

 外贸B2B建站
外贸B2B建站  高端定制设计
高端定制设计  系统功能优势
系统功能优势 


 Google SEO优化
Google SEO优化  Google SEM广告
Google SEM广告  网站内容营销
网站内容营销  优化案例
优化案例  设计赏析
设计赏析  搜索引擎优化
搜索引擎优化  付费广告
付费广告  社媒运营
社媒运营  公司介绍
公司介绍  渠道共赢
渠道共赢  联系我们
联系我们 有没有花几个小时分析谷歌搜索结果,最终比以前更沮丧和困惑?
Python没有。
在本文中,我们将探讨为什么Python是Google搜索分析的理想选择,以及它如何简化和自动化原本耗时的任务。
我们还将从头到尾在Python中执行SEO分析。 并提供代码供您复制和使用。
但首先,一些背景。
为什么使用Python进行Google搜索和分析
Python被称为一种多功能,易于学习的编程语言。 它在处理Google搜索数据方面非常出色。
为啥?
以下是一些关键原因,指出Python是抓取和分析Google搜索结果的首选:
Python易于阅读和使用
Python的设计考虑了简单性。 因此,您可以专注于分析Google搜索结果,而不是纠结于复杂的编码语法。
它遵循易于掌握的语法和风格。 与其他语言相比,它允许开发人员编写更少的代码行。
Python拥有装备精良的库
