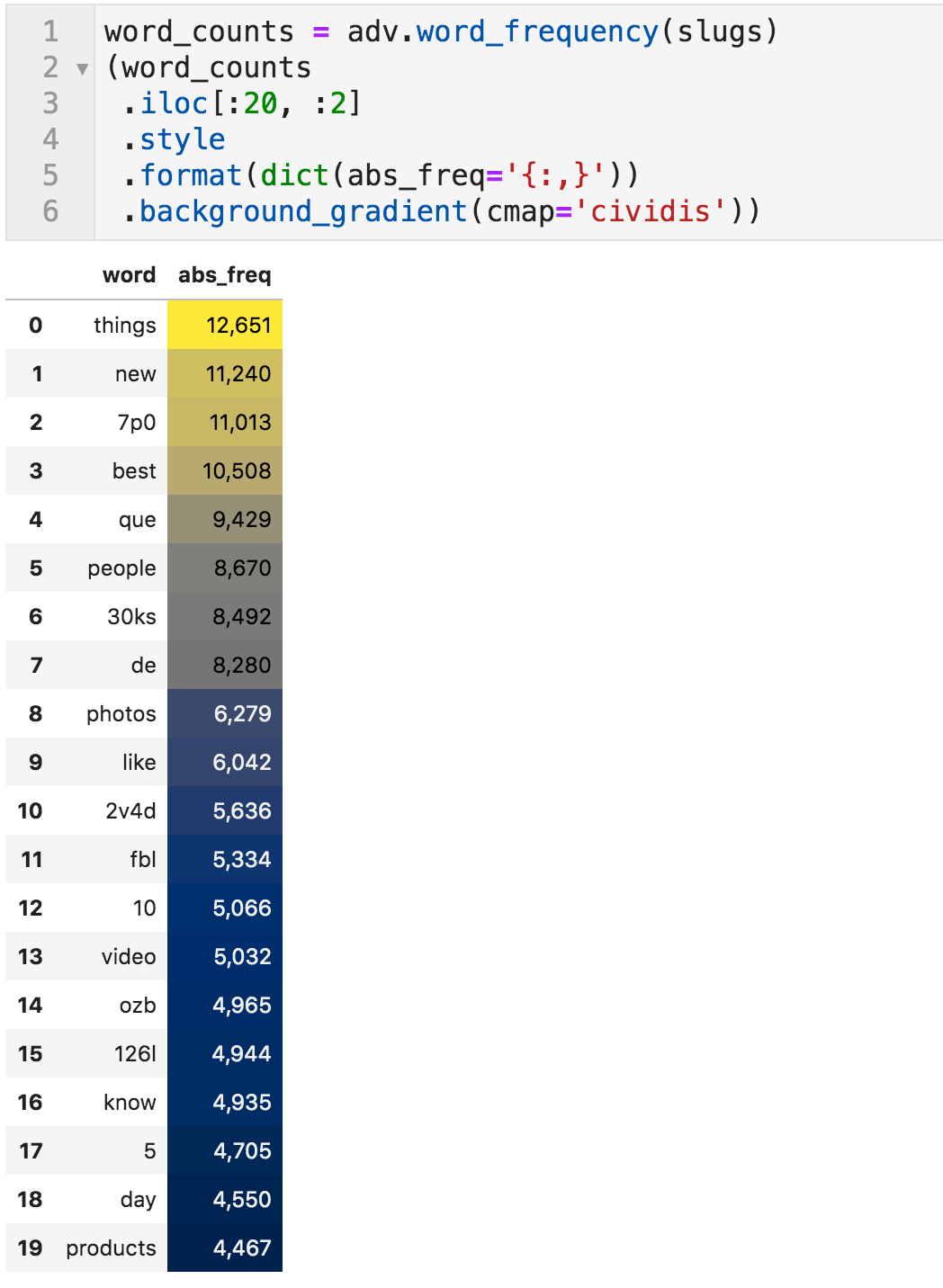 文章标题中最常用的词
文章标题中最常用的词
如果一个词没有传达太多信息,我们可以指定phrase_length值为2来计算两个单词的短语(令牌是另一个名称)。
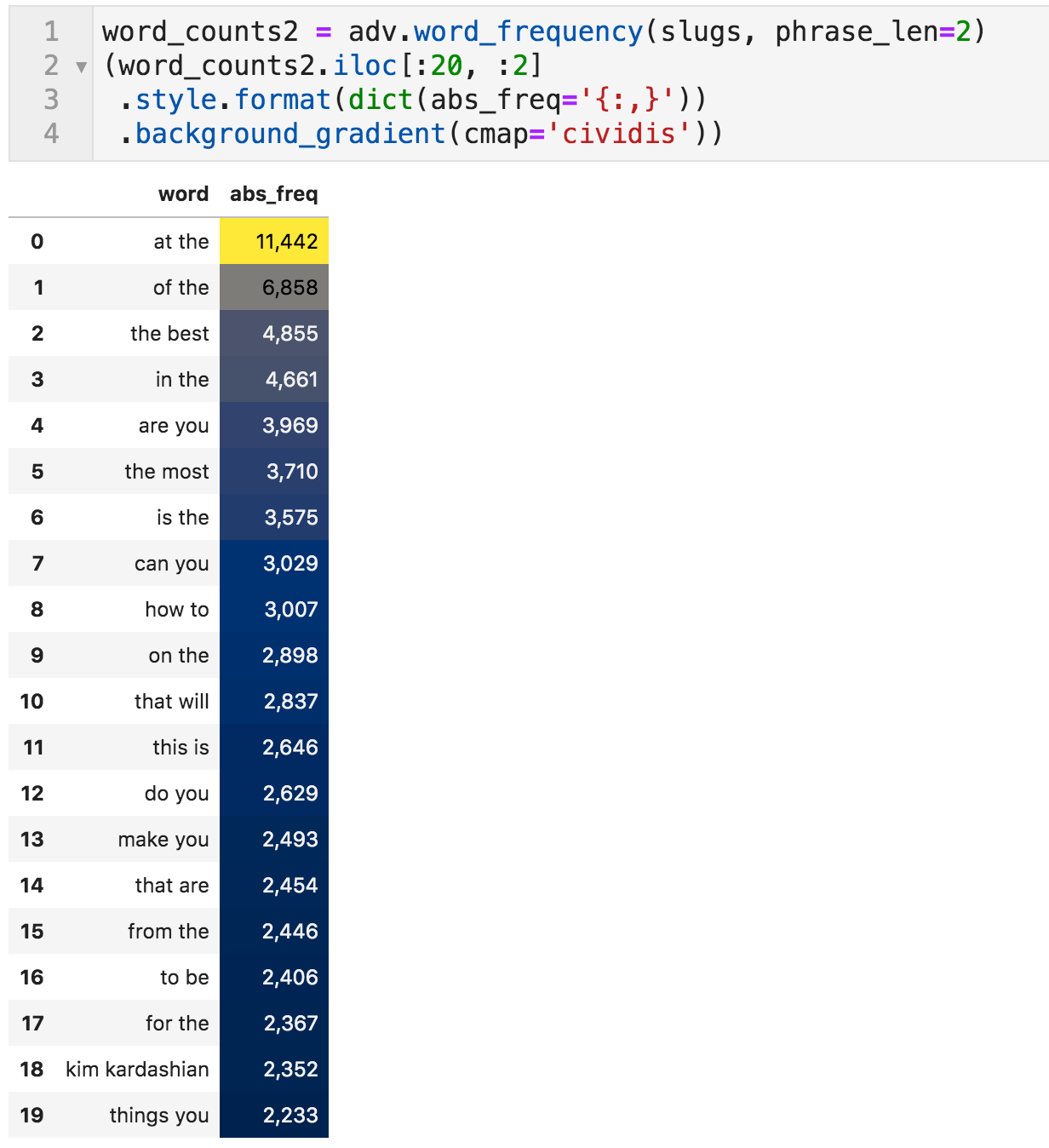 最常用的两个单词短语
最常用的两个单词短语
要分析的主题
就像我们比较了作者一样,我们可以使用相同的方法,为单词创建一个类似的函数,这些函数将作为要分析的主题。
