

 外贸B2B建站
外贸B2B建站  高端定制设计
高端定制设计  系统功能优势
系统功能优势 


 Google SEO优化
Google SEO优化  Google SEM广告
Google SEM广告  网站内容营销
网站内容营销  优化案例
优化案例  设计赏析
设计赏析  搜索引擎优化
搜索引擎优化  付费广告
付费广告  社媒运营
社媒运营  公司介绍
公司介绍  渠道共赢
渠道共赢  联系我们
联系我们 像谷歌这样的搜索引擎使用网站抓取器来阅读和理解网页。
但搜索引擎优化专业人员也可以使用网络爬虫发现问题和机会在他们自己的网站。 或从竞争网站中提取信息。
网上有大量的爬行和刮削工具可用。 虽然有些对SEO和数据收集有用,但其他人可能有可疑的意图或带来潜在的风险。
为了帮助您浏览网站抓取工具的世界,我们将引导您了解抓取工具是什么,它们是如何工作的,以及如何安全地使用正确的工具来发挥您的优势。
什么是网站爬虫?
网络爬虫是一种自动访问和处理网页以了解其内容的robots.
他们有很多名字,比如:
- 履带式/履带式
- 机器人
- 蜘蛛
- 蜘蛛人
蜘蛛的绰号来自这些机器人在万维网上爬行的事实。
搜索引擎使用抓取工具来发现和分类网页。 然后,为用户提供他们认为最好的服务,以响应搜索查询。
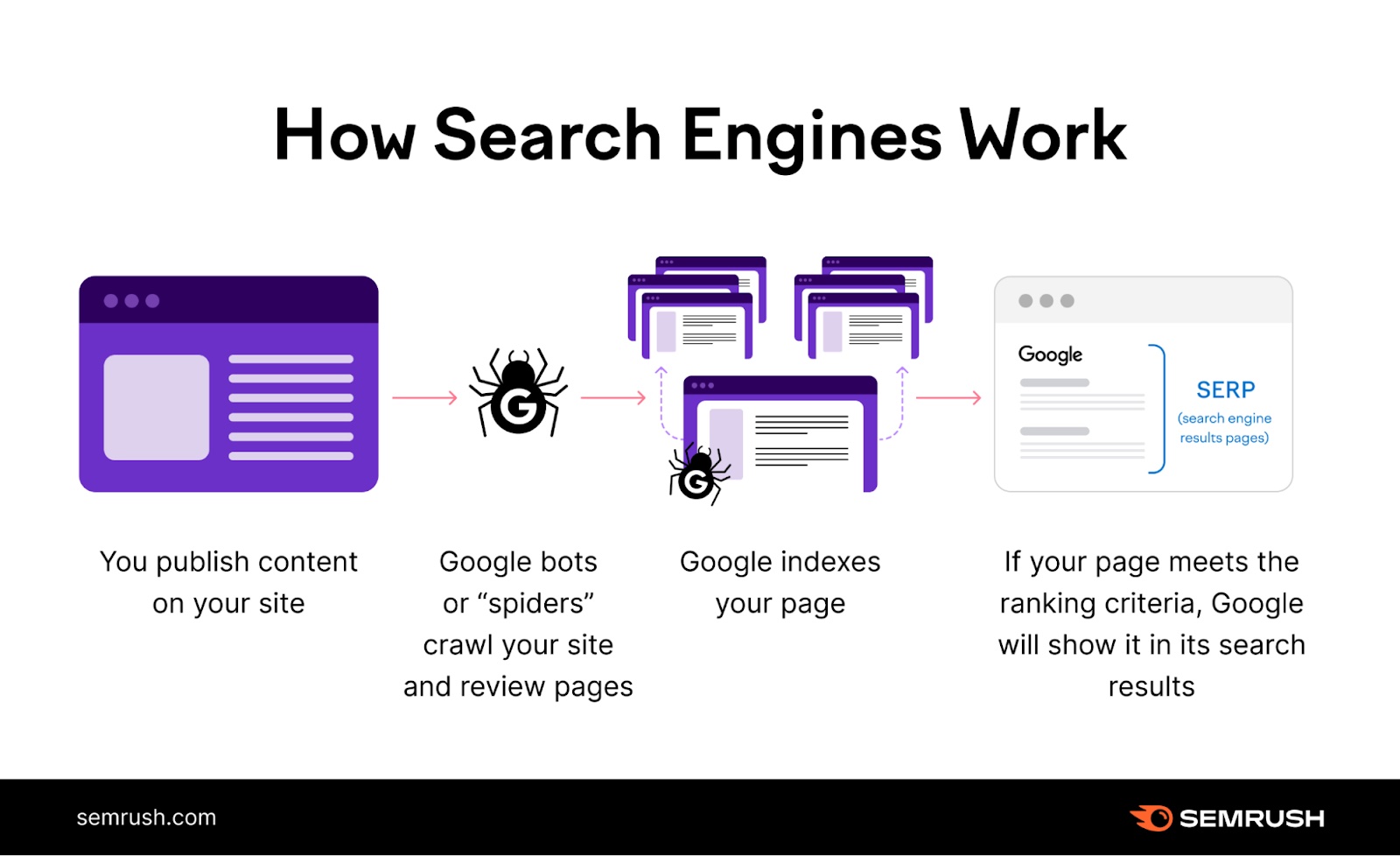
例如,谷歌的网络爬虫是搜索引擎过程中的关键参与者:
- 您在网站上发布或更新内容
- 机器人抓取您网站的新页面或更新页面
- Google对抓取工具找到的页面进行索引-尽管在某些情况下可能会阻止索引的一些问题
- Google(希望)根据与用户查询的相关性在搜索结果中显示您的页面
但搜索引擎并不是唯一使用网站抓取工具. 您还可以自己部署网络爬网程序来收集有关网页的信息。
公开可用的抓取工具与Googlebot或Bingbot(Google和Bing使用的独特网络抓取工具)等搜索引擎抓取工具略有不同。 但他们以类似的方式工作—他们访问网站并像搜索引擎爬虫一样"阅读"它。
您可以使用这些类型的抓取工具的信息来改进您的网站。 或更好地了解其他网站。
网络爬虫是如何工作的?
网络爬虫扫描网页上的三个主要元素:内容,密码,而连结.
通过阅读内容,机器人可以评估页面的内容。 这些信息有助于搜索引擎算法确定哪些页面具有用户在搜索时要查找的答案。
这就是为什么使用SEO关键词战略上是如此重要。 它们有助于提高算法将该页面连接到相关搜索的能力。
在阅读页面内容时,网络蜘蛛也会抓取页面的HTML密码. (所有网站都由html代码组成,构成每个网页及其内容。)
你可以使用某些HTML代码(如元标签),以帮助爬虫更好地了解您的页面的内容和目的。
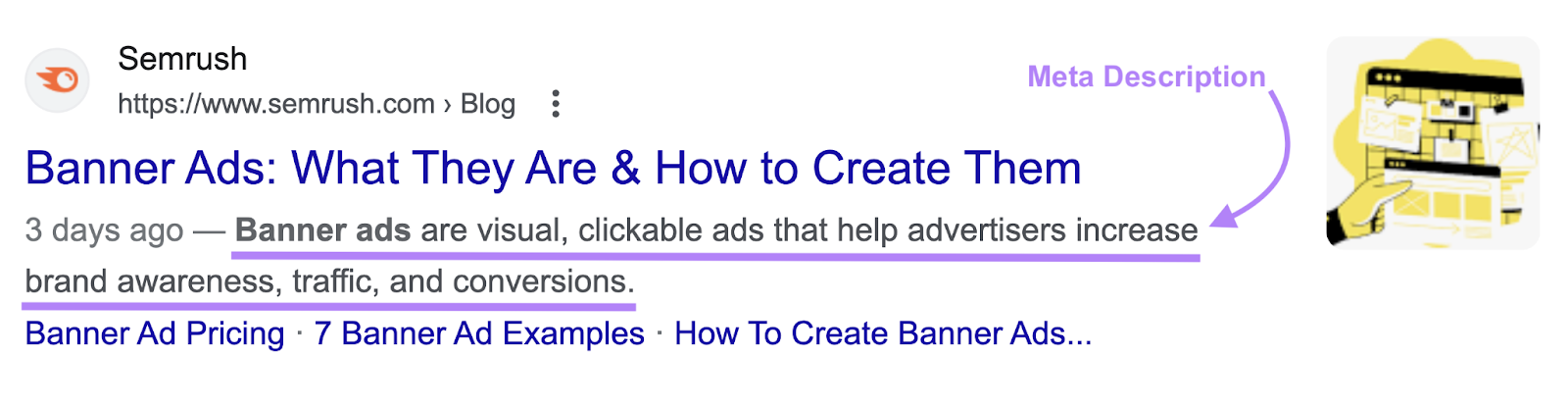
例如,您可以使用元描述标记影响您的页面在Google搜索结果中的显示方式。
这里有一个元描述:
下面是元描述标签的代码:
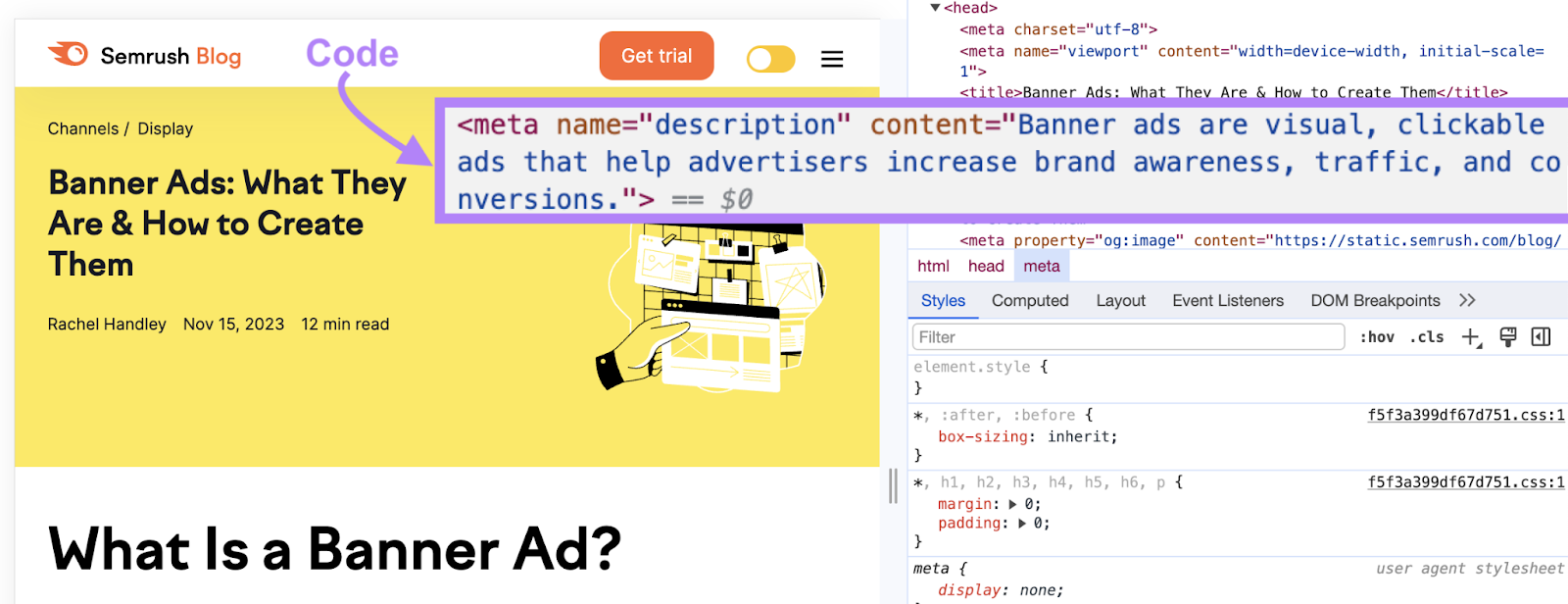
利用元标签只是另一种方式,为搜索引擎抓取工具提供有关您的页面的有用信息,以便它可以得到适当的索引。
爬虫需要冲刷数十亿个网页。 为了做到这一点,他们遵循的途径。 这些途径在很大程度上是由内部决定的连结.