Python库是开发人员创建的可重用代码块,您可以在脚本中引用这些代码来提供额外的功能,而无需从头开始编写。
Python现在拥有丰富的库,如:
- Googlesearch,请求和美丽的汤为web刮
- 用于数据分析的Pandas和Matplotlib
这些库是强大的工具,可以有效地抓取和分析来自Google搜索的数据。
Python提供来自大型社区和ChatGPT的支持
您将在您承担的任何Python项目中得到很好的支持,包括Google搜索分析。
因为Python的流行导致了一个庞大的、活跃的开发者社区。 和丰富的教程,论坛,指南和第三方工具。
当您无法为搜索分析项目找到预先存在的Python代码时,ChatGPT很可能会提供帮助。
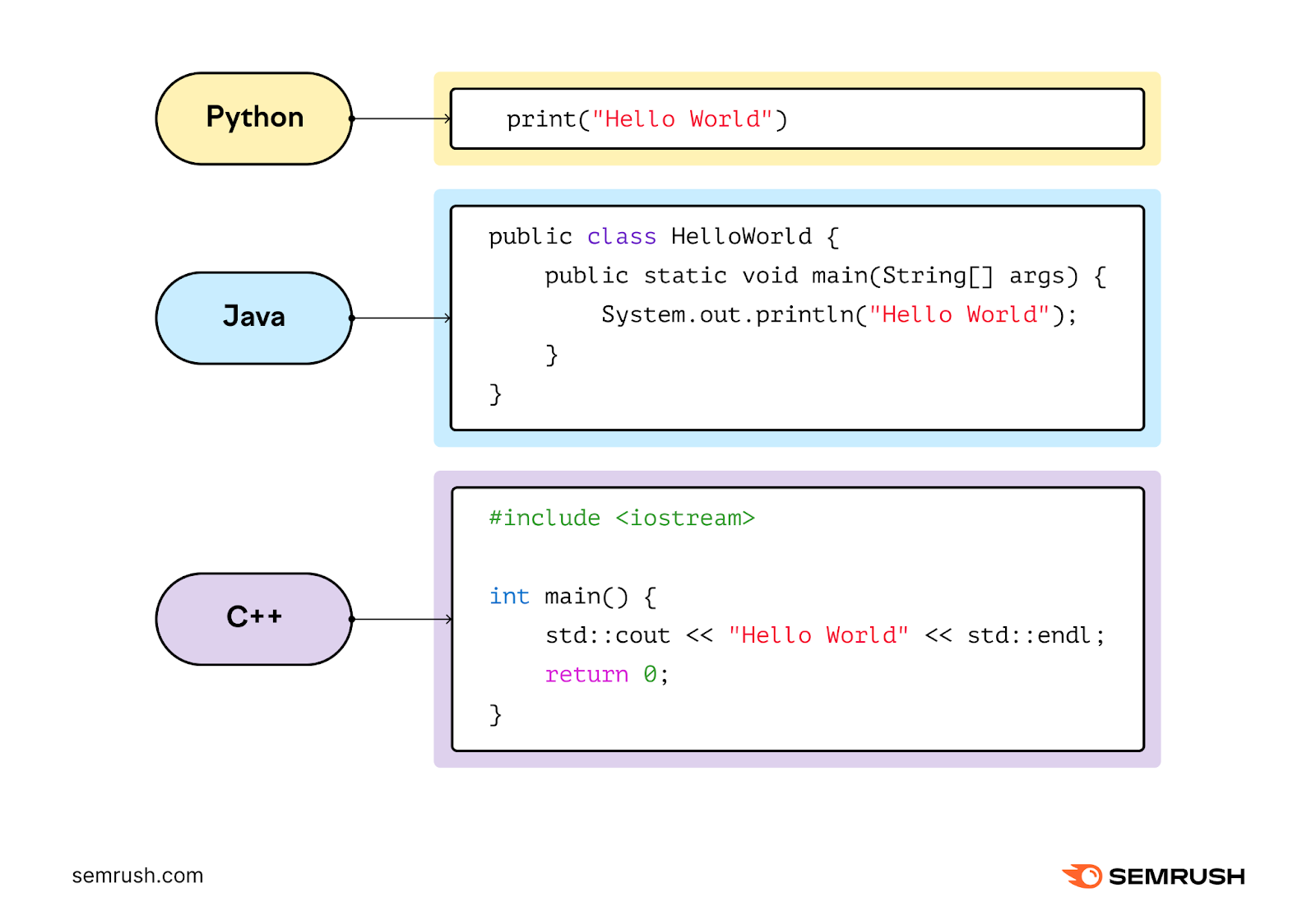
使用ChatGPT时,我们建议提示它:
- 作为Python专家和
- 帮助解决问题
然后,状态:
- 目标("查询Google")和
- 所需的输出("查询的最简单版本")
设置Python环境
在使用Python抓取和分析Google搜索结果之前,您需要设置Python环境。
有很多方法可以让Python启动并运行。 但开始分析谷歌搜索引擎结果页面的最快方法之一(塞尔维亚人)用Python是谷歌自己的笔记本环境:谷歌Colab.
以下是开始使用谷歌Colab是多么容易:
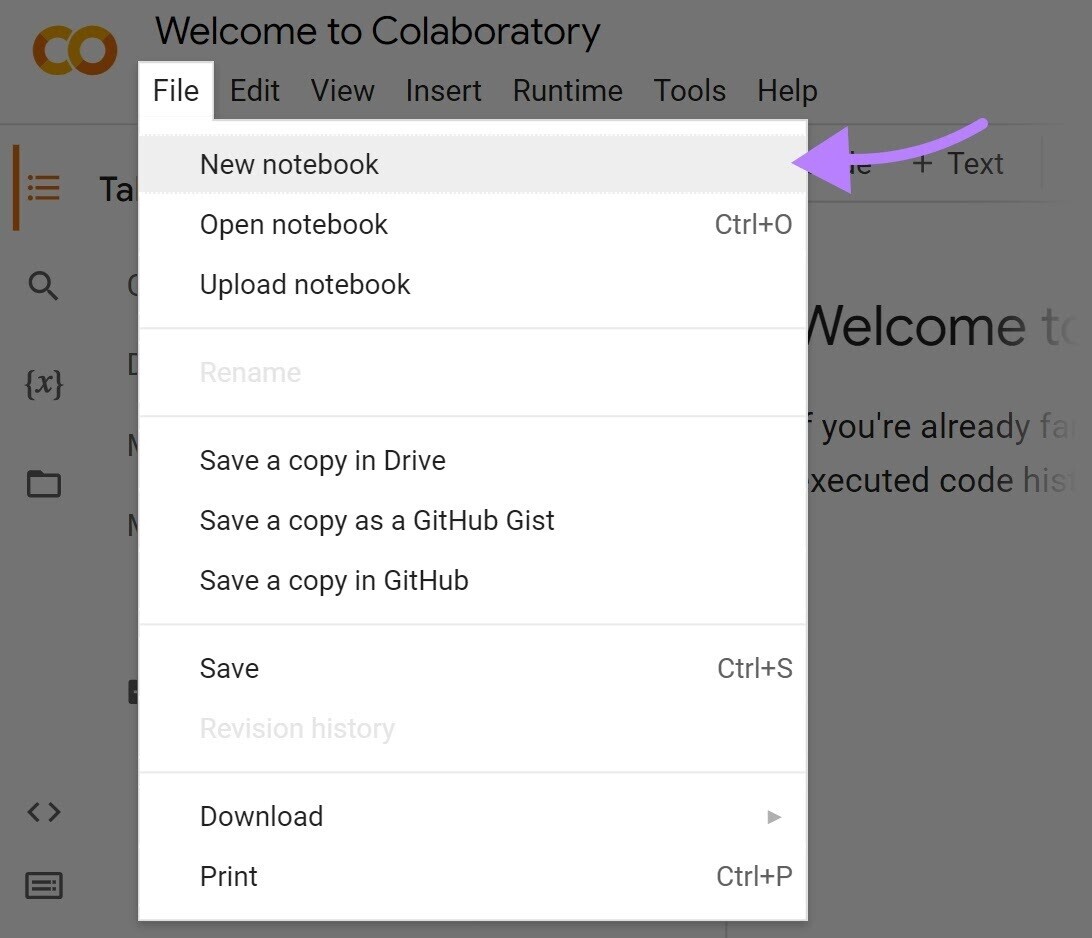
