

 外贸B2B建站
外贸B2B建站  高端定制设计
高端定制设计  系统功能优势
系统功能优势 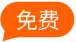


 Google SEO优化
Google SEO优化  Google SEM广告
Google SEM广告  网站内容营销
网站内容营销  优化案例
优化案例  设计赏析
设计赏析  搜索引擎优化
搜索引擎优化  付费广告
付费广告  社媒运营
社媒运营  公司介绍
公司介绍  渠道共赢
渠道共赢  联系我们
联系我们 什么是Googlebot?
Googlebot是Google用于自动抓取(或访问)网页的主要程序。 发现他们身上有什么。
作为谷歌的主要网站爬虫,它的目的是保持谷歌庞大的内容数据库,被称为索引,最新。
因为这个索引越是最新和全面,你的搜索结果就越好,越相关。
Googlebot有两个主要版本:
- Googlebot智能手机:主要的Googlebot网络爬虫。 它抓取网站,就好像它是移动设备上的用户一样。
- Googlebot桌面:这个版本的Googlebotcrawls网站,就好像它是桌面计算机上的用户一样。 检查网站的桌面版本。
还有更具体的爬虫,如Googlebot Image,Googlebot Video和Googlebot News。
为什么Googlebot对SEO很重要?
Googlebot对于谷歌搜索引擎优化因为没有它,你的页面就不会被抓取和索引(在大多数情况下)。 如果您的页面未编入索引,则无法在搜索引擎结果页面(Serp)中对其进行排名和显示。
没有排名意味着没有自然(未付费)搜索流量。
此外,Googlebot会定期重新访问网站以检查更新。
没有它,新的内容或对现有页面的更改将不会反映在搜索结果中。 不保持您的网站最新可能会使您在搜索结果中保持可见性变得更加困难。
Googlebot如何工作
Googlebot通过抓取网页并发送要索引的数据,帮助Google在Serp中提供相关和准确的结果。
让我们更仔细地看一下爬网和索引阶段:
爬行网页
爬行是发现和探索网站以收集信息的过程。 谷歌的分析师Gary Illyes在这段视频中解释了这个过程:

Googlebot不断地在互联网上爬行,以发现新的和更新的内容。
它维护一个不断更新的网页列表。 包括那些在以前的抓取过程中发现的以及新的站点。
这个列表就像Googlebot的个人冒险地图。 指导它下一步去哪里探索。
因为Googlebot还遵循页面之间的链接,以不断发现新的或更新的内容。
像这样:

一旦Googlebot发现一个页面,它可能会访问并获取(或下载)其内容。
然后,Google可以呈现(或视觉处理)页面。 模拟真实用户如何看到和体验它。
在渲染阶段,Google会运行它找到的任何JavaScript。 JavaScript是允许您向网页添加交互式和响应式元素的代码。
呈现JavaScript可以让Googlebot以类似于用户查看内容的方式查看内容。
打开该工具,插入您的域,然后单击"开始审核.”
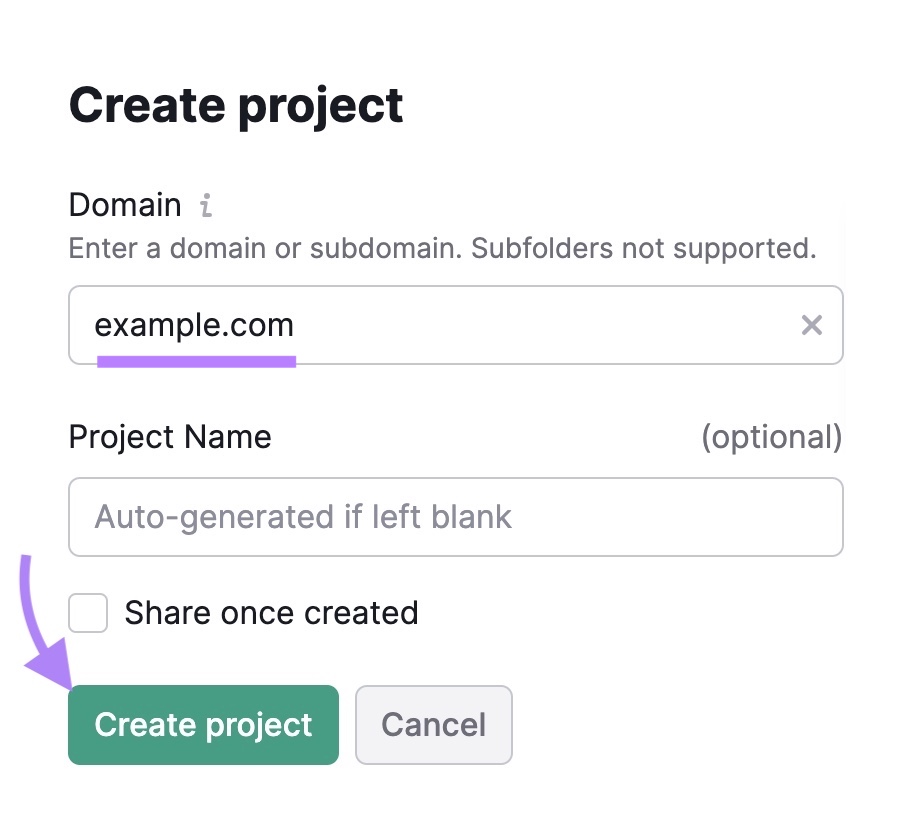
如果您已经运行了审核或创建了项目,请单击"+创建项目"按钮设置一个新的。
输入您的域名,为您的项目命名,然后单击"创建项目.”