如果页面a在其内容中链接到页面B,则机器人可以跟随页面a到页面B的链接,然后处理页面B。

这就是为什么内部链接是SEO如此重要。 它可以帮助搜索引擎抓取工具查找和索引您网站上的所有页面。
为什么你应该抓取自己的网站
使用网络爬虫审核您自己的站点可以找到可抓取性和可索引性问题否则可能会从裂缝中溜走。
抓取您自己的网站还允许您以搜索引擎爬虫的方式查看您的网站。 以帮助您优化它。
以下是个人网站审核的几个重要用例示例:
确保Google抓取工具可以轻松浏览您的网站
网站审核可以准确地告诉您Google机器人导航您的网站有多容易。 并对其内容进行处理。
例如,您可以找到哪些类型的问题会阻止您的网站被有效地爬网。 像临时重定向,重复内容等。
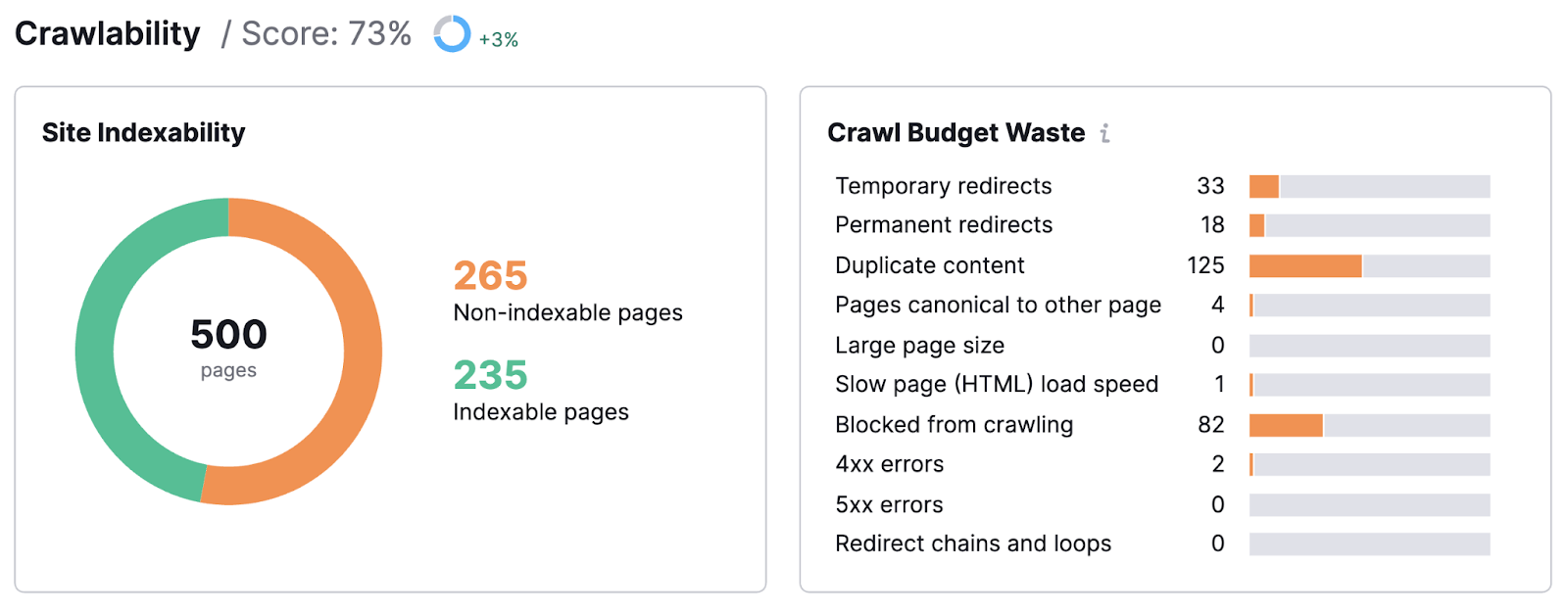
您的网站审核甚至可能会发现Google无法索引的页面。
这可能是由于多种原因造成的。 但不管是什么原因,你需要修复它。 或者冒着失去时间,金钱和排名权力的风险。
好消息是,一旦你发现了问题,你就可以解决它们。 并回到SEO成功的道路上。
识别损坏的链接,以改善网站健康和链接公平
断开的链接是最重要的常见的链接错误.
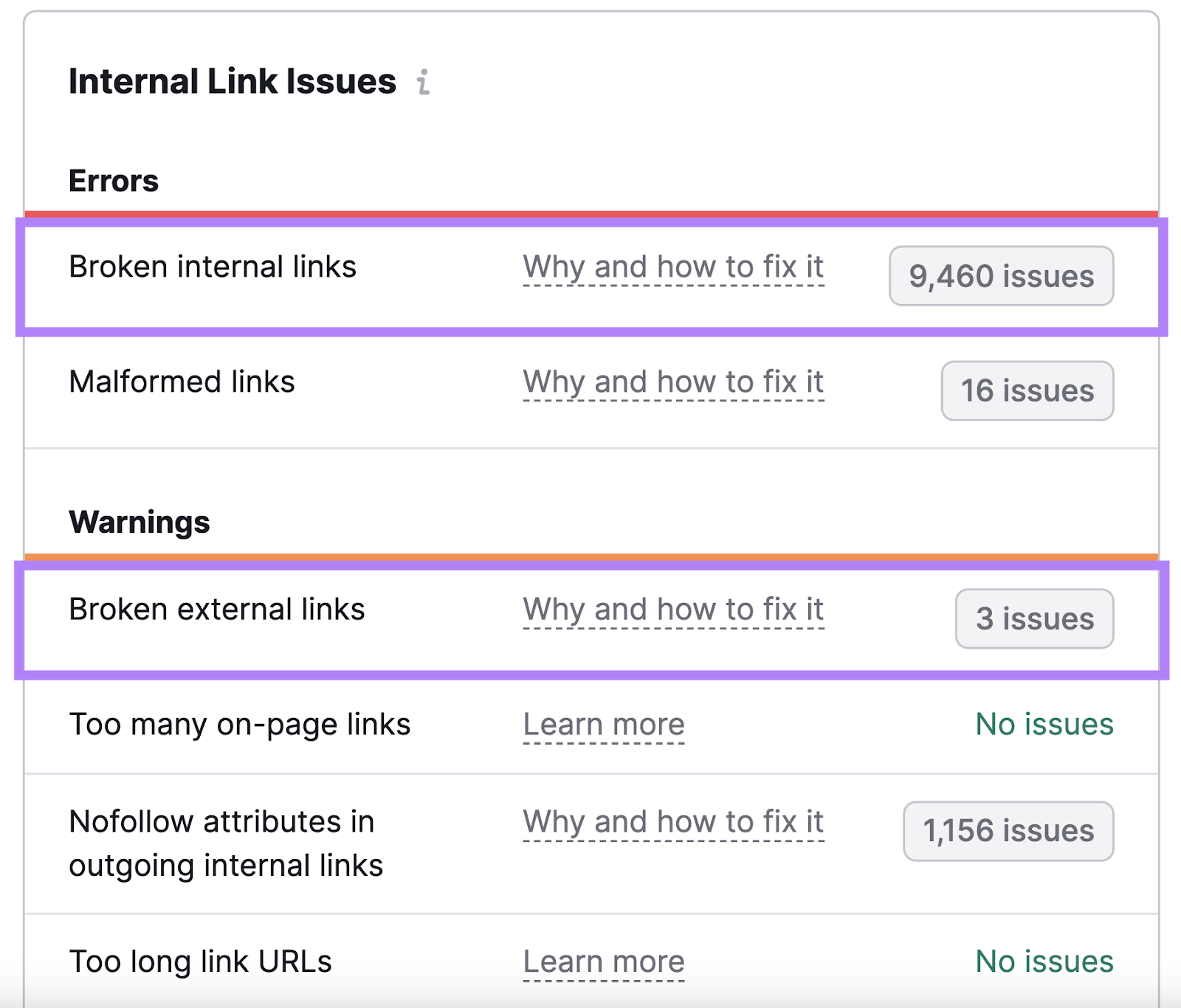
他们是一个讨厌的用户。 而谷歌的网络爬虫-因为它们使您的网站看起来维护或编码不佳。
查找损坏的链接并修复它们以确保强大的站点健康。
修复本身可以很简单:删除链接,替换它,或联系您链接到的网站的所有者(如果它是外部链接)并报告问题。
查找重复内容以修复混乱的排名
重复内容(相同或几乎相同的内容,可以在您的网站的其他地方找到)可能会导致主要的搜索引擎优化问题混淆搜索引擎。
它可能会导致页面的错误版本显示在搜索结果中。 或者,它甚至可能看起来像你正在使用恶意做法来操纵谷歌。
网站审核可以帮助您找到重复的内容。
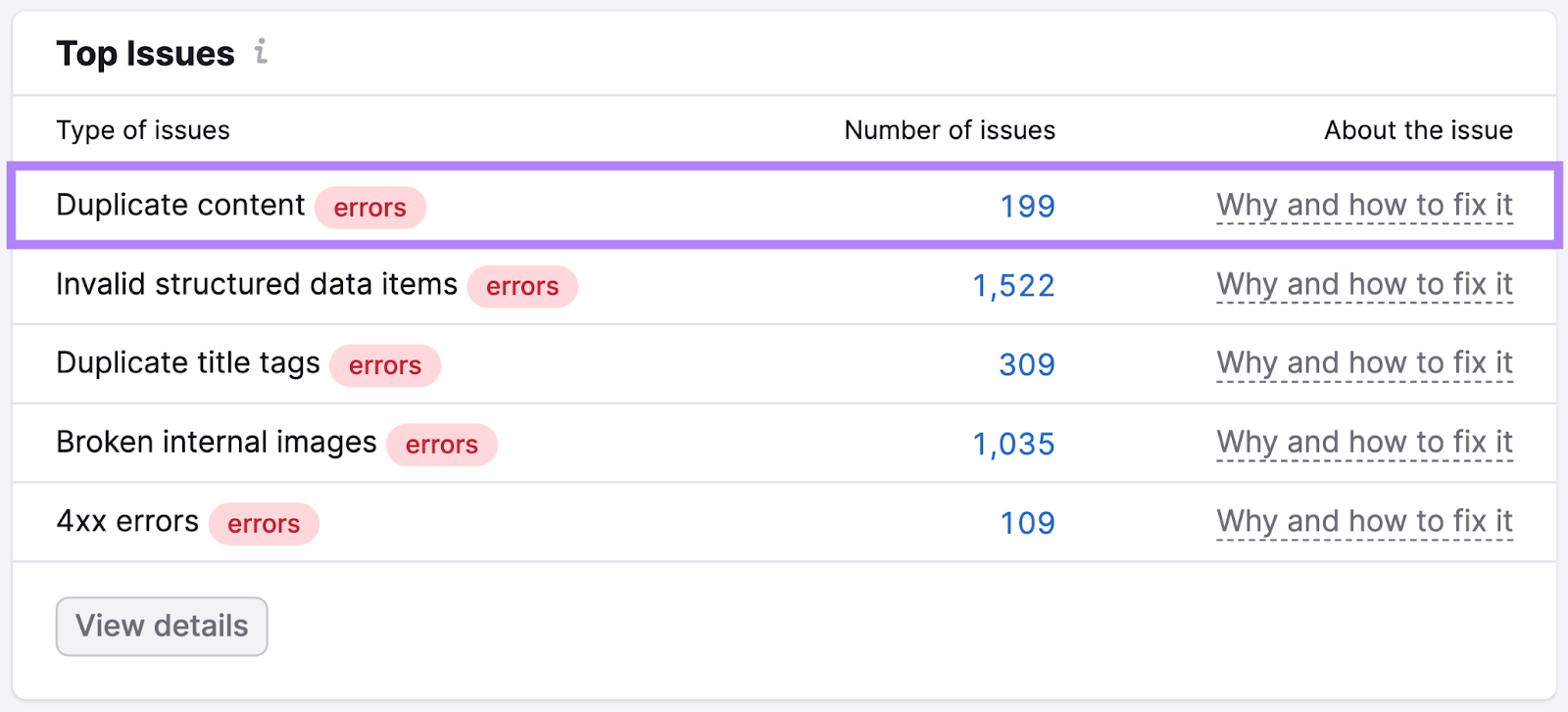
然后,你可以修复它。 因此,正确的页面可以在搜索结果中占有一席之地。
爬虫与刮板:比较工具
内容抓取器和内容抓取器通常可以互换使用。
但爬虫访问和索引网站内容。 而抓取工具用于从网页甚至整个网站中提取数据。
一些恶意行为者使用刮板来撕下并重新发布其他网站的内容。 这违反了这些网站的版权,并可以窃取他们的搜索引擎优化努力。
也就是说,刮板有合法的用例。
像抓取数据进行集体分析(例如,抓取竞争对手的产品列表以评估描述,定价和呈现类似商品的最佳方式)。 或者在您自己的网站上抓取和合法地重新发布内容(例如要求原始发布者的明确许可)。