1. 访问谷歌Colab:打开web浏览器并转到谷歌Colab. 如果您有Google帐户,请登录。 如果没有,请创建一个新帐户。
2. 创建一个新的笔记本:在谷歌Colab中,点击"档案”> “新的 笔记本"来创建一个新的Python笔记本。
3. 检查安装:为了确保Python正常工作,请通过输入并执行下面的代码来运行一个简单的测试。 谷歌Colab会向您显示当前安装的Python版本:
进口系统
系统。版本那不是很简单吗?
在您执行实际的Google搜索之前,只需再进行一步。
导入Python Googlesearch模块
使用googlesearch-python包使用Python抓取和分析Google搜索结果。 它提供了一种以编程方式执行Google搜索的便捷方式。
只需在代码单元格中运行以下代码即可访问此Python Google搜索模块:
从googlesearch导入搜索
print("Googlesearch包安装成功!")使用谷歌Colab的一个好处是预先安装了googlesearch-python包。 所以,没有必要先这样做。
一旦你看到消息"Googlesearch包安装成功!"
现在,我们将探讨如何使用该模块执行Google搜索。 并从搜索结果中提取有价值的信息。
如何使用Python执行Google搜索
要执行Google搜索,请编写并运行几行代码,指定您的搜索查询,显示多少结果以及其他一些详细信息(下一节将详细介绍此内容)。