接下来,系统会要求您配置设置。
如果您刚刚开始,则可以使用"域和页面限制"部分中的默认设置。
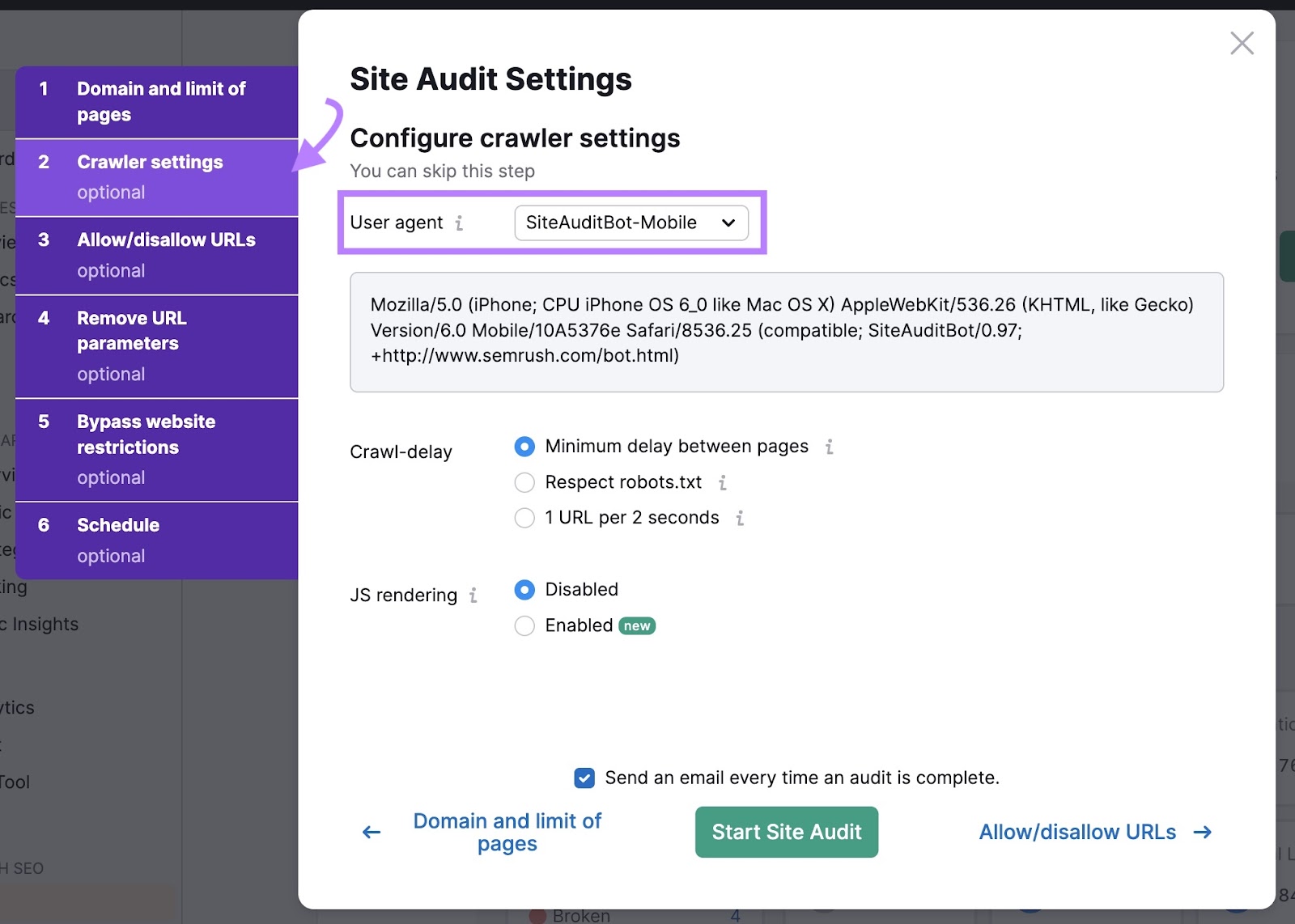
然后,点击"爬虫设置"选项卡选择您想要爬网的用户代理。 用户代理是一个标签,告诉网站谁在访问他们。 就像搜索引擎机器人的名称标签。
您可以选择的机器人之间没有重大区别。 它们都是为了像Googlebot一样抓取您的网站而设计的。
查看我们的网站审核配置指南有关如何自定义审核的更多详细信息。
当你准备好了,点击"开始现场审核.”
