

 外贸B2B建站
外贸B2B建站  高端定制设计
高端定制设计  系统功能优势
系统功能优势 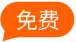


 Google SEO优化
Google SEO优化  Google SEM广告
Google SEM广告  网站内容营销
网站内容营销  优化案例
优化案例  设计赏析
设计赏析  搜索引擎优化
搜索引擎优化  付费广告
付费广告  社媒运营
社媒运营  公司介绍
公司介绍  渠道共赢
渠道共赢  联系我们
联系我们 什么是日志文件?
日志文件是记录向服务器发出的每个请求的文档,无论是由于一个人与您的网站交互还是搜索引擎机器人抓取它(即发现您的页面)。
日志文件可以显示有关以下方面的重要详细信息:
- 请求的时间
- 发出请求的IP地址
- 哪个机器人抓取你的网站(如Googlebot或DuckDuckBot)
- 正在访问的资源类型(如页面或图像)
以下是日志文件的样子:
服务器通常会根据您的设置、相关法规要求和业务需求在有限的时间内存储日志文件。
什么是日志文件分析?
日志文件分析是下载和审核站点日志文件的过程,以主动识别错误、爬网问题和其他问题技术SEO问题。
分析日志文件可以显示Google和其他搜索引擎如何与网站进行交互。 并且还揭示爬网错误这会影响搜索结果中的可见性。
识别日志文件的任何问题可以帮助您开始修复它们的过程。
什么是日志文件分析用于搜索引擎优化?
日志文件分析用于收集数据,您可以使用它来改进您的网站可爬行性-最终你的搜索引擎优化性能。