#设置查询以在Google中搜索
查询="长冬大衣"
#执行查询并存储搜索结果
结果=搜索(查询,tld="com",lang="en",停止=3,暂停=2)
#遍历所有搜索结果并打印它们
对于结果的结果:
打印(结果)然后,您将看到查询"long winter coat"的前三名Google搜索结果。"
这是它在笔记本上的样子:

要验证结果是否准确,您可以使用关键字概述.
打开工具,在搜索框中输入"long winter coat",并确保位置设置为"U.s."并单击"搜索."
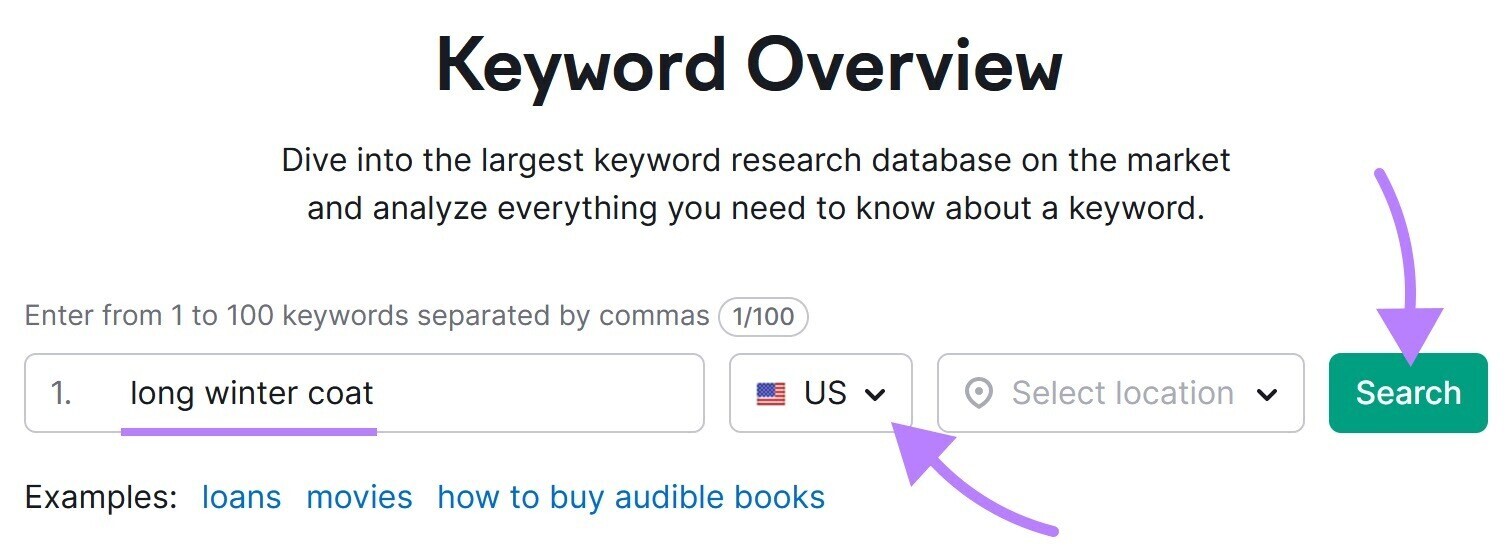
向下滚动到"SERP分析"表。 你应该在前三个点看到相同(或非常相似)的网址。
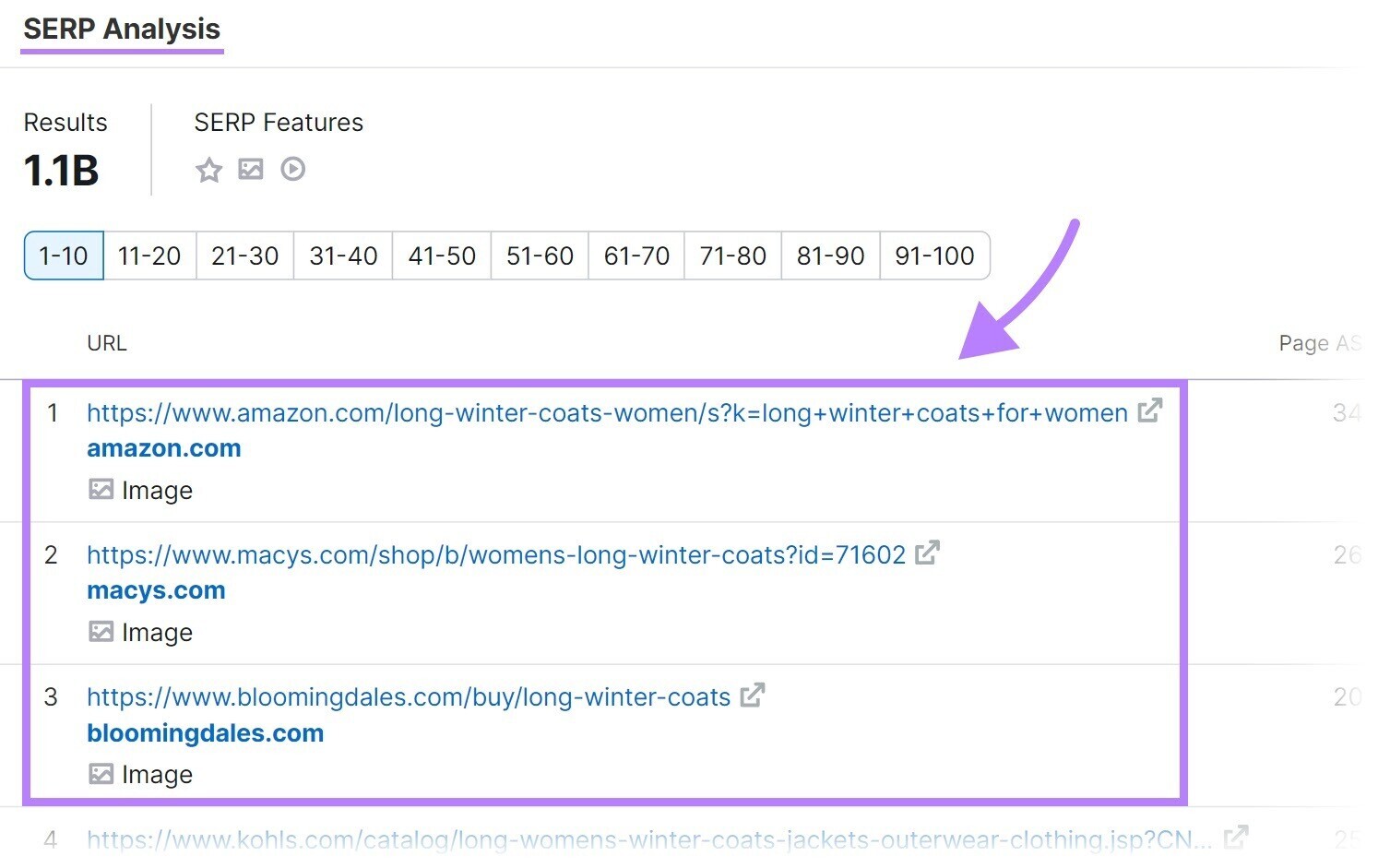
关键字概述还向您显示了Python无法访问的许多有用数据。 喜欢每月搜索量(全球和您选择的位置),关键词难度(表示在给定术语的前10名结果中排名有多困难的分数),搜索意图(用户查询背后的原因),等等。
用Python理解你的谷歌搜索
让我们通过我们刚刚运行的代码。 因此,您可以了解每个部分的含义以及如何根据您的需求进行调整。
我们将回顾下图中突出显示的每个部分:

- 查询变量:查询变量存储要在Google上执行的搜索查询
- 搜索功能:搜索功能提供各种参数,允许您自定义搜索和检索特定结果:
- 查询:告诉搜索功能要搜索的短语或单词。 这是唯一必需的参数,因此搜索函数将在没有它的情况下返回错误。 这是唯一必需的参数;以下所有参数都是可选的。
- 顶级域名(顶级域名的简称):允许您确定要在哪个版本的Google网站中执行搜索。 将其设置为"com"将搜索google.com;将其设置为"fr"将搜索google.fr...
- 朗:允许您指定搜索结果的语言。 并接受两个字母的语言代码(例如,"en"表示英语)。
- 停止:设置搜索功能的搜索结果的编号。 我们将搜索限制在前三个结果中,但您可能希望将值设置为"10"。”
- 停顿一下:指定发送到Google的连续请求之间的时间延迟(以秒为单位)。 设置适当的暂停值(我们建议至少为10)可以帮助避免因太快发送太多请求而被Google阻止。
- 对于循环序列:这行代码告诉循环逐个遍历"results"集合中的每个搜索结果,将每个搜索结果URL分配给变量"result"
- 对于循环动作:此代码块遵循for循环序列(缩进),并包含要对每个搜索结果URL执行的操作。 在这种情况下,它们被打印到谷歌Colab中的输出区域。
如何使用Python分析Google搜索结果
使用Python抓取Google搜索结果后,您可以使用Python分析数据以提取有价值的见解。
例如,您可以确定哪些关键字的Serp足够相似,可以针对单个页面。 意思是Python正在做涉及的繁重工作关键字聚类.