以下是属于这两个类别的好工具的一些示例。
3刮板工具
网络啄木鸟
网络啄木鸟是一个Chrome扩展程序,可让您从亚马逊和社交网络等主要搜索引擎抓取数据。 然后,您可以下载XLSX、JSON或ZIP格式的数据。
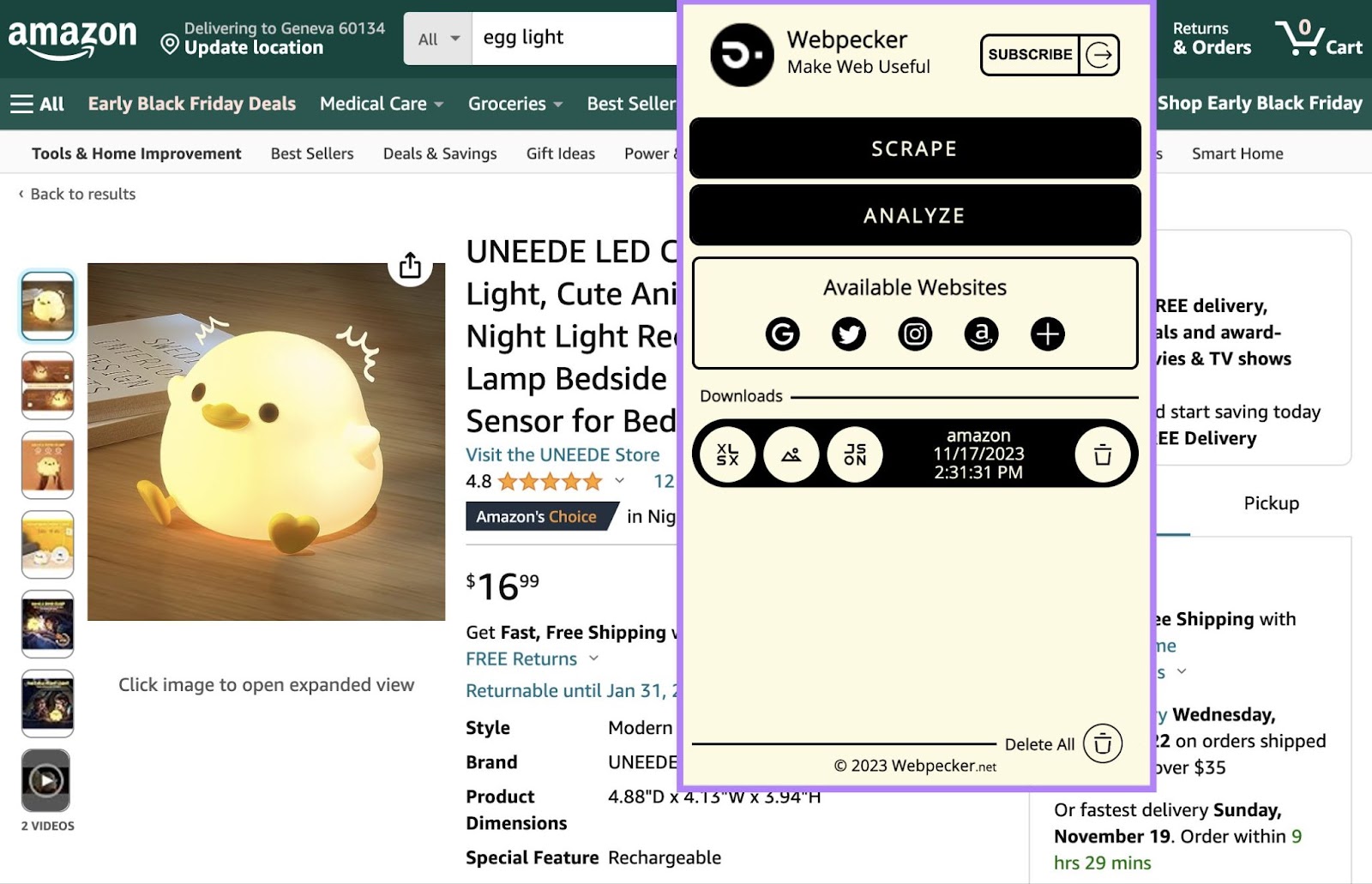
例如,您可以从Amazon抓取以下内容:
- 连结
- 价格;价格
- 图像
- 图像Url
- 数据Url
- 标题
- 评级结果
- 优惠券
或者,您可以从instagram抓取以下内容:
- 连结
- 图像
- 图像Url
- 数据Url
- Alt文本(屏幕阅读器朗读并在图像加载失败时显示的文本)
- 化身
- 喜欢
- 评论
- 日期及时间
- 标题
- 提及
- 主题标签
- 地点
收集这些数据可以让你分析竞争对手,并为你自己的网站或社交媒体的存在找到灵感。
例如,考虑instagram上的主题标签。
战略性地使用它们可以将您的内容放在目标受众面前,并提高用户参与度。 但有无限的可能性,选择正确的主题标签可能是一个挑战。
通过编制竞争对手在高性能帖子上使用的主题标签列表,您可以启动自己的主题标签成功。
如果您刚刚开始并且不确定如何处理产品列表或社交媒体帖子,这种工具尤其有用。
禅宗,禅宗
禅宗,禅宗能够抓取数百万个网页并绕过诸如完全自动化的公共图灵测试等障碍,以区分计算机和人类(CAPTCHAs)。
禅宗,禅宗最好由web开发团队中的某个人部署。 但是一旦设置了参数,该工具说它可以节省数千个开发小时。
它能够绕过通常阻止机器人的"访问被拒绝"屏幕。
ZenRow的自动解析工具可让您抓取感兴趣的页面或网站。 并将数据编译成JSON文件供您评估。
ParseHub
ParseHub是一个无代码的方式刮任何网站的重要数据。
图像源:ParseHub
它可以收集难以访问的数据:
- 表格
- 下拉
- 无限滚动页面
- 弹出窗口
- JavaScript的
- 异步JavaScript的和XML(AJAX—-用于交换数据的编程工具的组合
您可以下载抓取的数据。 或者,将其导入Google表格或Tableau。
使用这样的刮刀可以帮助您研究竞争。 但不要忘记利用爬虫。
3网络爬虫工具
反向链接分析
反向链接分析使用爬虫来研究你和你的竞争对手的传入链接。 它允许您分析您的竞争对手或其他行业领导者的反向链接配置文件。
Semrush的反向链接数据库定期更新有关链接和抓取页面的新信息。 所以信息总是最新的。
打开该工具,输入域名,然后单击"分析,分析.”