这是因为它向您展示了像Googlebot这样的搜索引擎机器人如何抓取您的网站。
例如,对日志文件的分析有助于:
- 发现哪些页面搜索引擎机器人抓取最多和最少
- 了解搜索抓取工具是否可以访问您最重要的页面
- 看看是否有低价值的页面在浪费你的爬行预算(即,时间和资源搜索引擎将致力于爬行之前继续前进)
- 检测技术问题,如HTTP状态代码错误(如"错误404页未找到")和损坏重定向阻止搜索引擎访问您的内容
- 用慢发现Url页面速度,这会对你在搜索排名中的表现产生负面影响
- 识别孤儿网页(即,没有指向它们的内部链接的页面),搜索引擎可能会错过
- 跟踪爬网频率的峰值或下降,这可能表明其他技术问题
如何分析日志文件
现在您已经了解了为SEO进行日志文件分析的一些好处,让我们来看看如何去做吧。
你需要:
- 您网站的服务器日志文件
- 访问日志文件分析器
1. 访问日志文件
通过从服务器下载访问您网站的日志文件。
一些托管平台(如Hostinger)有一个内置的文件管理器,您可以在其中查找和下载日志文件。
以下是如何做到这一点。
从仪表板或控制面板中,查找名为"文件管理"、"文件"、"文件管理器"或类似内容的文件夹。
下面是该文件夹在Hostinger上的样子:
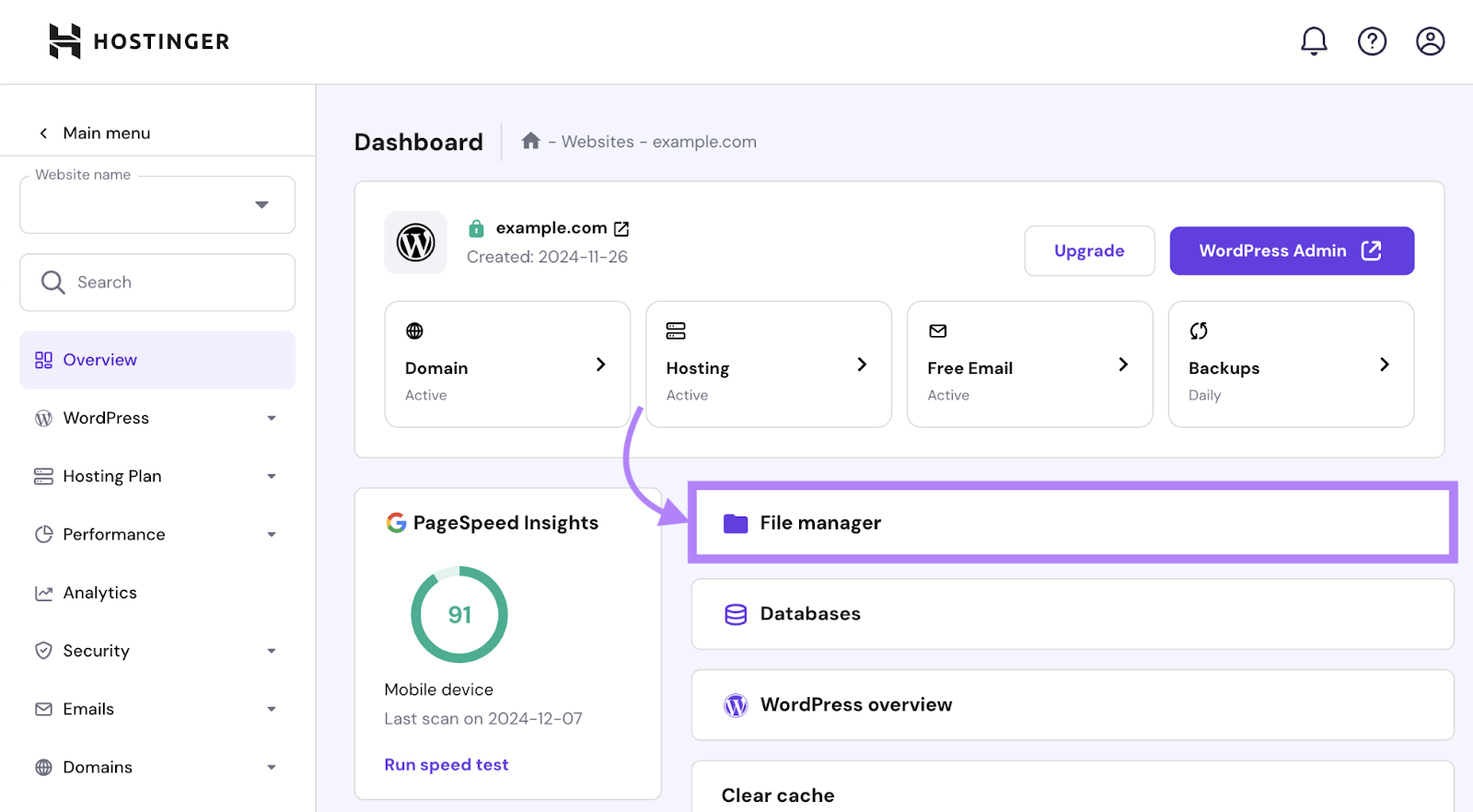
只需打开文件夹,找到您的日志文件(通常在"。日志"文件夹),并下载所需的文件。
或者,您的开发人员或IT专家可以访问服务器并通过文件传输协议(FTP)客户端下载文件,如菲利齐拉.