让我们坚持我们的查询"长冬大衣"作为起点。 把它塞进关键字概述揭示超过3,000个关键字变化。
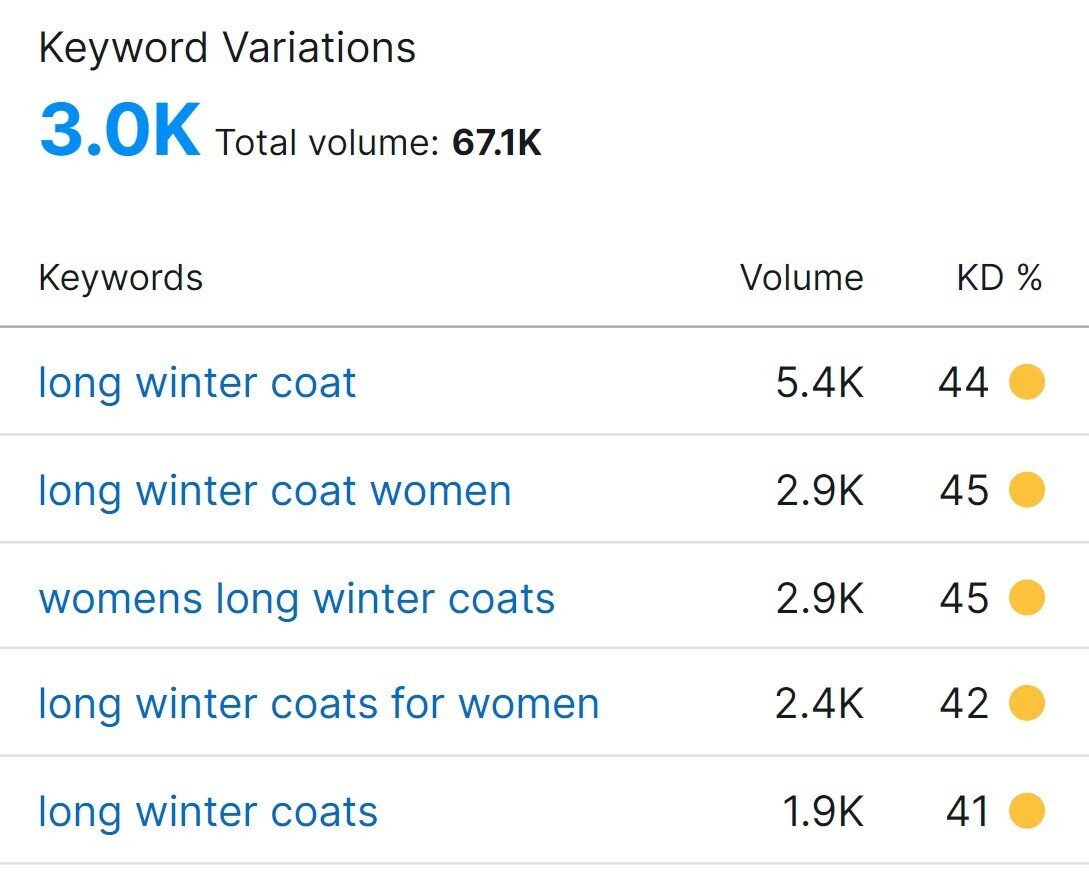
为了简单起见,我们将坚持上面可见的五个关键字。 并让Python通过在我们的谷歌Colab笔记本中的新代码单元格中创建和执行此代码来分析和集群它们:
导入pandas作为pd
#定义主查询和查询列表
main_query="长冬大衣"
secondary_queries=["long winter coat women","womens long winter coat","long winter coat for women","long winter coat"]
#执行主查询并存储搜索结果
main_results=搜索(main_query,tld="com",lang="en",stop=3,pause=2)
main_urls=set(main_results)
#字典来存储每个查询的URL百分比
url_percentages={}
#迭代查询
对于secondary_queries中的secondary_query:
#执行查询并存储搜索结果
secondary_results=搜索(secondary_query,tld="com",lang="en",stop=3,pause=2)
secondary_urls=set(secondary_results)
#计算主查询结果中出现的Url的百分比
百分比=(len(main_urls.intersection(secondary_urls))/len(main_urls))*100
url_percentages[secondary_query]=百分比
#从url_percentages字典创建dataframe
df_url_percentages=pd。DataFrame(url_percentages.items(),columns=['Secondary 查询','Percentage'])
#将dataframe按百分比降序排序
df_url_percentages=df_url_percentages。sort_values(by='Percentage',ascending=False)
#打印已排序的dataframe
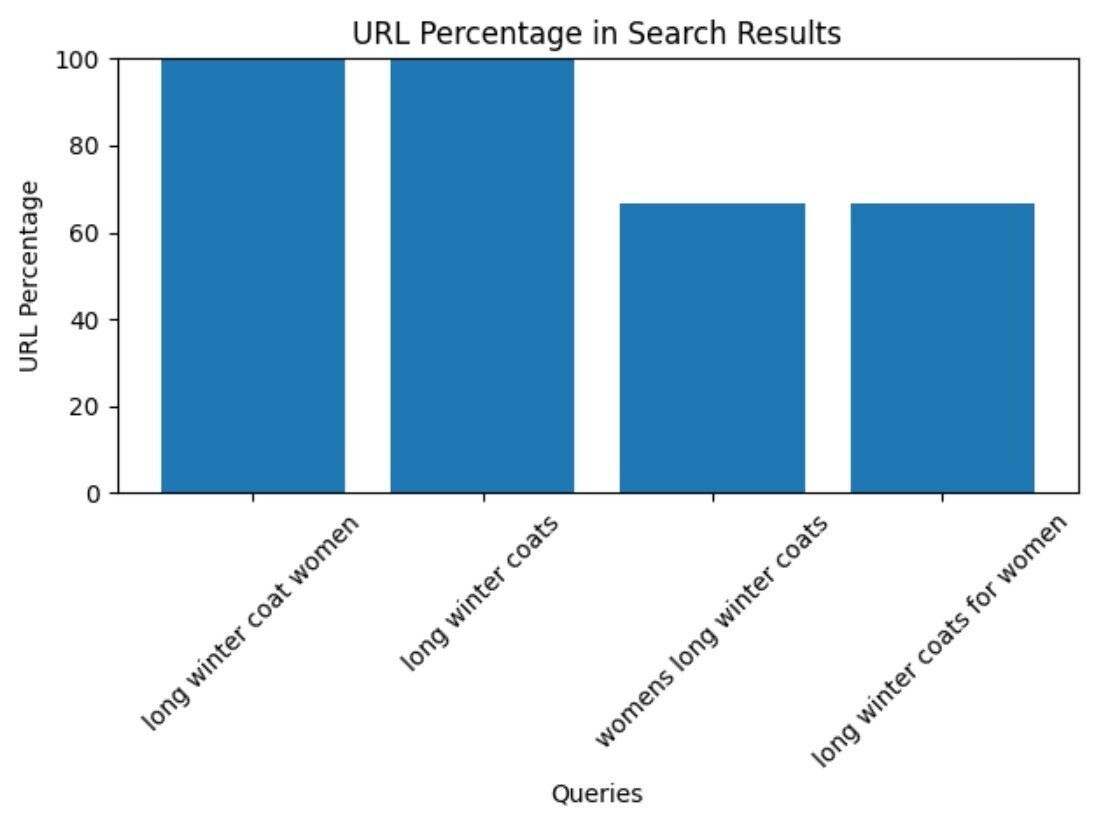
df_url_percentages通过14行代码和十几秒的等待执行,我们现在可以看到这些查询的前三个结果是相同的:
- "冬季长外套"
- "长冬大衣女"
- "女式冬衣"
- "女性冬季长外套"
- "冬季长外套"
因此,这些查询可以使用相同的页面进行定位。
此外,你不应该尝试为"长冬大衣"或"长冬大衣"排名,并为男士提供大衣。
使用Python了解您的Google搜索分析
再次,让我们通过我们刚刚执行的代码。 这次有点复杂,但我们刚刚产生的见解也更有用。

1. 导入pandas作为pd:导入Pandas库并使其可通过缩写"pd."我们将使用Pandas库创建一个"DataFrame",它本质上是Python输出区域内的一个表。
2. Main_query="python谷歌搜索":定义要在Google上搜索的主要查询
3. Secondary_queries=["google搜索python","google搜索api python","python搜索google","如何抓取google搜索结果python"]:创建要在Google上执行的查询列表。 您可以粘贴更多的查询,并为您创建数百个Python集群。