然后,您将看到如下所示的概述页面。 导航到"问题"tab。
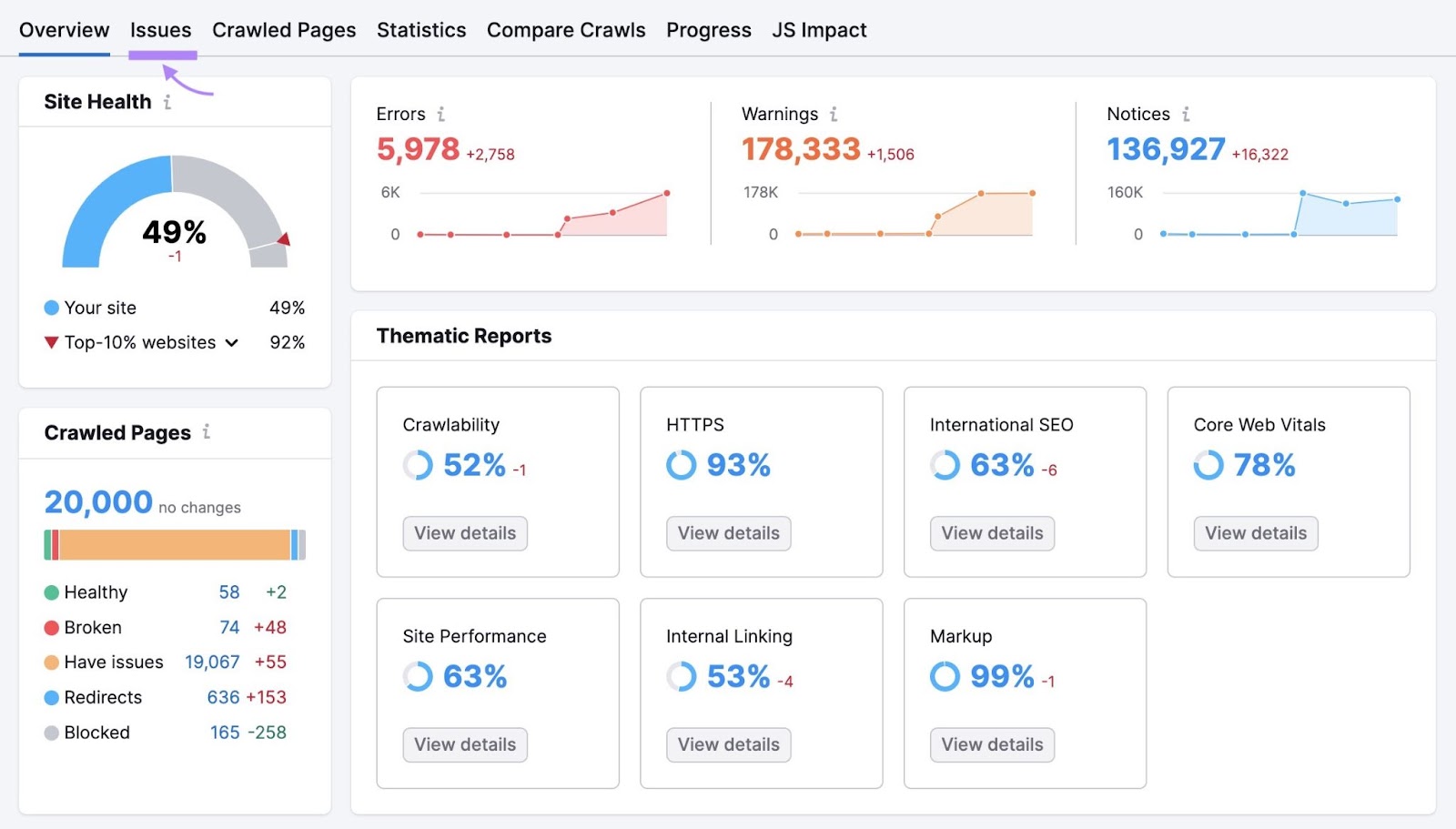
在这里,您将看到影响网站运行状况的错误、警告和通知的完整列表。
点击"类别:"下拉选择"可爬行性"来过滤错误。
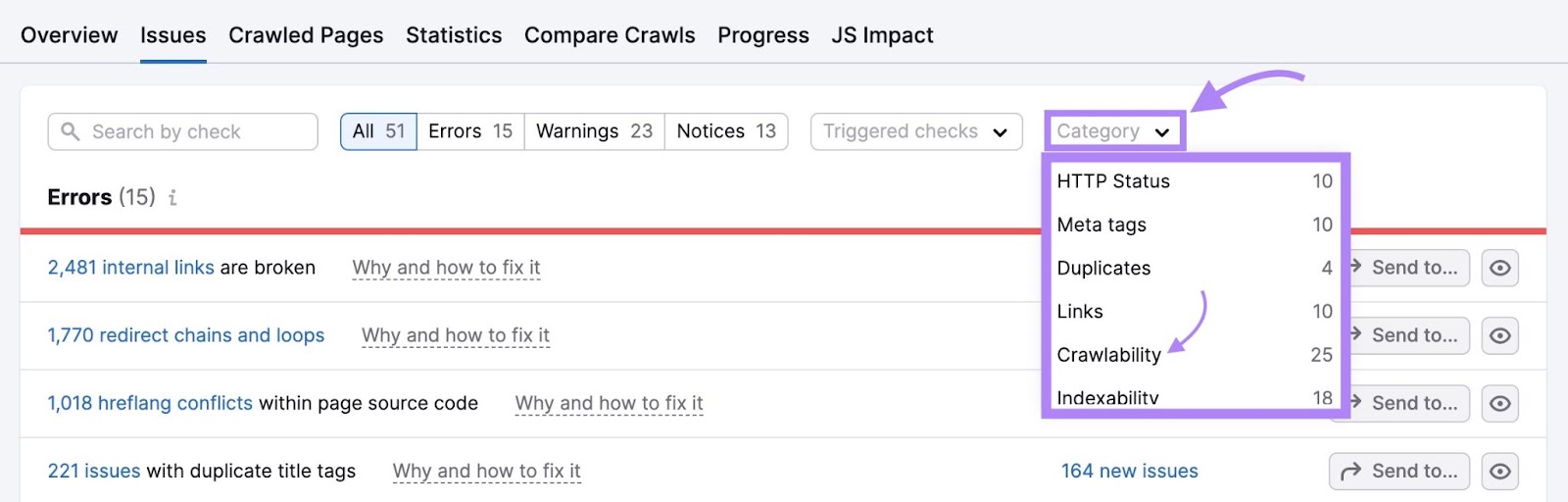
不确定错误是什么意思以及如何解决它?