一旦你下载了你的日志文件,它的时间来分析它们。
2. 分析日志文件
您可以使用Google表格和其他工具手动分析日志文件,但这个过程可能会很快变得既烦人又混乱。
这就是为什么我们建议使用Semrush的日志文件分析器.
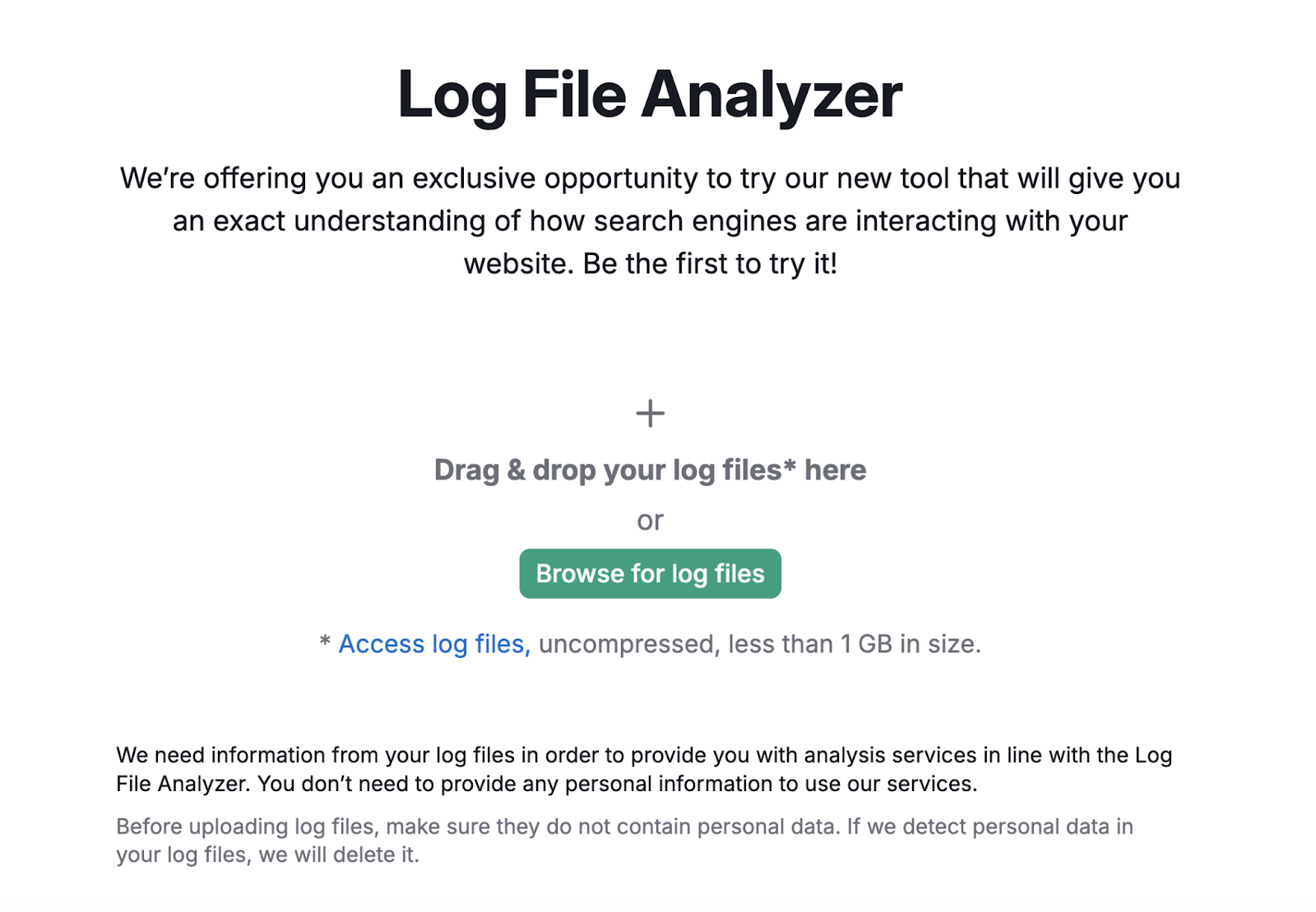
首先,确保您的日志文件是未归档的,并且在访问中。日志、W3C或Kinsta文件格式。
然后,将文件拖放到工具中。 并点击"启动日志文件分析器.”
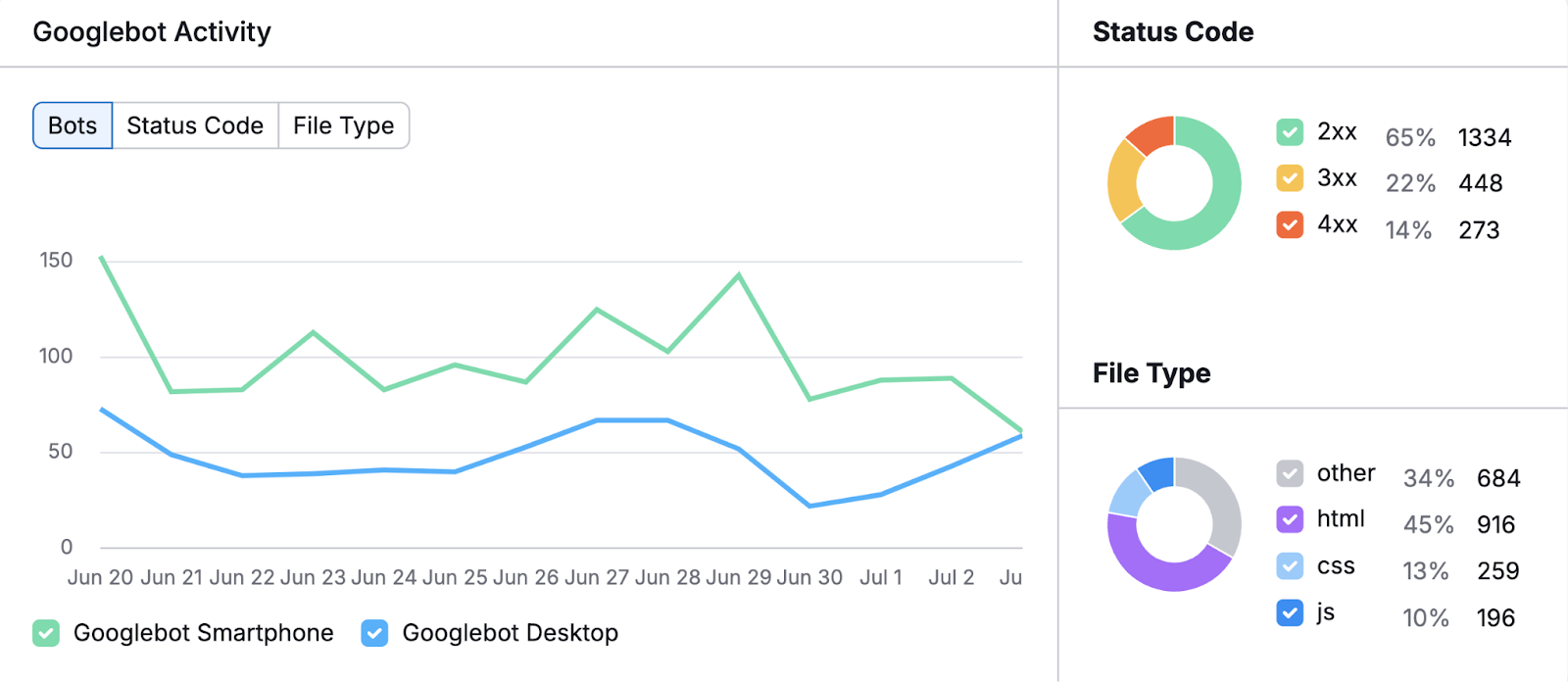
一旦您的结果准备就绪,您将看到一个图表,显示过去30天的Googlebot活动。
监控此图表以发现任何异常的活动高峰或下降,这可能表明搜索引擎如何抓取您的网站或需要修复的问题的变化。