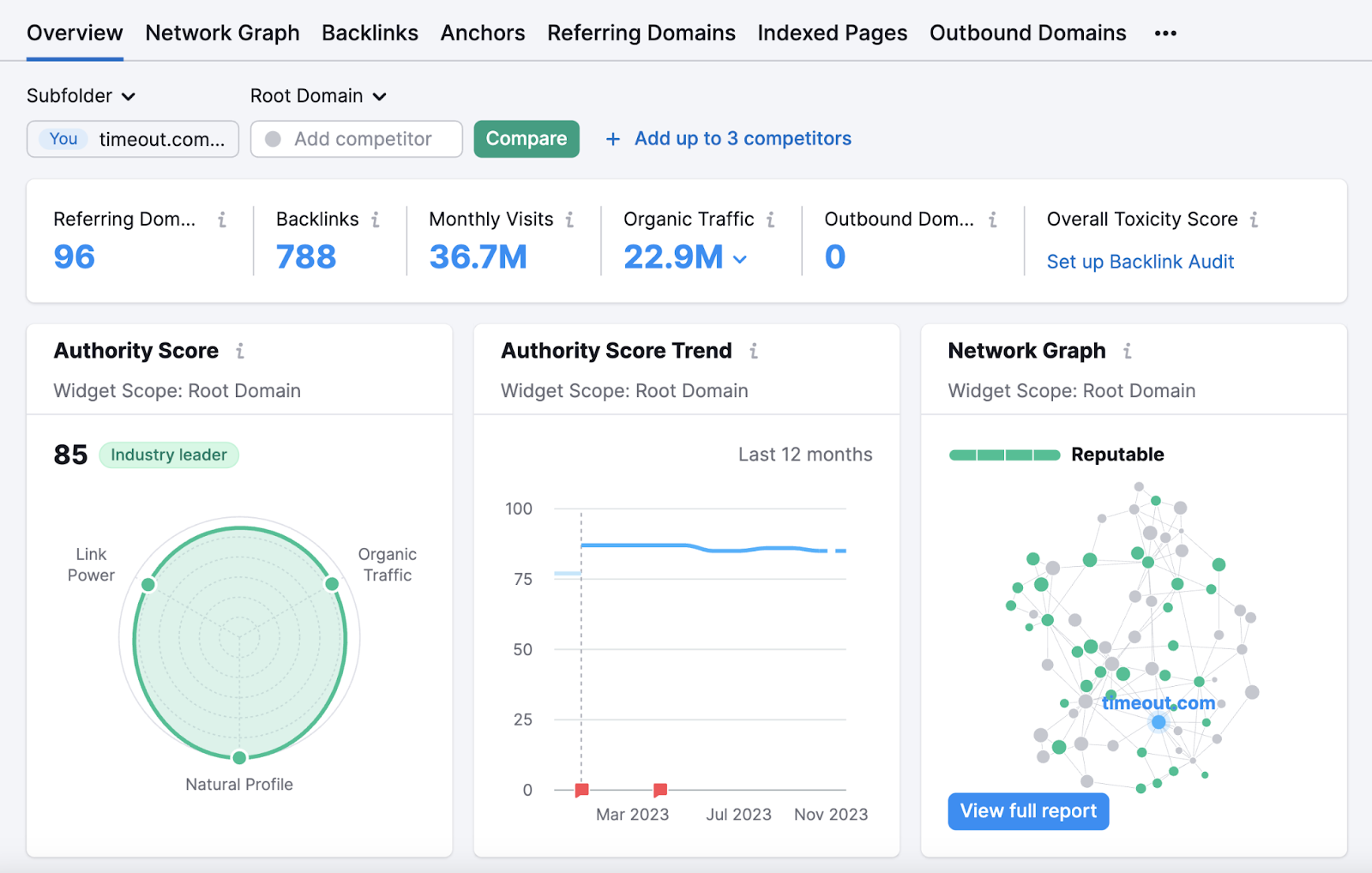
然后,您将被带到"概述"报告。 您可以在其中查看域的反向链接总数,引用域的总数,估计的自然流量等。
反向审计
semrush氏反向审计工具可以让您抓取您自己的网站,以深入了解您的反向链接配置文件的健康程度。 帮助你了解你是否可以提高你的排名潜力。
打开该工具,输入您的域,然后单击"启动反向链接审核.”
然后,按照反向链接审计配置指南设置项目并开始审核。
一旦工具完成收集信息,您将看到"概述"报告。 这给你一个整体的看你的反向链接配置文件。
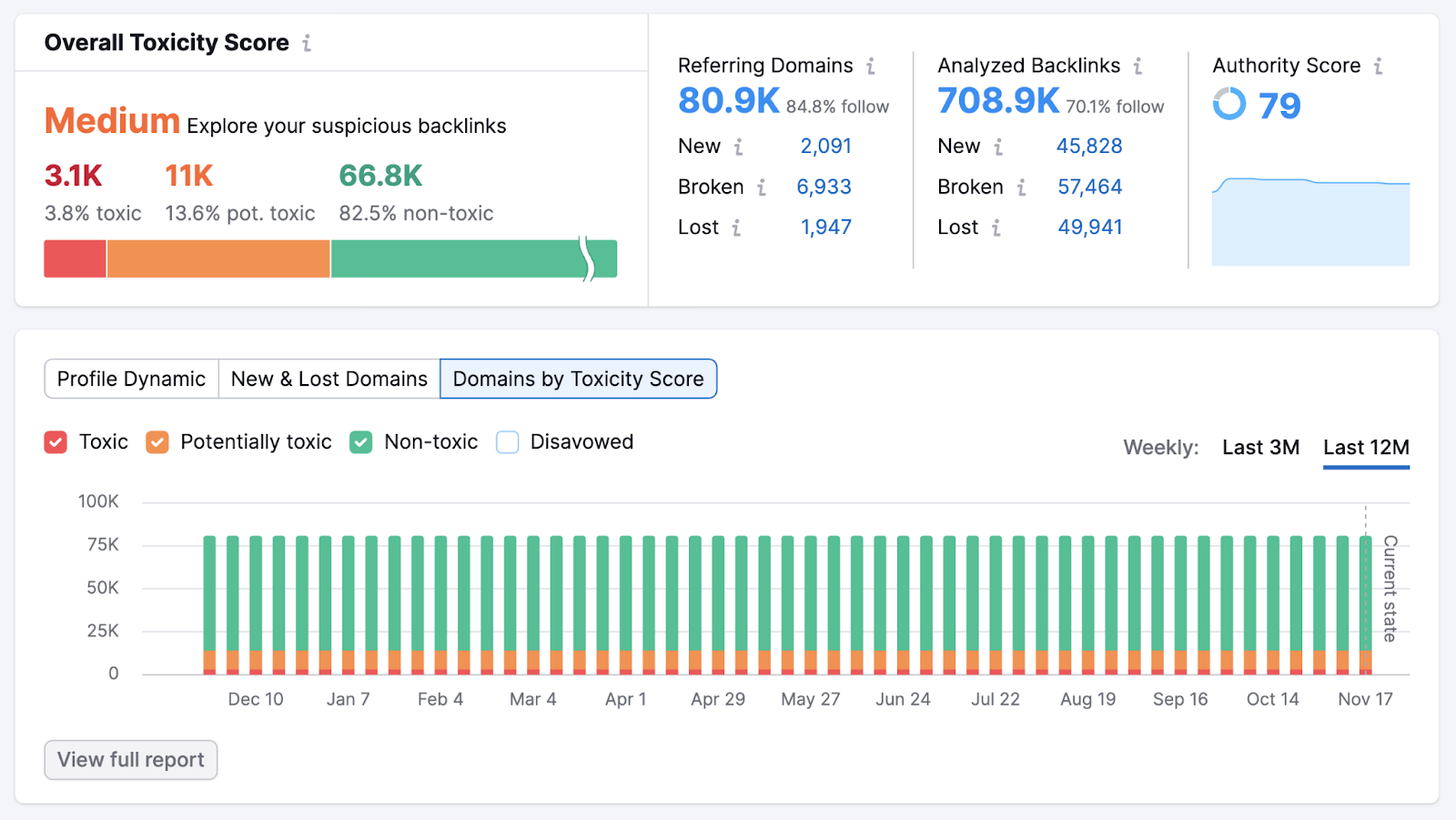
查看"总体毒性评分"(基于链接到您网站的低质量域数量的指标)部分。 "中等"或"高"分数表示您有改进的空间。
现场审核
现场审核使用抓取工具访问您的网站并分析其整体健康状况。 并为您提供可能影响您网站在Google搜索结果中排名的技术问题的报告。
要抓取您的网站,请打开该工具并单击"+创建项目.”
输入您的域和可选项目名称。 然后,点击"创建项目.”