点击"为什么以及如何解决它"或"了解更多"旁边的任何行的问题和如何解决它的提示的简短解释。
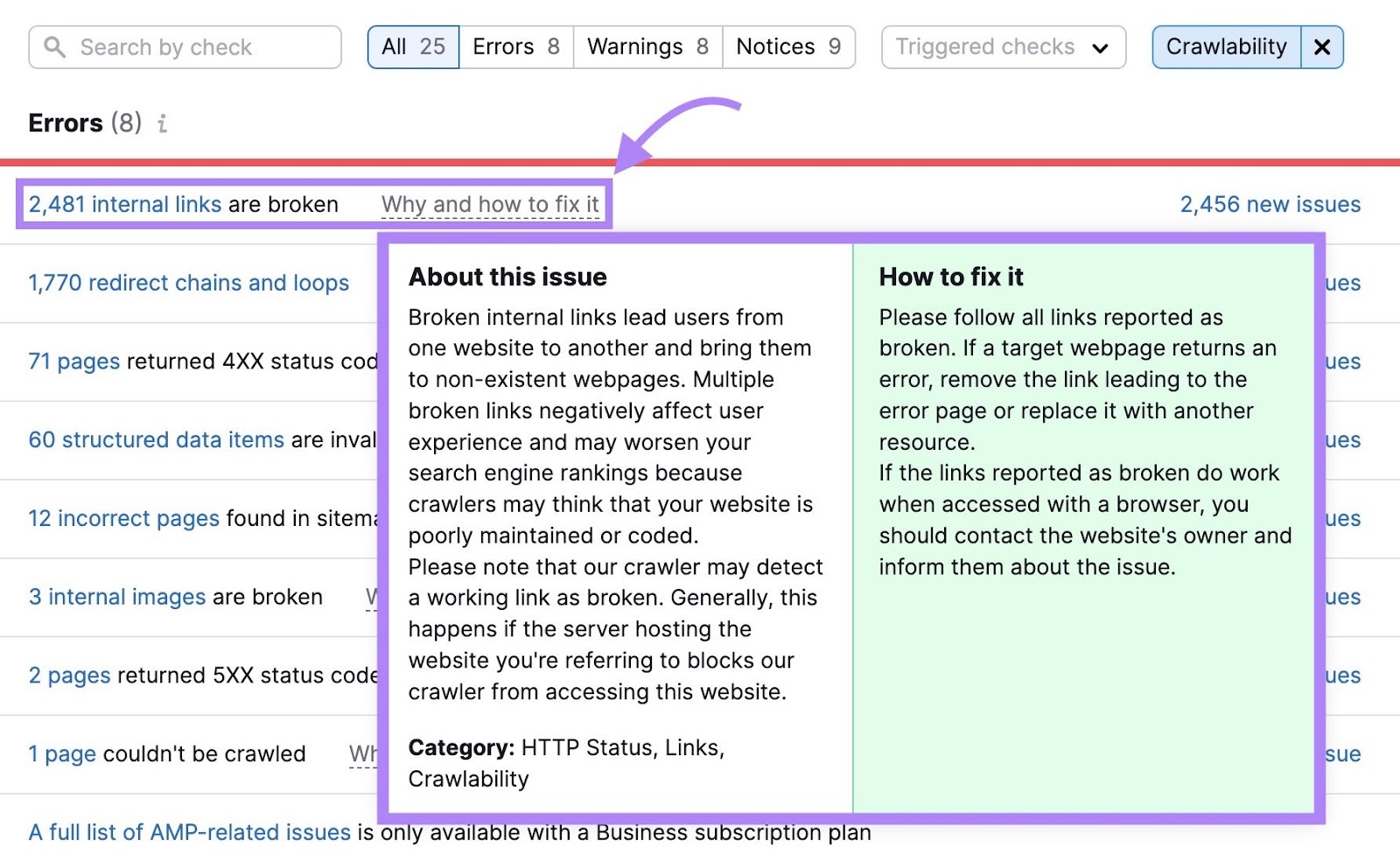
通过并修复每个问题,使Googlebot更容易抓取您的网站。
索引内容
GoogleBot抓取您的内容后,它会将其发送以供索引考虑。
索引是分析页面以了解其内容的过程。 并评估相关性和质量等信号,以决定是否应将其添加到Google的索引中。
以下是Google的Gary Illyes如何解释这个概念:
在此过程中,Google会处理(或检查)页面的内容。 并试图确定一个页面是否是互联网上另一个页面的重复。 因此,它可以选择在其搜索结果中显示哪个版本。
一旦Google过滤掉重复项并评估相关信号(如内容质量),它可能会决定为您的页面编制索引。
然后,谷歌的算法执行该过程的排名阶段。 确定您的内容是否应该在搜索结果中以及在何处出现。