在图表的右边,你还会看到:
- HTTP状态代码:这些代码显示搜索引擎和用户是否可以成功访问您网站的页面。 例如,太多的4xx错误可能表明您应该修复的链接断开或缺少页面。
- 已爬网的文件类型:了解搜索引擎机器人花费多少时间抓取不同的文件类型显示了搜索引擎如何与您的内容进行交互。 这有助于您确定他们是否在不必要的资源(例如JavaScript)上花费了太多时间,而不是优先考虑重要内容(例如HTML)。
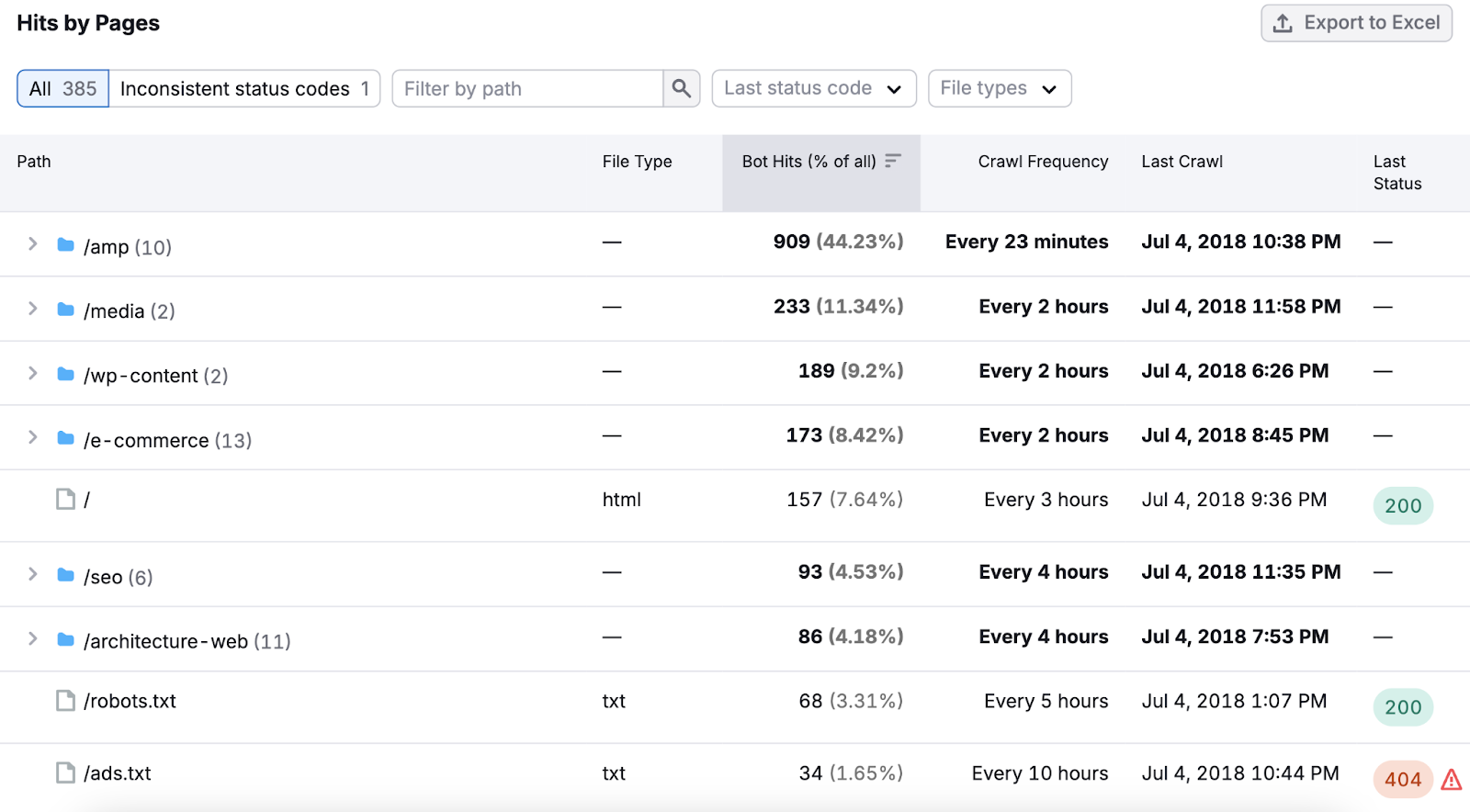
向下滚动到"按页点击"以获得更具体的见解。 这份报告将向你展示:
- 搜索引擎机器人最常抓取哪些页面和文件夹
- 搜索引擎机器人抓取这些页面的频率