现在,是时候配置您的基本设置了。
首先,定义爬网的范围。 默认设置是对您输入的域及其子域和子文件夹进行爬网。 要编辑此内容,请单击铅笔图标并更改设置。
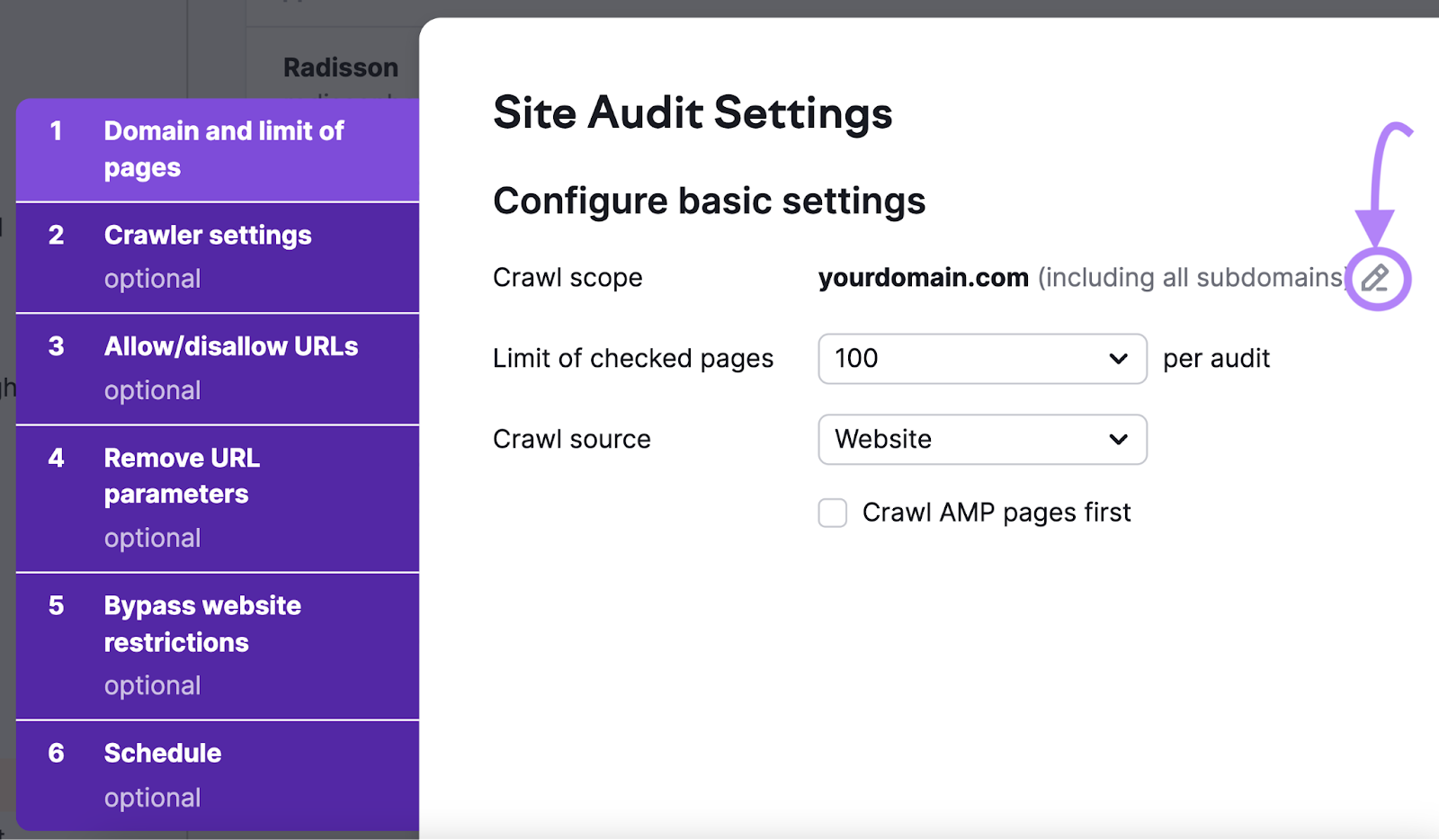
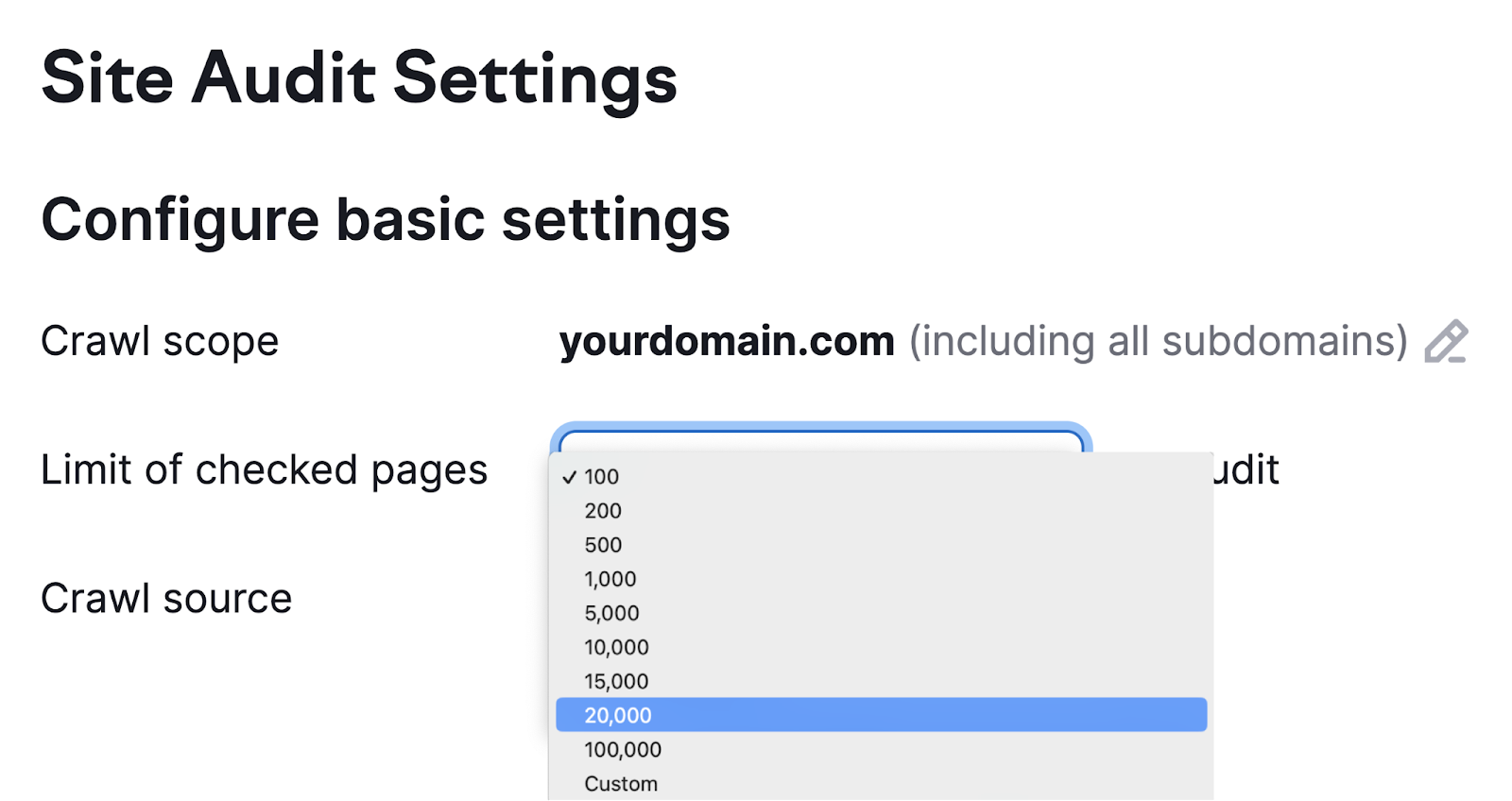
接下来,设置每次审核要爬网的最大页数。 您抓取的页面越多,您的审核就越准确。 但您还需要考虑自己的容量和订阅级别。
然后,选择爬网源。
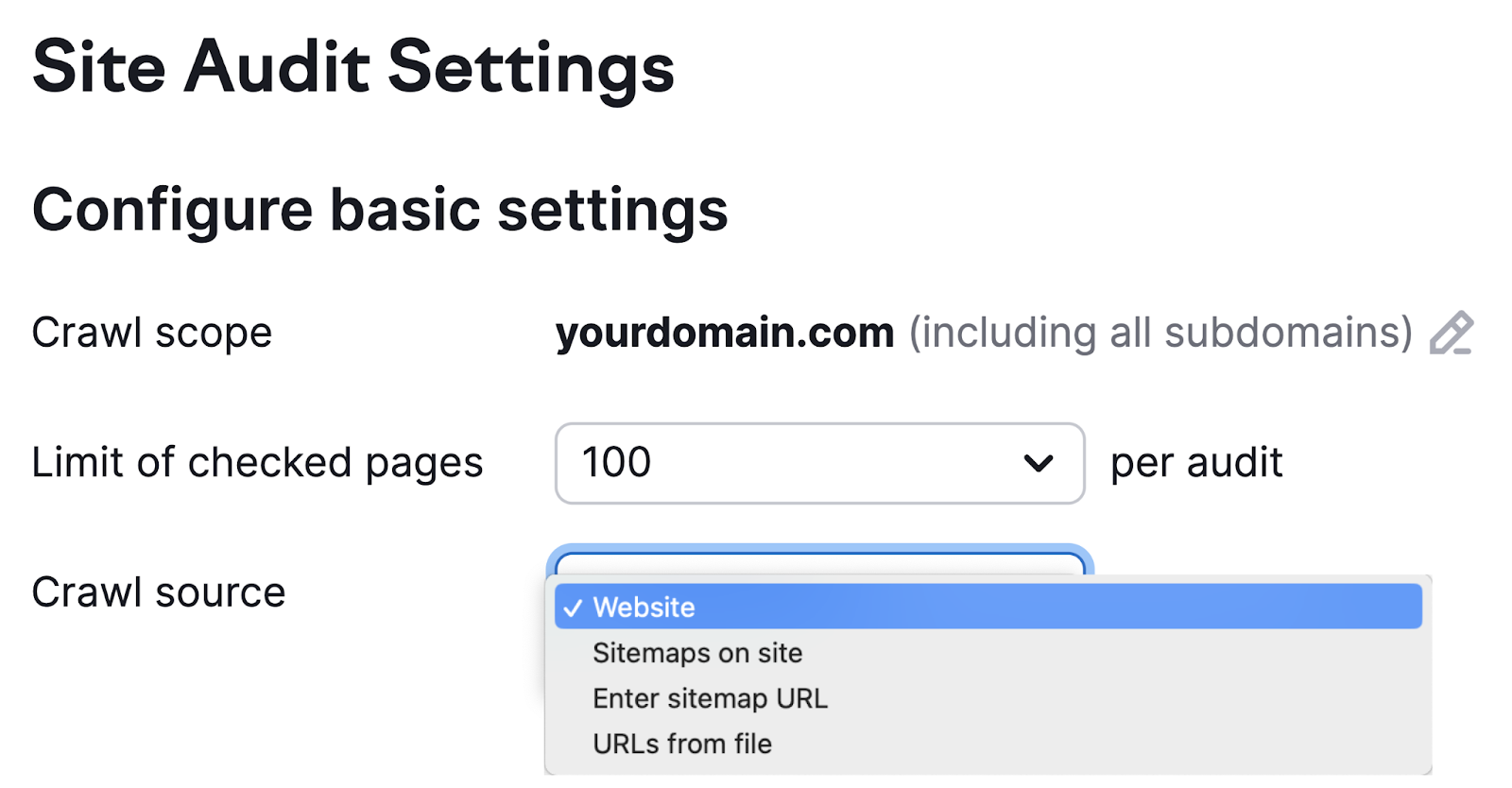
有四个选项:
- 网站:这会启动一个算法,像搜索引擎爬虫一样在您的网站周围传播。 如果您有兴趣抓取网站上最容易从主页访问的页面,这是一个不错的选择。
- 网站地图:这将启动从机器人抓取站点地图中找到的Url。txt文件
- 输入站点地图URL:此源允许您输入自己的站点地图URL,使您的审计更具体