从"问题"选项卡中,筛选"可索引性."先克服错误。 无论是自己还是在开发人员的帮助下。 然后,处理警告和通知。
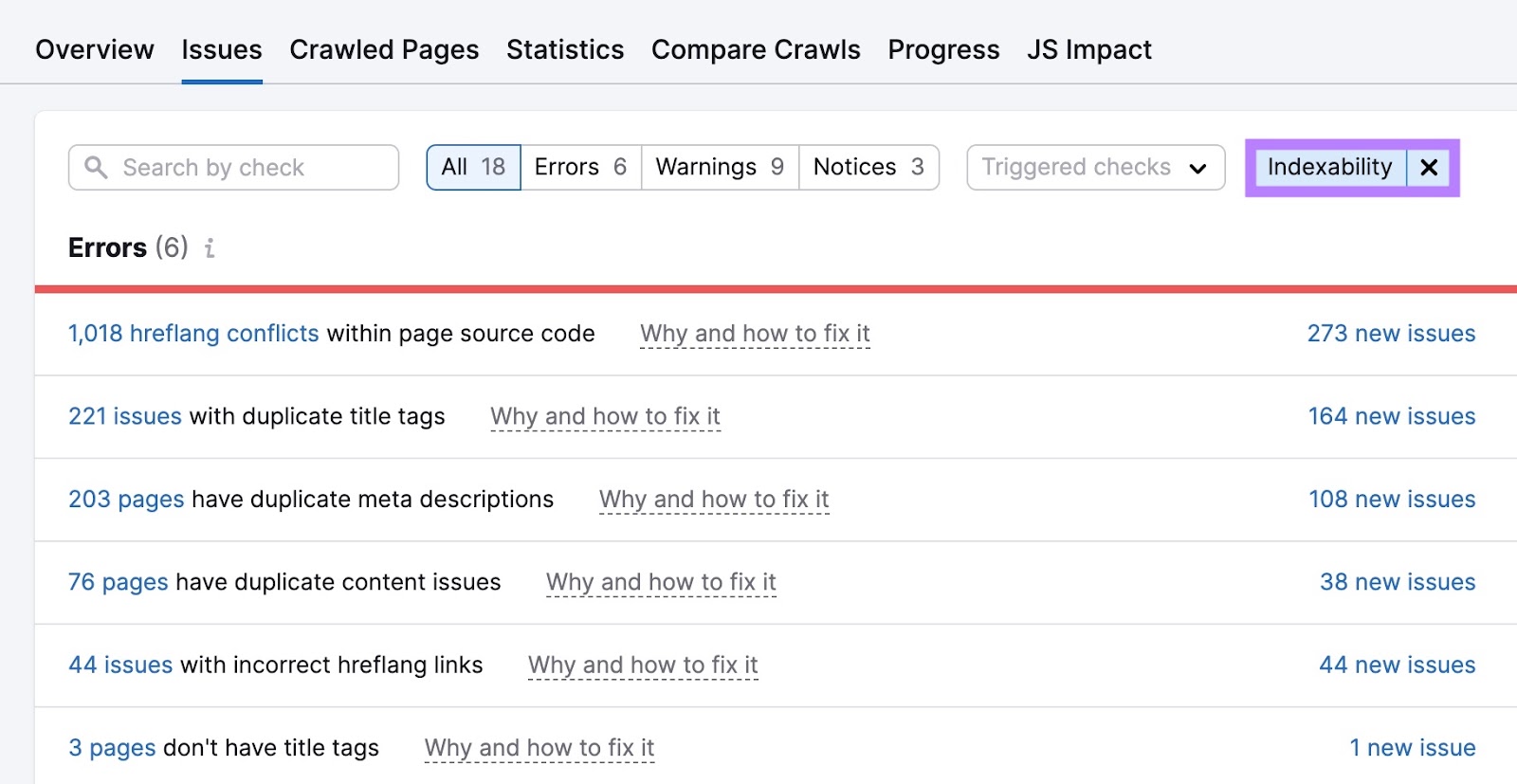
进一步阅读: 可抓取性和可索引性:它们是什么以及它们如何影响SEO
如何监控Googlebot的活动
定期检查Googlebot的活动可以让您发现任何可转位性和可抓取性问题. 并在您的网站的自然可见性下降之前修复它们。
这里有两种方法可以做到这一点:
使用Google Search Console的抓取统计报告
使用Google Search Console的"爬行统计"报告您的网站的爬网活动的概述。 包括有关爬网错误和平均服务器响应时间。
要访问您的报告,请登录Google Search Console属性并导航到"设置"从左侧菜单。
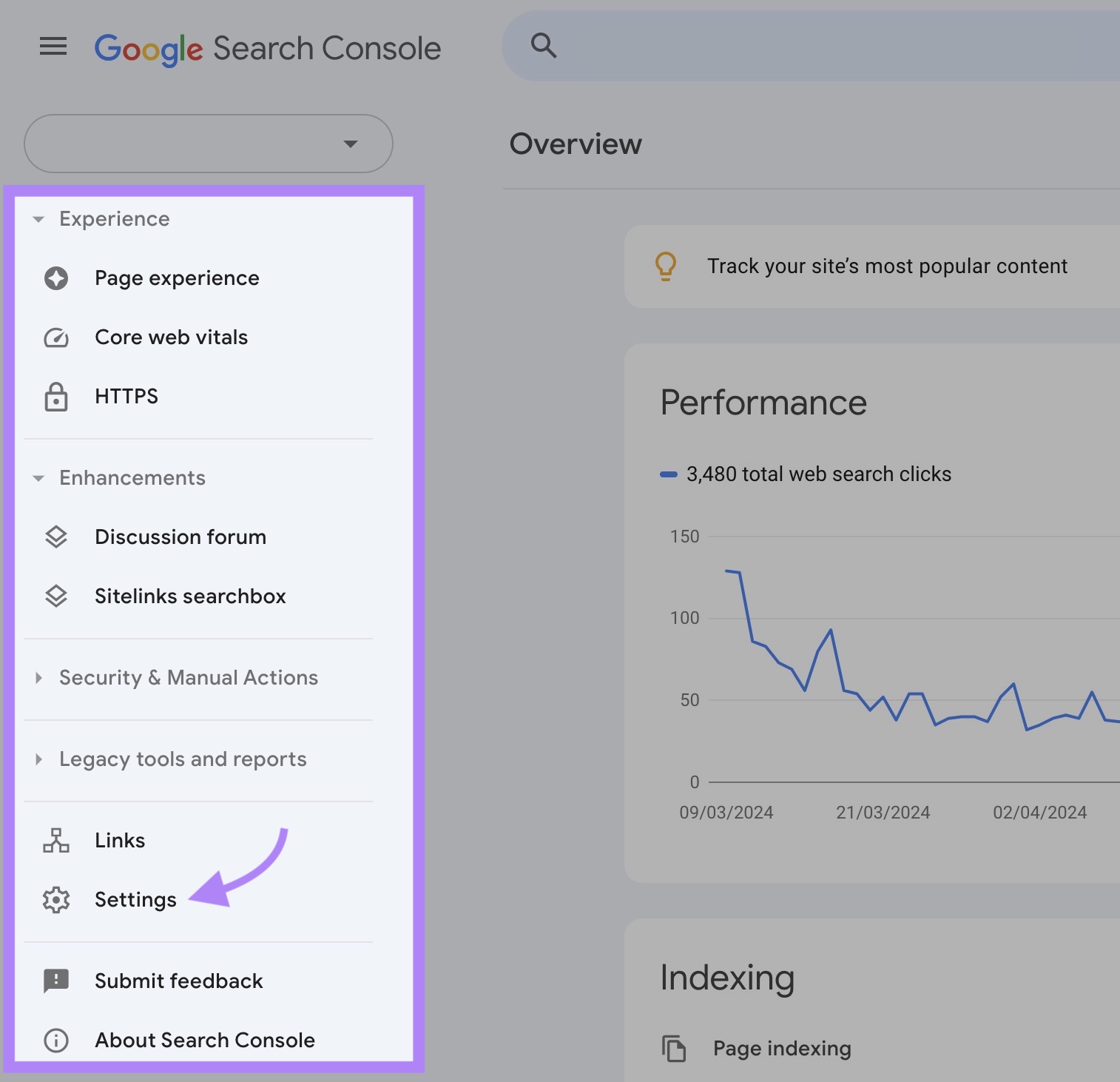
向下滚动到"爬行"部分。 然后,点击"公开报告"抓取统计"行中的按钮。