 功能来比较跨时间选择的单词的外观
功能来比较跨时间选择的单词的外观
这是名人最常出现的三个名字,"测验"似乎也很受欢迎,所以我将它们相互比较。
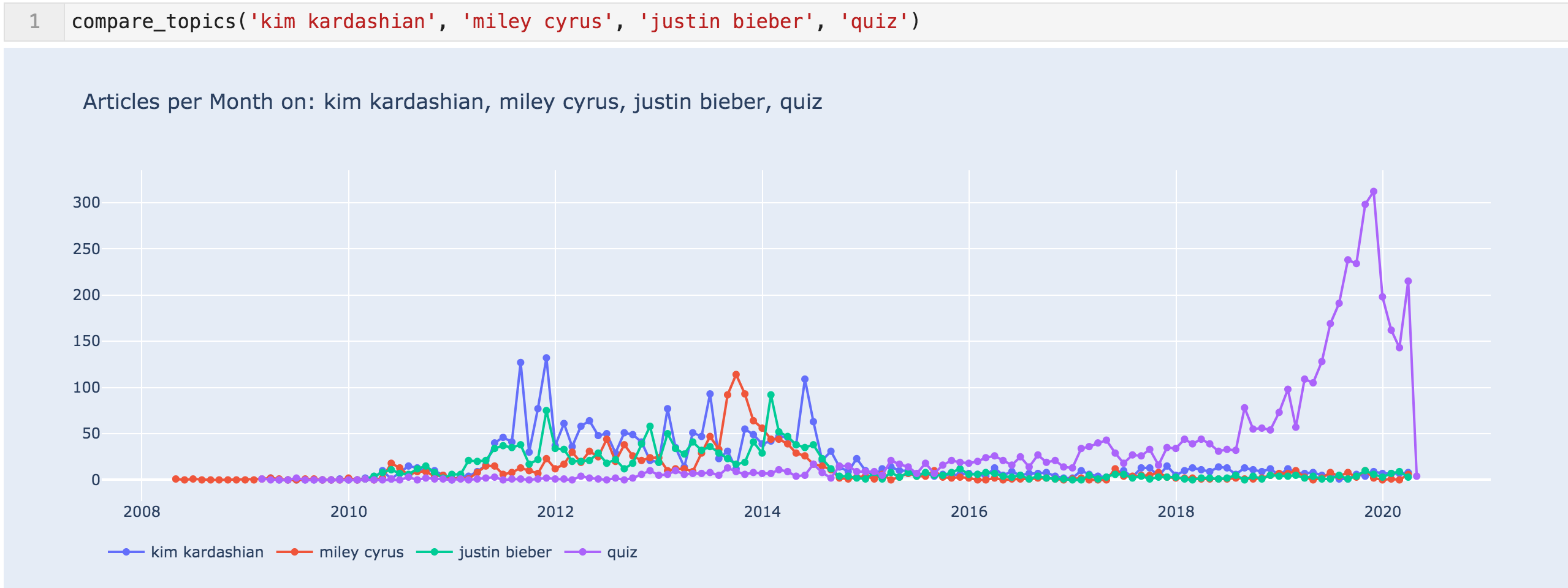 每月为"金*卡戴珊"、"麦莉*赛勒斯"、"贾斯汀*比伯"和"测验"撰写文章
每月为"金*卡戴珊"、"麦莉*赛勒斯"、"贾斯汀*比伯"和"测验"撰写文章
这些数据表明,可能HuffingtonPost和其他人发布的内容是名人重。 它还显示了测验的流行程度,以及它们对测验的关注程度。