- 来自文件的url:这使您可以非常具体地了解要审核的页面。 您只需要将它们保存为CSV或TXT文件,您可以直接上传到Semrush。 当您不需要一般概述时,此选项非常适合。 例如,当您对特定页面进行了更改并希望查看它们的执行情况时。
设置向导中选项卡2到6上的其余设置是可选的。 但请确保指定您不希望被抓取的网站的任何部分。 并提供登录凭据,如果您的网站受密码保护。
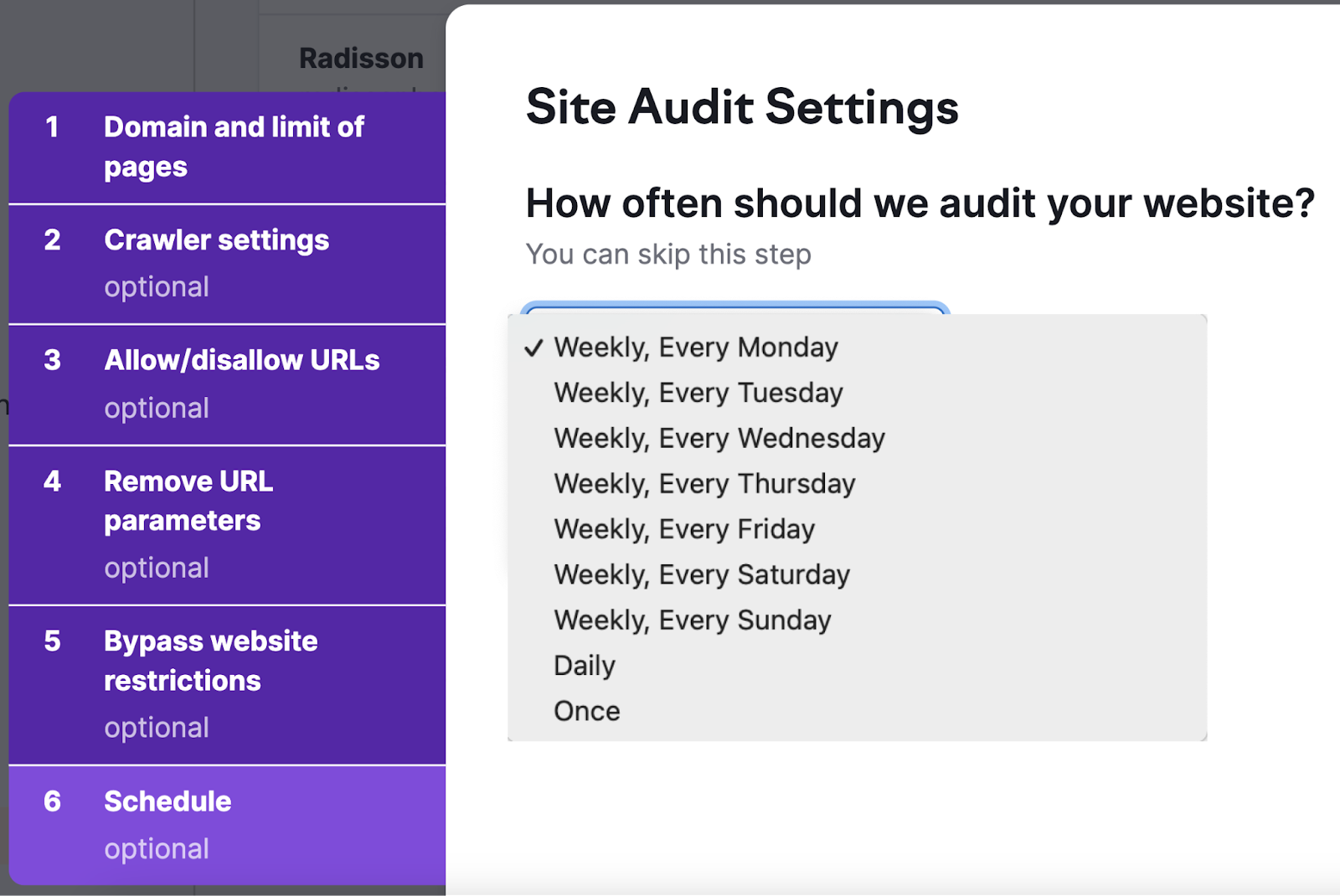
我们亦建议在"时间表"tab。 因为定期审核您的网站可以帮助您监控网站的运行状况并衡量最近更改的影响。
调度选项,包括每周,每天,或只是一次。
最后,点击"开始现场审核"让你的爬行开始。 并且不要忘记单击"每次审核完成时发送电子邮件"旁边的框。"因此,当您的审计报告准备就绪时,您会收到通知。

现在只需等待您的审核完成的电子邮件通知。 然后,您可以开始查看结果。
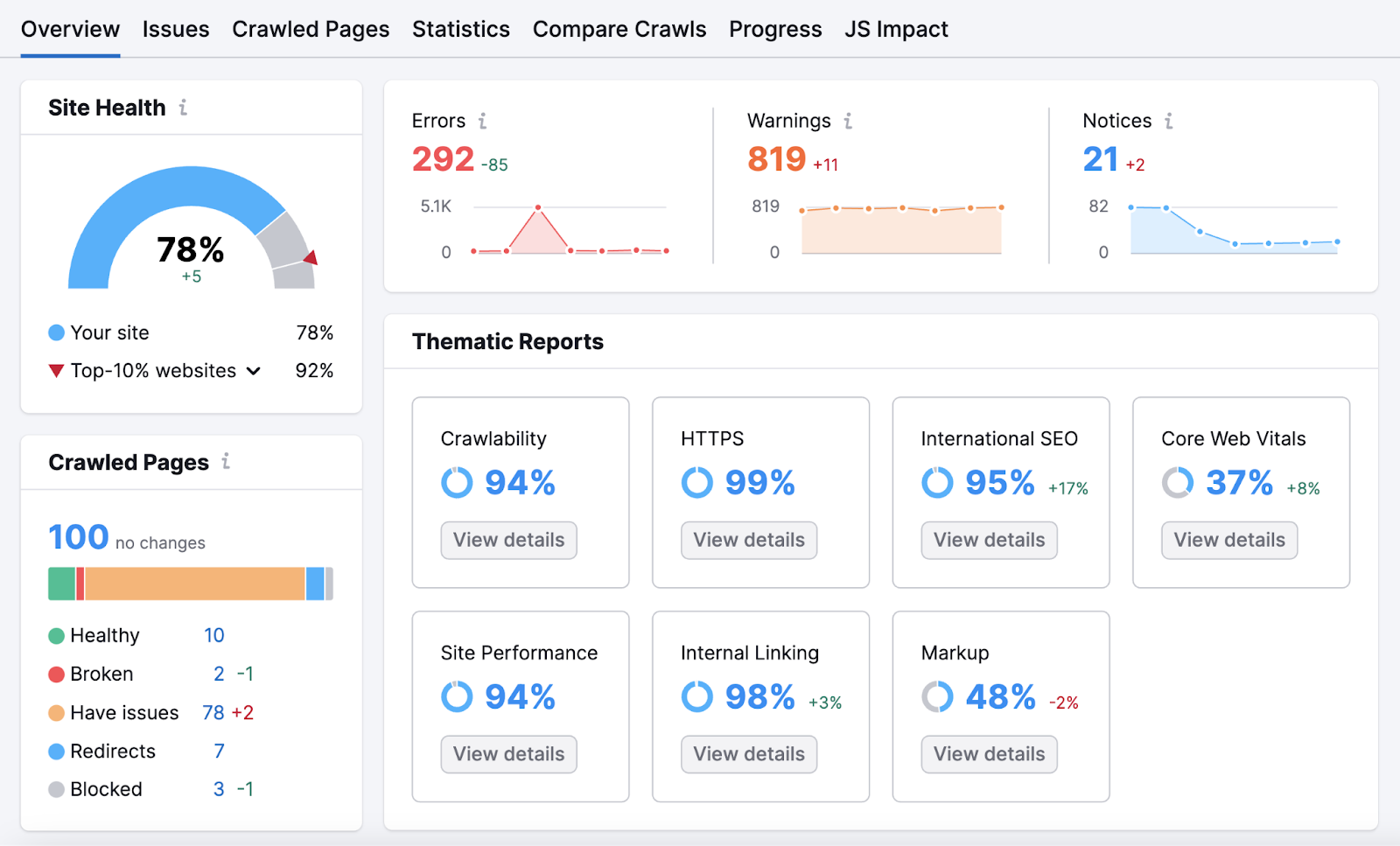
如何评估您的网站抓取数据
进行爬网后,分析结果。 找出你能做些什么来改进。
你可以在现场审核.