- 像404S这样的HTTP错误
按"排序表爬网频率"以查看Google如何分配您的抓取预算。
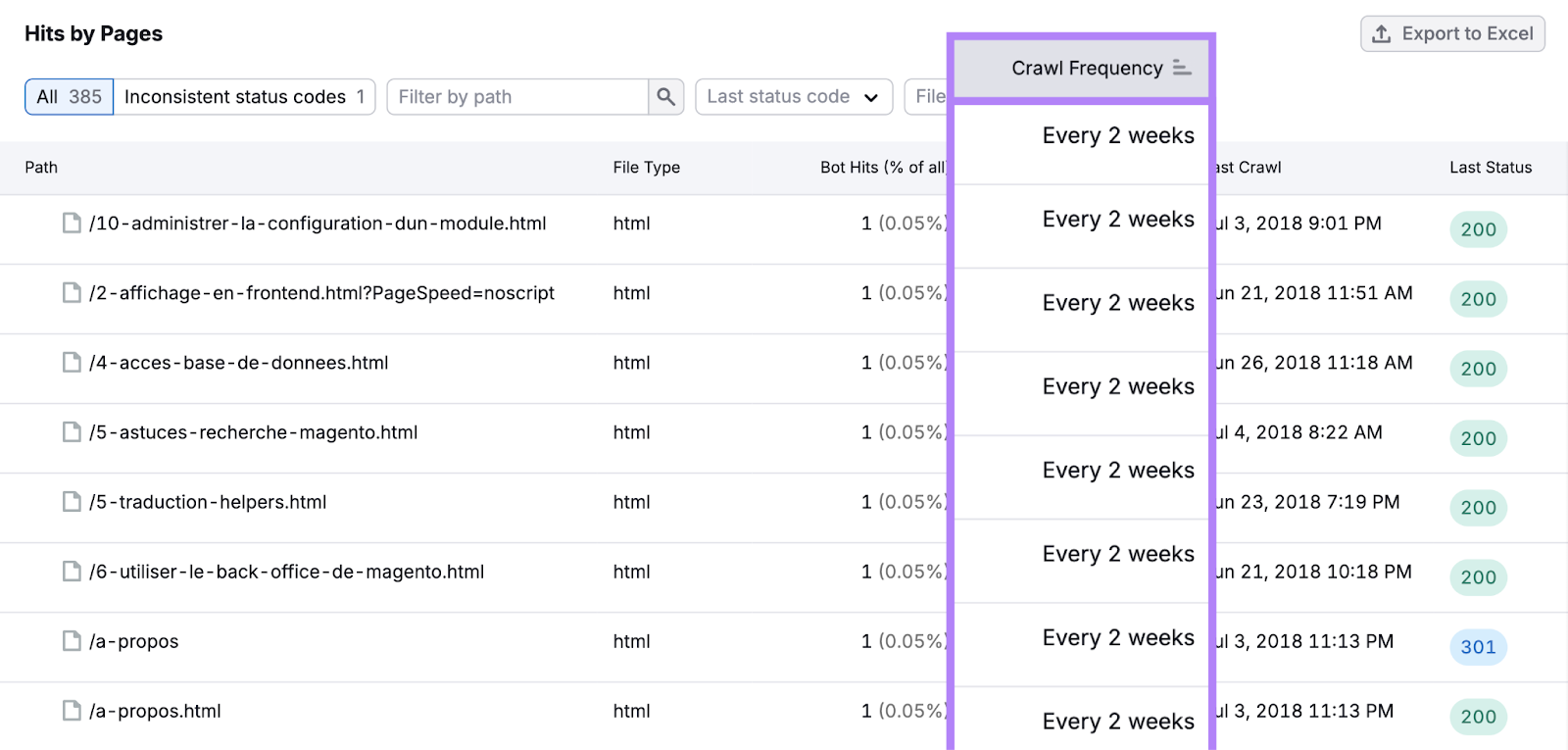
或者,点击"状态代码不一致"按钮以查看状态代码不一致的路径(URL的特定路径)。

例如,404状态码(意味着找不到页面)和301状态码(永久重定向)之间的路径切换可能会发出错误配置或其他问题的信号。
特别注意你最重要的网页。 并使用您获得的有关它们的见解进行调整,以提高您在搜索结果中的性能。
优先考虑站点可抓取性
现在您知道如何访问和分析日志文件。
但不要就此止步。
采取主动步骤,确保您的网站针对可抓取性进行了优化。
确保做到这一点的一种方法是使用Semrush进行技术SEO审计现场审核工具。