这就提出了这些测验是关于什么的问题。 要做到这一点,我们可以采取slu的一个子集,其中存在"测验"一词,并仅计算这些slu中的单词。 这样,我们就可以知道他们在测验中使用了什么主题。
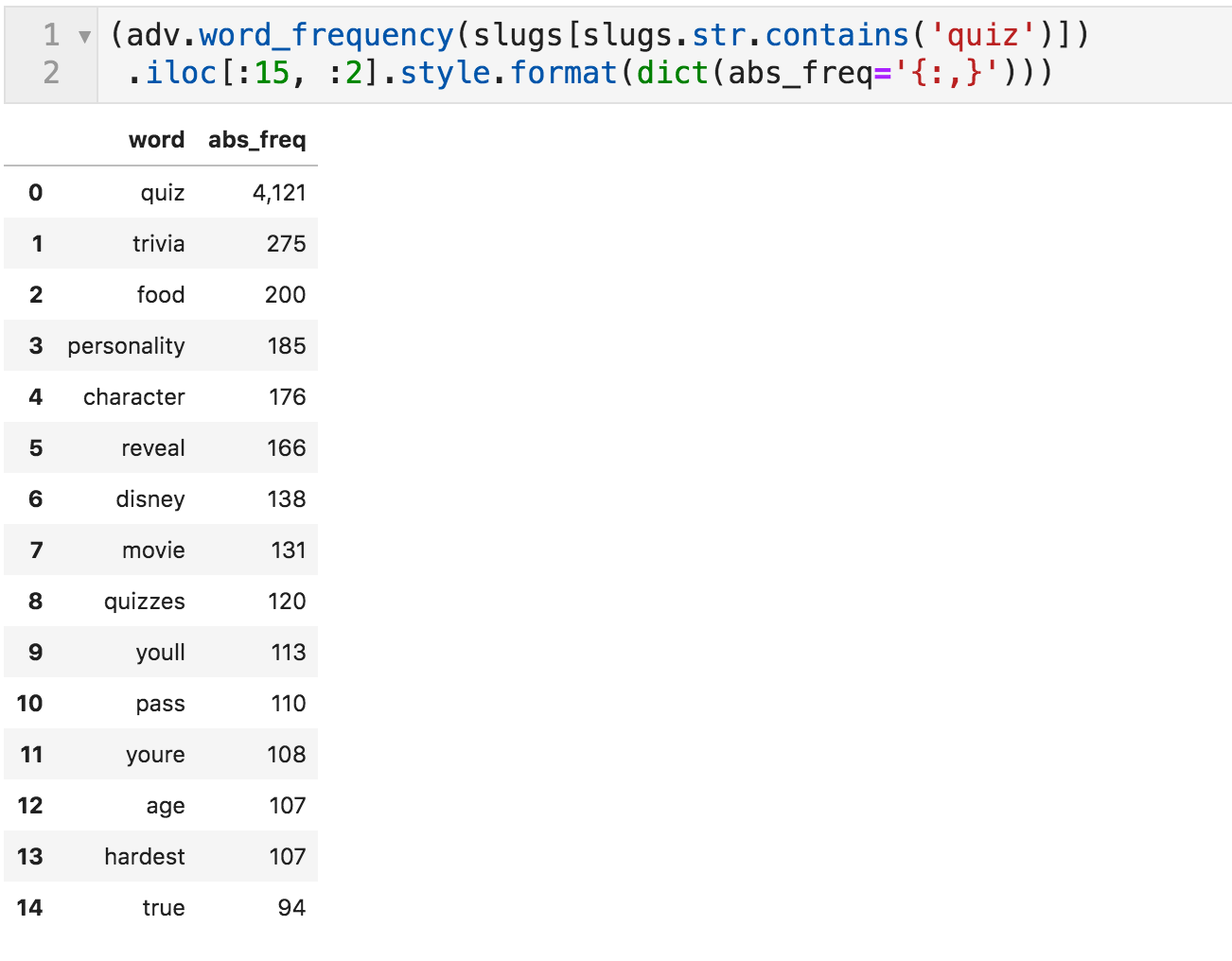 最常出现"测验"的单词
最常出现"测验"的单词
现在,你可以开始分析了!
摘要
我们现在对数据集的大小和结构有了一个很好的概述,并且在数据中发现了一些问题。 为了更好地构建它,我们创建了一些列,以便我们可以更轻松地按语言,类别,作者,日期以及文章标题进行聚合。
显然,您无法单独通过网站地图获得网站的完整视图,但它们提供了一种非常快速的方式来获取有关发布活动和内容的大量信息,如上所述。 我们处理"lastmod"的方式非常标准(许多网站还提供发布时间,而不仅仅是日期),但每个网站的Url都不同。
在做好准备并熟悉您可能面临的一些可能的陷阱之后,您现在可以开始对内容进行适当的分析。 您可能想要探索的一些想法:主题建模,单词共现,实体提取,文档聚类,以及针对不同的时间范围和我们创建的任何其他可用参数执行这些操作。