您将看到三个爬行趋势图表。 像这样:
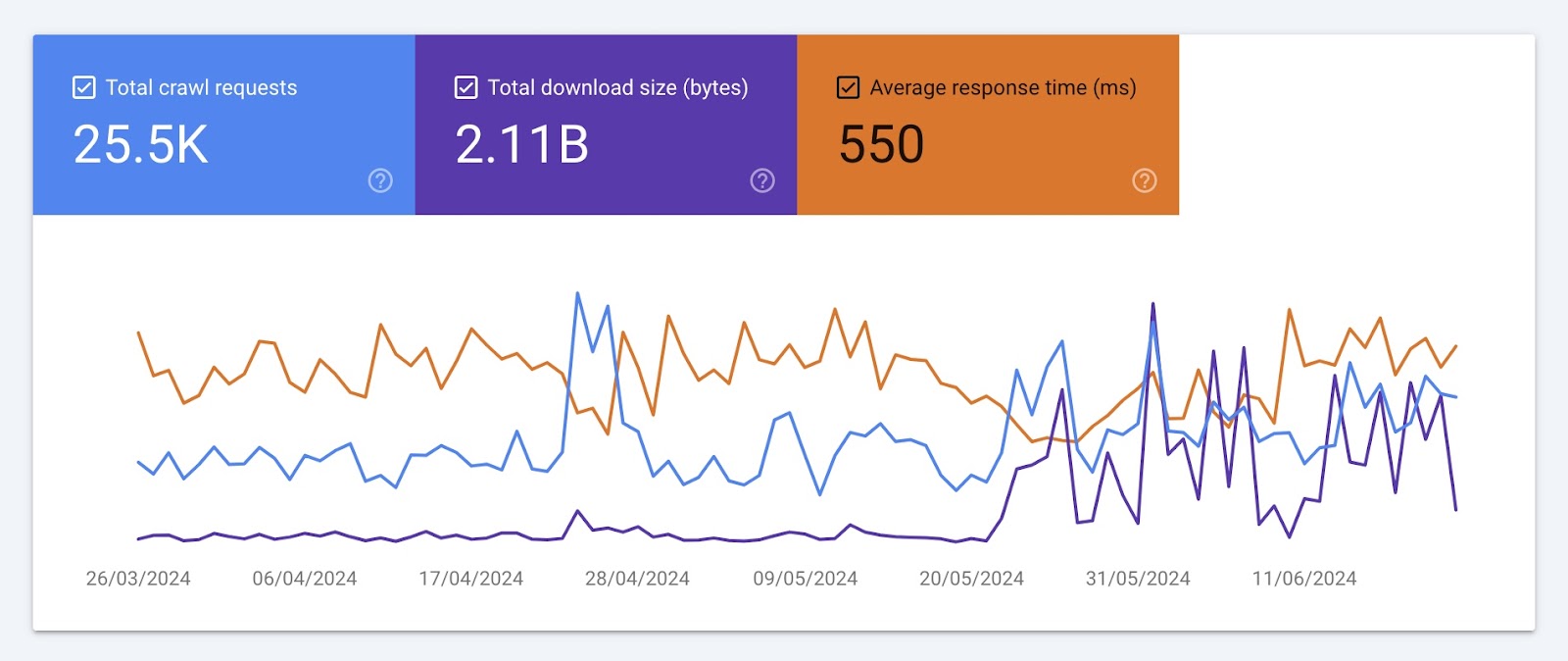
这些图表显示了三个指标随时间的发展:
- 爬网请求总数:谷歌的爬虫(如Googlebot)在过去三个月内提出的抓取请求数量
- 总下载大小:Google抓取工具在抓取您的网站时下载的字节数
- 平均响应时间:服务器响应爬网请求所需的时间
注意每个图表中的显着下降、峰值和趋势。 并与您的开发人员合作发现和解决任何问题。 像服务器错误或站点结构的更改。
"爬网请求细分"部分按响应、文件类型、用途和Googlebot类型对爬网数据进行分组。
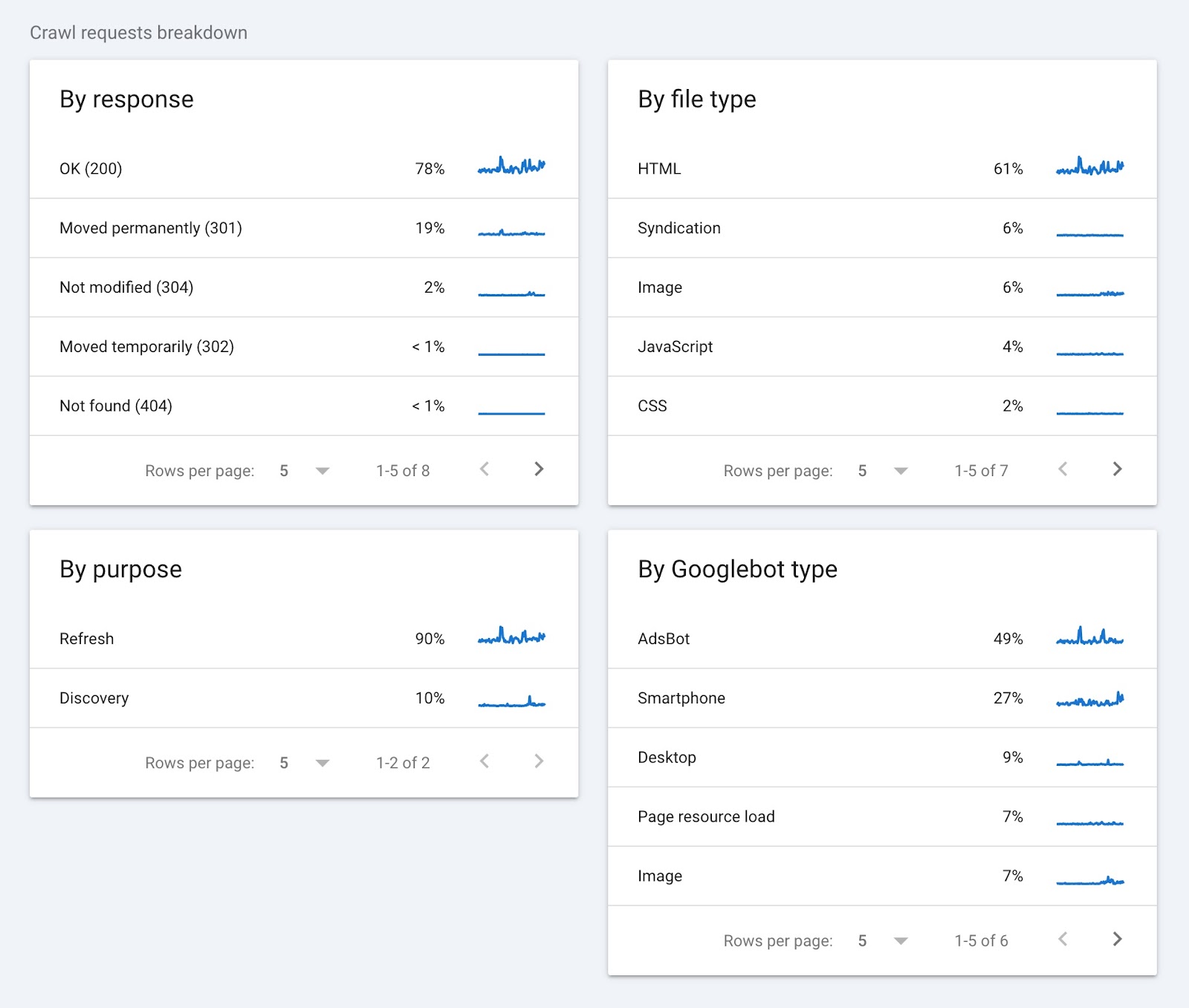
以下是这些数据告诉你的:
- 通过响应:向您展示您的服务器如何处理Googlebot的请求。 高比例的"OK(200)"回应是一个好兆头。 这意味着大多数页面都是可访问的。 另一方面,像404或301这样的错误可以指示损坏的链接或移动您的内容五月需要修复。