首先,打开工具并按照我们的配置指南. (或者坚持使用默认设置。)
一旦您的报告准备好,您将看到一个概述页面,突出显示您的网站最重要的技术搜索引擎优化问题和需要改进的领域。
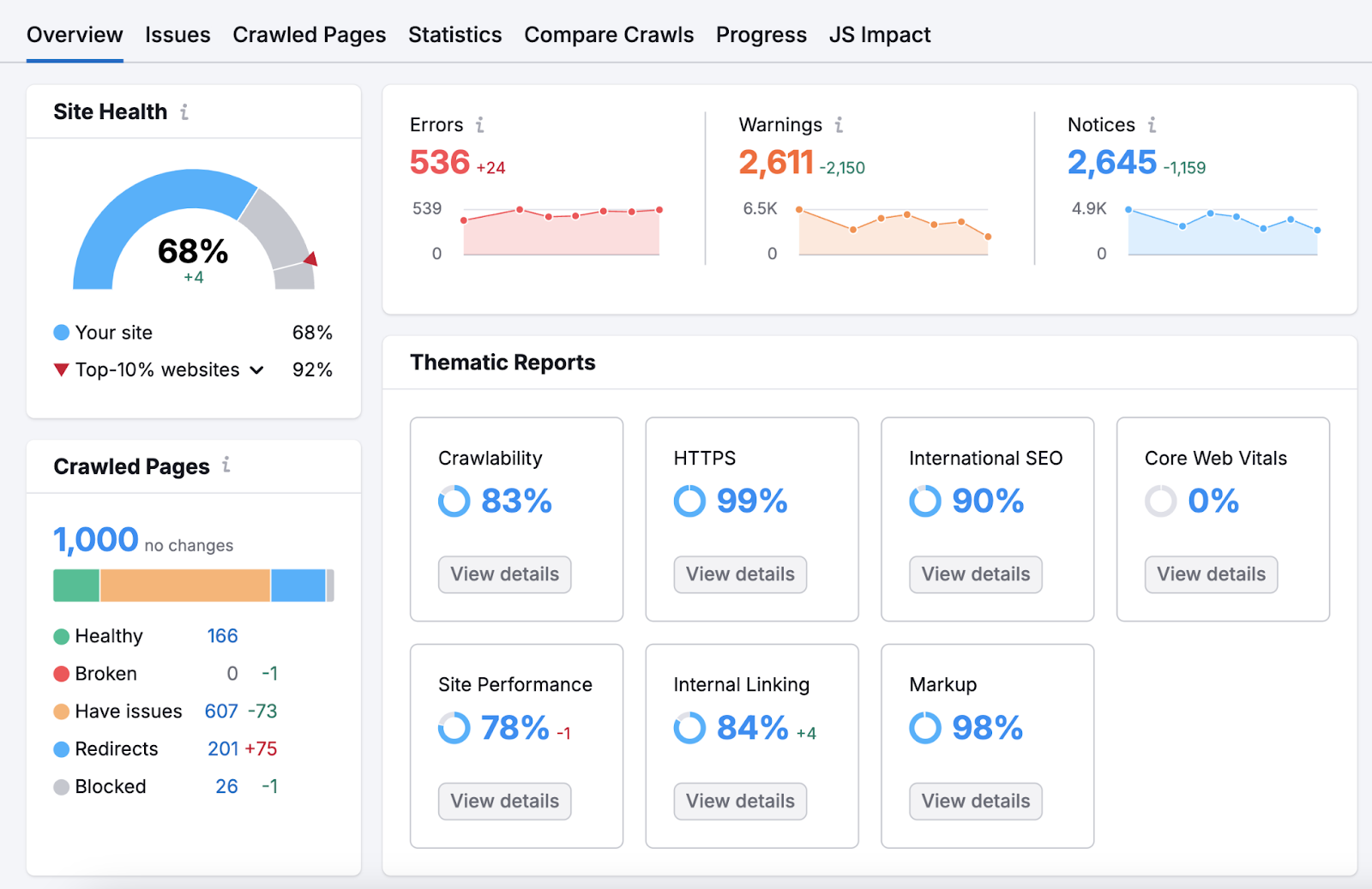
前往"问题"选项卡并选择"可爬行性"在"类别:"下拉。
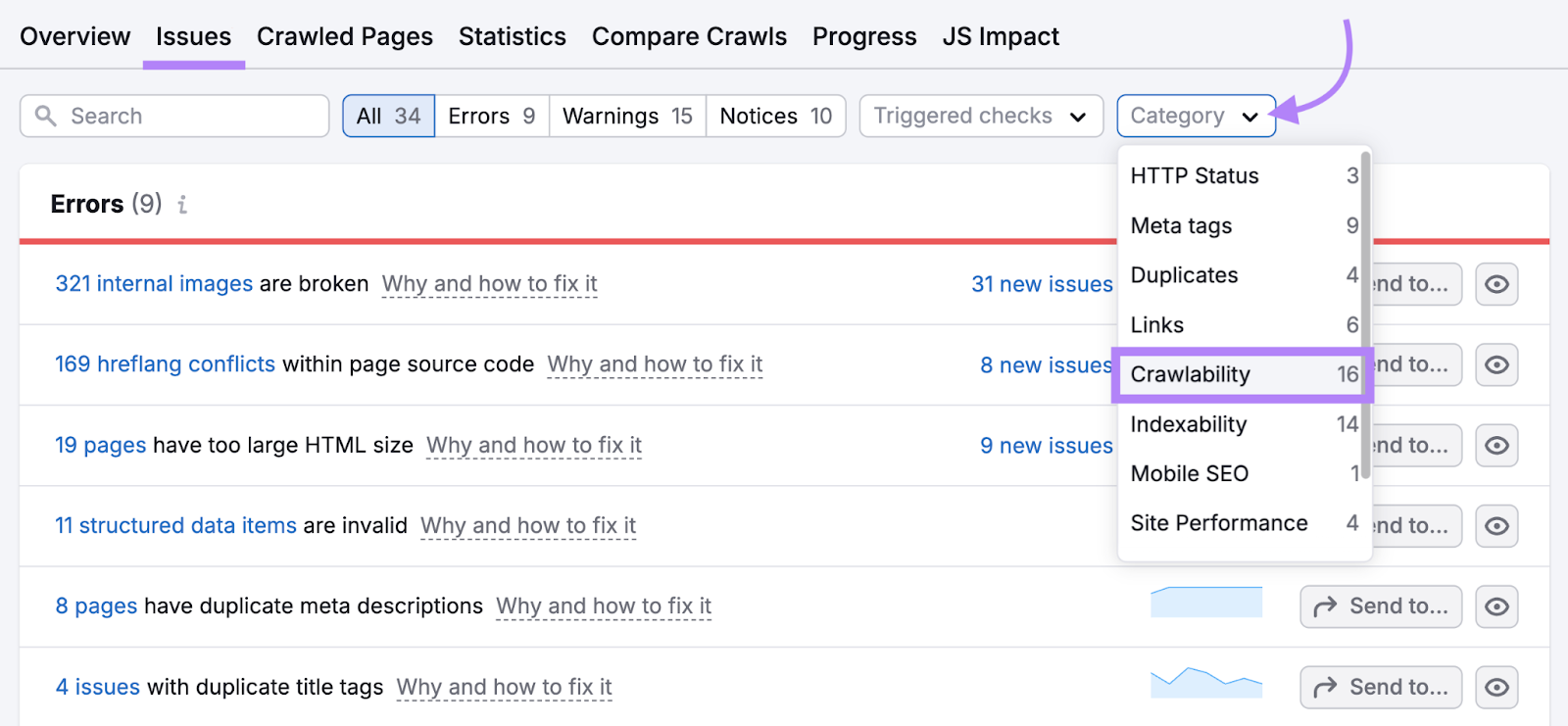
您将看到影响网站可抓取性的问题列表。
如果您不知道问题的含义或如何解决问题,请单击"为什么以及如何解决它"了解更多。
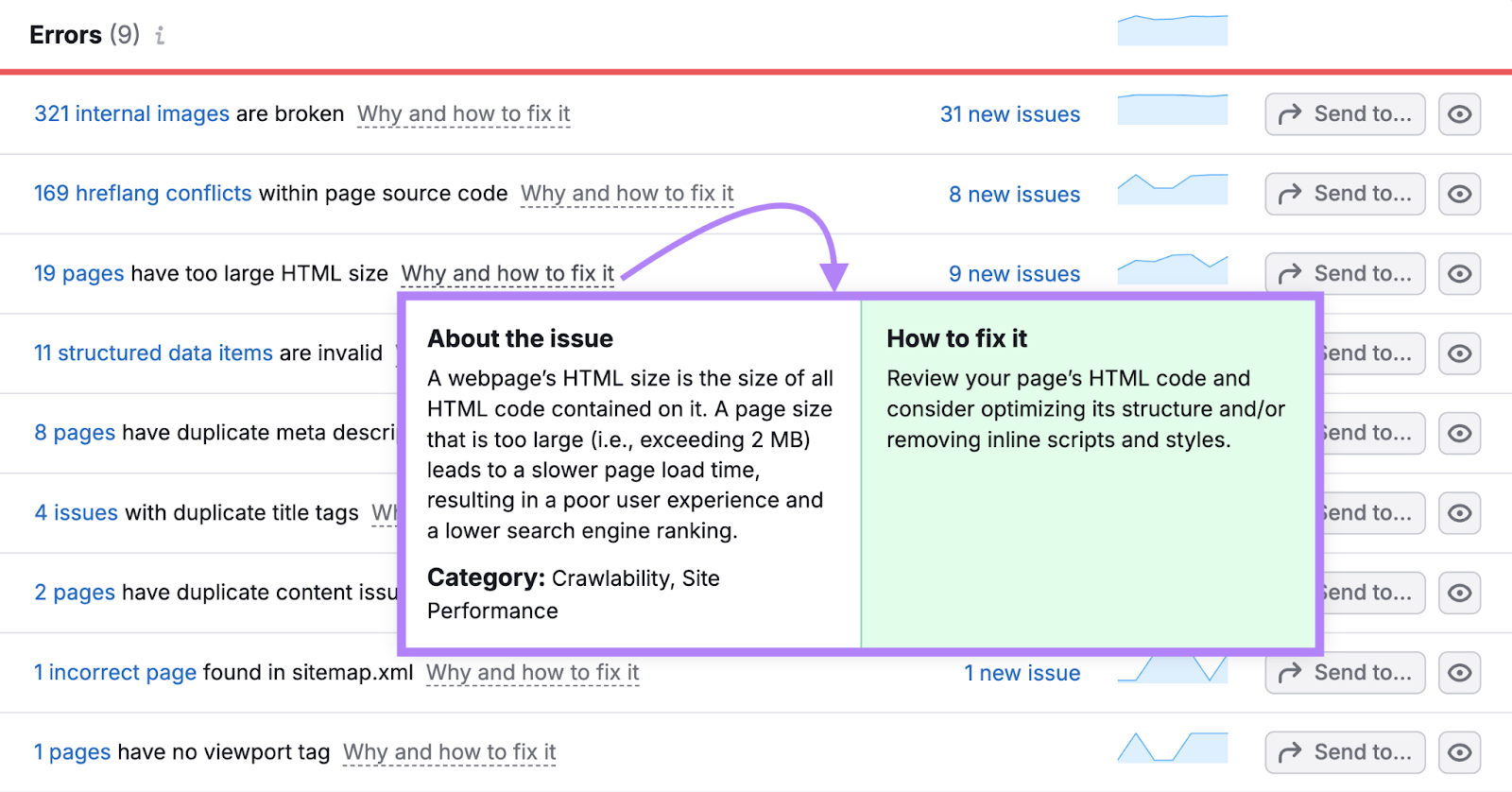
每月运行这样的站点审核。 并解决任何弹出的问题,无论是你自己还是与开发人员合作。