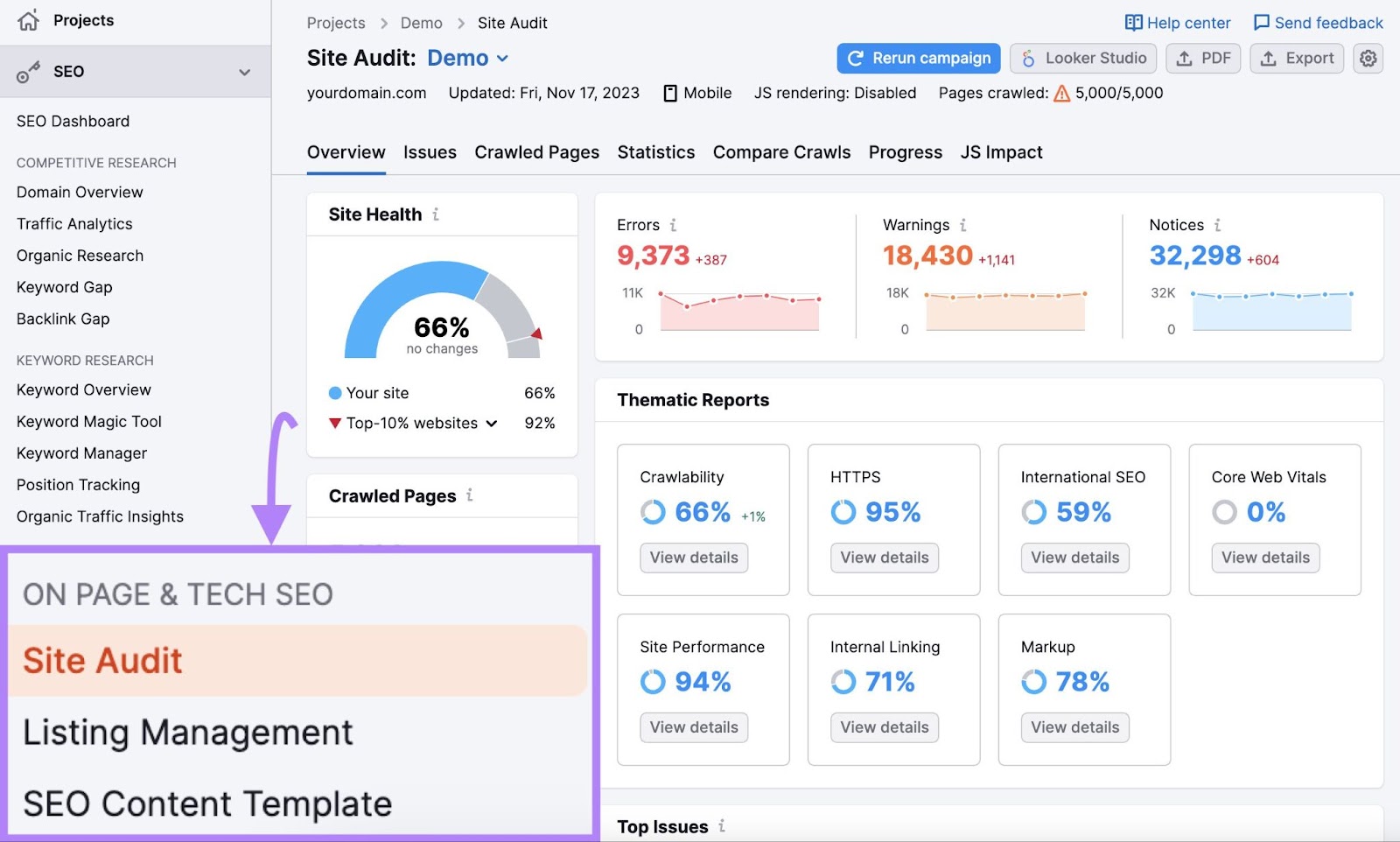
您将被带到"概述"报告。 在那里你可以找到你的"网站健康"分数。 你的分数越高,你的网站就越方便用户和搜索引擎优化.
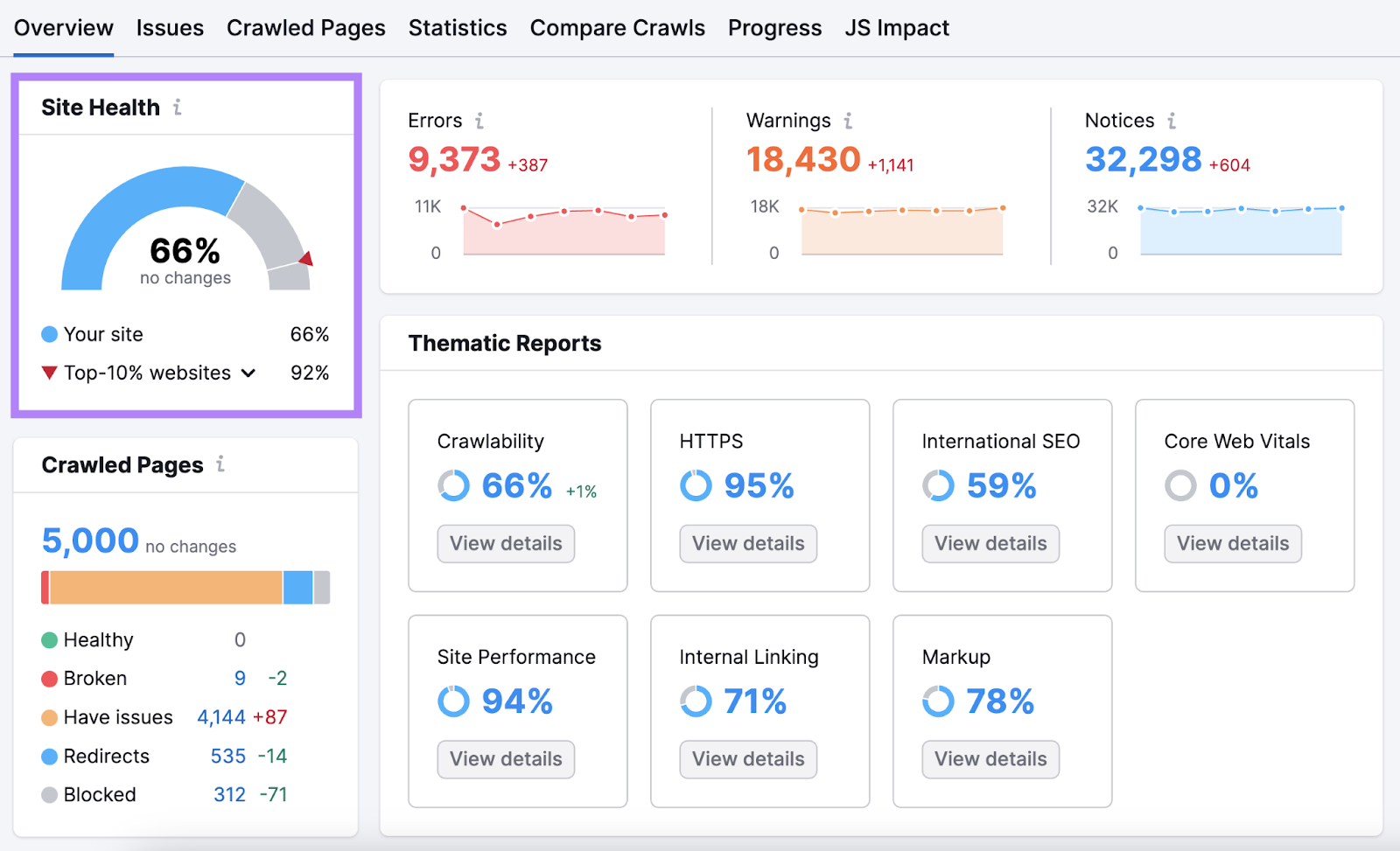
在下面,您将看到已爬网页面的数量。 以及按页面状态分配页面。
向下滚动到"专题报告。"本节详细介绍了核心Web重要功能,内部链接和可抓取性等领域的改进空间。
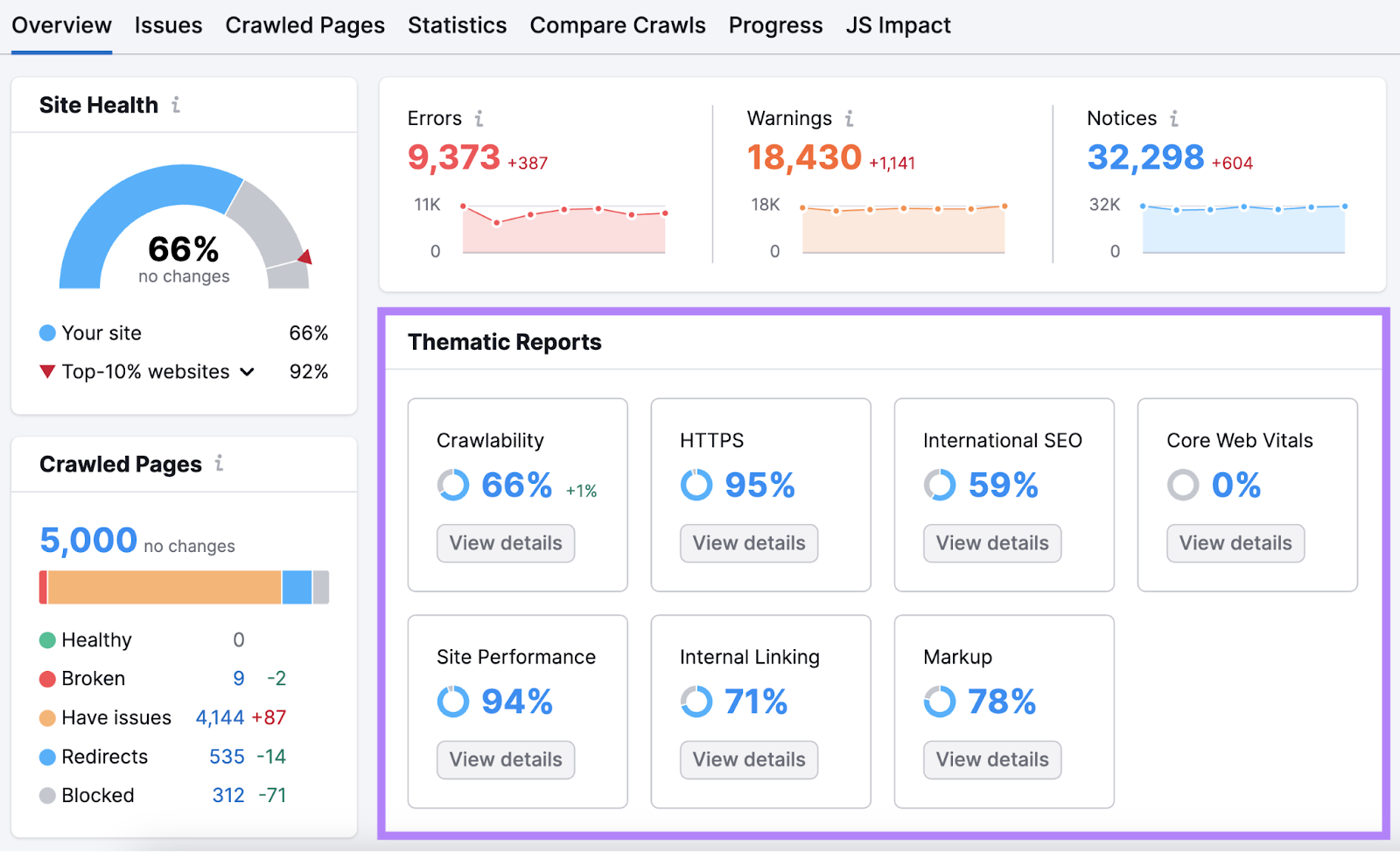
在右边,你会发现"错误"、"警告"和"通知"。"这是按严重程度分类的问题。