4. Main_results=search(main_query,tld="com",lang="en",stop=3,pause=2):执行主查询并将搜索结果存储在main_results中。 我们将结果数量限制为三个(stop=3),因为Google搜索结果中的前三个网址通常在满足用户的搜索意图方面做得最好。
5. Main_urls=set(main_results):将主查询的搜索结果转换成一组Url并存储在main_urls中
6. Url_percentages={}:初始化空字典(具有固定值对的列表),以存储每个查询的URL百分比

7. 对于secondary_queries中的secondary_query ::启动循环,循环遍历辅助查询列表中的每个辅助查询
8. Secondary_results=搜索(secondary_query,tld="com",lang="en",stop=3,pause=2):执行当前辅助查询并将搜索结果存储在secondary_results中。 我们将结果数量限制为三个(停止=3),原因与我们前面提到的相同。
9. Secondary_urls=set(secondary_results):将当前二级查询的搜索结果转换成一组Url并存储在secondary_urls中
10. 百分比=(len(main_urls.intersection(urls))/len(main_urls))*100:计算主查询结果和当前辅助查询结果中出现的Url的百分比。 结果存储在变量百分比中。
11. Url_percentages[secondary_query]=百分比:将计算的URL百分比存储在url_percentages字典中,以当前辅助查询为键

12. Df_url_percentages=pd。DataFrame(url_percentages.items(),columns=['Secondary 查询','Percentage']):创建一个Pandas DataFrame,用于保存第一列中的辅助查询以及它们与第二列中的主查询的重叠。 Columns参数(为表添加了三个标签)用于指定DataFrame的列名。
13. Df_url_percentages=df_url_percentages。sort_values(by='Percentage',ascending=False):根据百分比列中的值对数据帧df_url_percentages进行排序。 通过设置ascending=False,数据帧将从最高值到最低值进行排序。
14. Df_url_percentages:在谷歌Colab输出区域显示排序后的DataFrame。 在大多数其他Python环境中,您必须使用print()函数来显示DataFrame。 但不是在谷歌Colab-加上表是交互式的。
简而言之,此代码执行一系列Google搜索,并显示每个辅助查询和主查询的前三个搜索结果之间的重叠。
重叠越大,您对具有相同页面的主查询和辅助查询进行排名的可能性就越大。
可视化您的Google搜索分析结果
可视化谷歌搜索分析的结果可以提供一个清晰和直观的数据表示。 并使您能够轻松地解释和交流发现。
当我们将关键字聚类代码应用于不超过20或30个查询时,可视化就派上用场了。
注:对于较大的查询样本,我们将要创建的条形图中的查询标签将相互渗透。 这使得上面创建的DataFrame对于聚类更有用。
您可以使用Python和Matplotlib使用此代码将URL百分比可视化为条形图:
导入matplotlib。pyplot作为plt
sorted_percentages=sorted(url_percentages.items(),key=lambda x:x[1],reverse=True)
sorted_queries,sorted_percentages=zip(*sorted_percentages)
#用排序的x轴绘制URL百分比
plt的。酒吧(sorted_queries,sorted_percentages)
plt的。xlabel("查询")
plt的。ylabel("URL百分比")
plt的。标题("搜索结果中的URL百分比")
plt的。xticks(旋转=45)
plt的。伊利姆(0,100)
plt的。紧_layout()
plt的。表演()我们将快速再次运行代码:

1. Sorted_percentages=sorted(url_percentages.items(),key=lambda x:x[1],reverse=True):这指定URL百分比字典(url_percentages)使用sorted()函数按值降序排序。 它创建一个按URL百分比排序的元组(值对)列表。
2. Sorted_queries,sorted_percentages=zip(*sorted_percentages):这表示使用zip()函数和*运算符将元组的排序列表解压缩为两个单独的列表(sorted_queries和sorted_percentages)。 Python中的*运算符是一种工具,可让您将集合分解为其各个项

3. Plt的。酒吧(sorted_queries,sorted_percentages):这使用plt创建条形图。bar()从Matplotlib. 排序后的查询分配给x轴(sorted_queries)。 和相应的URL百分比分配给y轴(sorted_percentages)。
4. Plt的。xlabel("查询"):这为x轴设置标签"查询"
5. Plt的。ylabel("URL百分比"):这为y轴设置标签"URL百分比"
6. Plt的。标题("搜索结果中的URL百分比"):这将图表的标题设置为"搜索结果中的URL百分比"
7. Plt的。xticks(旋转=45):这使用plt将x轴刻度标签旋转45度。xticks()更好的可读性
8. Plt的。伊利姆(0,100):这使用plt将y轴限制从0设置为100。ylim()以确保图表适当地显示URL百分比
9. Plt的。紧_layout():此功能调整子图之间的填充和间距,以改善图表的布局
10. Plt的。表演():此功能用于显示可视化您的Google搜索结果分析的条形图
下面是输出的样子:
使用Python的分析能力掌握Google搜索
Python提供了令人难以置信的分析功能,可以利用这些功能有效地抓取和分析Google搜索结果。
我们已经研究了如何聚类关键字,但使用Python进行Google搜索分析的应用程序几乎是无限的。
但即使只是为了扩展我们刚刚进行的关键字聚类,您也可以:
- 刮取您计划使用一个页面定位的所有查询的Serp,并提取所有精选片段文本为他们优化
- 刮下里面的问题和答案人们也会问框调整您的内容显示在那里
你需要比Googlesearch模块更强大的东西。 有一些很棒的SERP应用程序编程接口(Api)可以提供您在Google SERP本身上找到的几乎所有信息,但您可能会发现开始使用更简单关键字概述.
此工具显示您的目标关键字的所有SERP功能。 因此,您可以研究它们并开始优化您的内容。