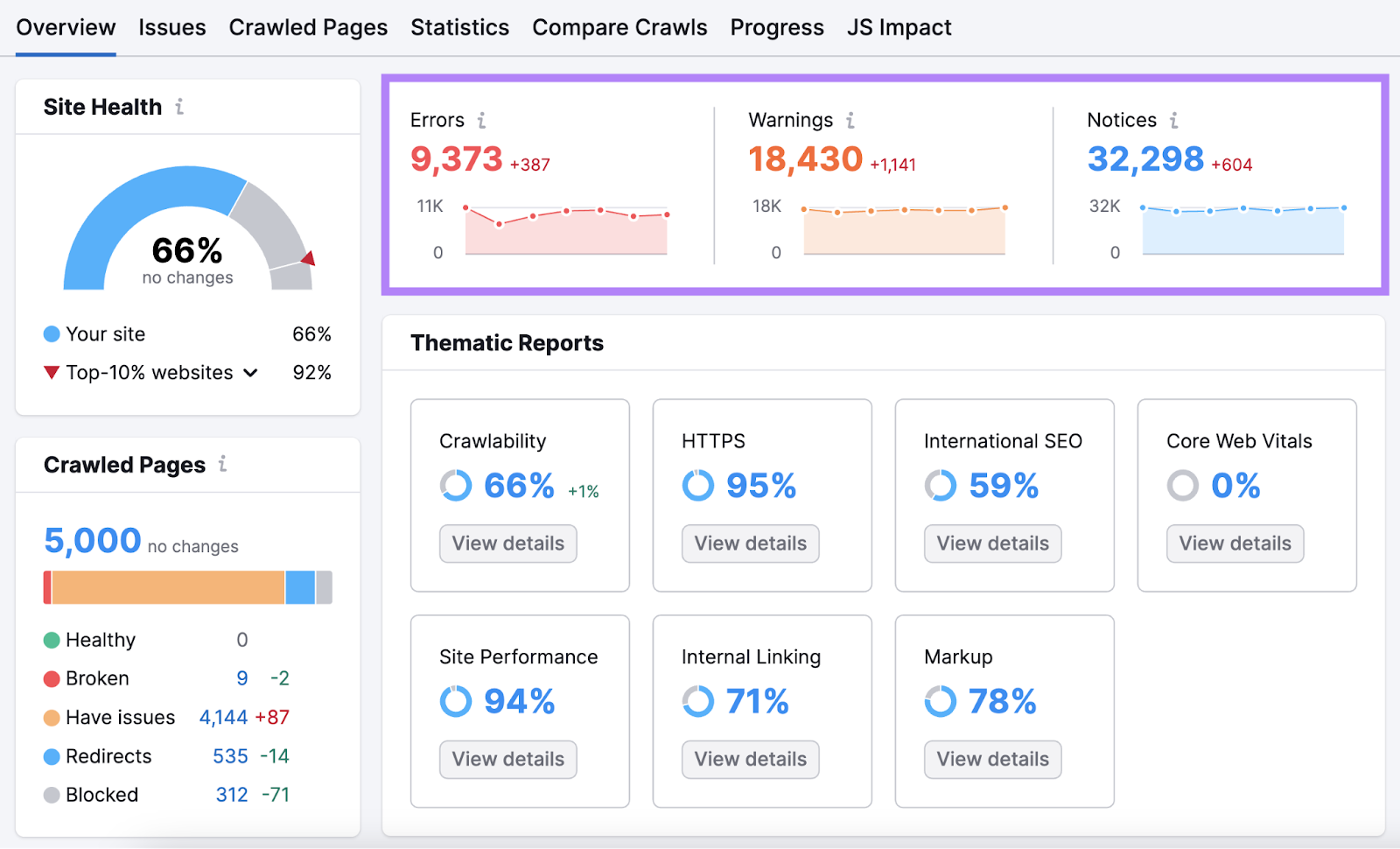
单击"错误"中突出显示的数字以获取最大问题的详细细分。 以及修复它们的建议。
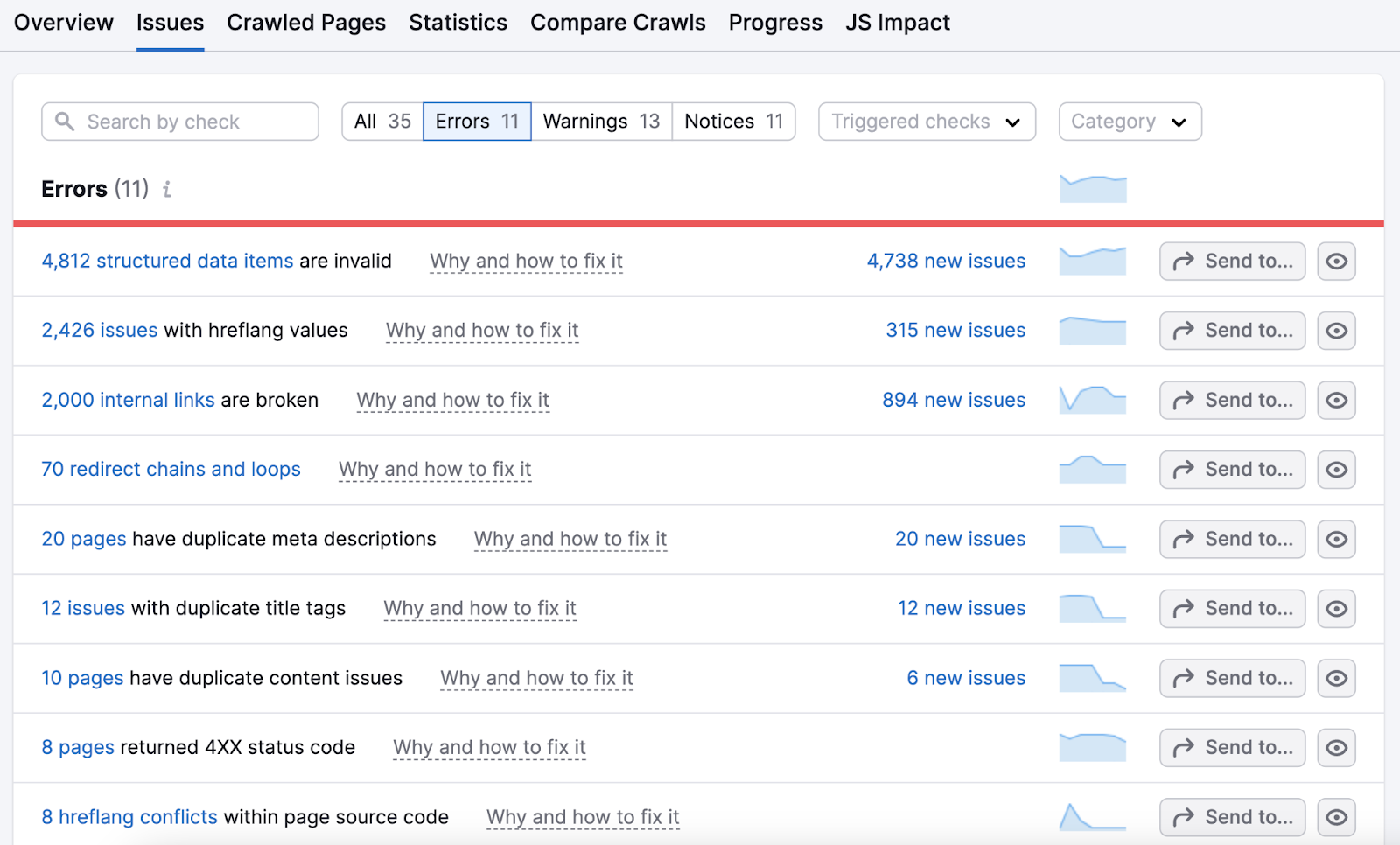
工作你的方式通过这个列表。 然后继续处理警告和通知。
不断爬行以保持领先于竞争对手
像谷歌这样的搜索引擎永远不会停止抓取网页。
包括你的。 还有你的竞争对手。
通过定期抓取您的网站以阻止其轨道上的问题,保持竞争优势。
您可以安排自动回收和报告现场审核. 或者,手动运行未来的网络抓取,以保持您的网站处于最佳状态-从用户和Google的角度来看。