- 按文件类型:告诉您Googlebot正在抓取的文件类型。 这有助于发现与特定文件类型(如图像或JavaScript)相关的问题。
- 按目的:指示爬网的原因。 较高的发现百分比表明Google正在致力于寻找新页面。 高刷新数字意味着Google经常检查现有页面。
- 按Googlebot类型:显示哪些Googlebot用户代理正在抓取您的网站。 如果您注意到爬网峰值,您的开发人员可以检查用户代理类型以确定是否存在问题。
分析日志文件
日志文件是记录有关浏览器,人员和其他机器人向服务器发出的每个请求的详细信息的文档。 以及他们如何与您的网站互动。
通过查看日志文件,您可以找到以下信息:
- 访客的IP地址
- 每个请求的时间戳
- 请求的Url
- 请求的类型
- 传输的数据量
- 用户代理或爬虫程序
以下是日志文件的样子:

通过分析日志文件,您可以更深入地了解Googlebot的活动。 并确定详细信息,如抓取问题,Google抓取您的网站的频率以及您的网站为Google加载的速度。
日志文件保存在您的web服务器上。 因此,要下载和分析它们,您首先需要访问您的服务器。
一些托管平台有内置的文件管理器。 这是您可以查找,编辑,删除和添加网站文件的地方。
或者,您的开发人员或IT专家也可以使用文件传输协议(FTP)客户端下载日志文件,如菲利齐拉.
一旦你有你的日志文件,使用Semrush的日志文件分析器了解这些数据。 并回答像:
- 什么是你最抓取的页面?
- 哪些页面没有抓取?
- 爬网过程中发现了哪些错误?
打开该工具并将日志文件拖放到其中。 然后,点击"启动日志文件分析器.”
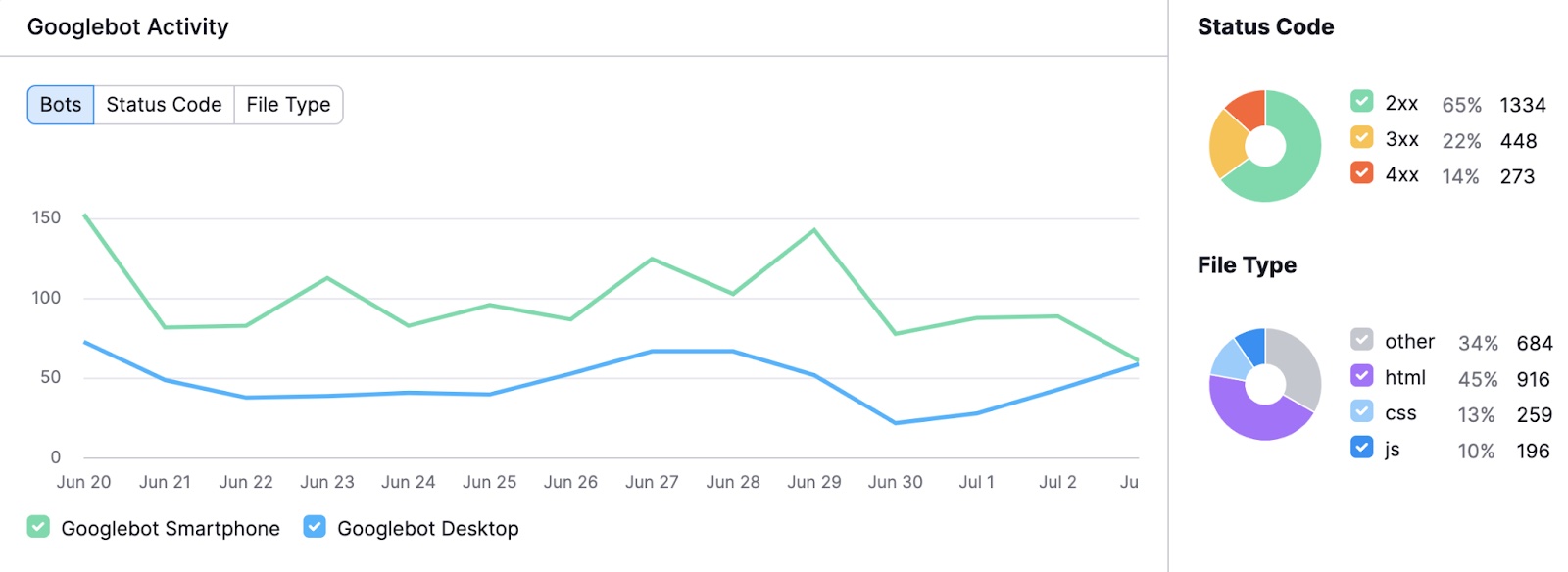
一旦您的结果准备就绪,您将看到一个图表,显示Googlebot在过去30天内在您的网站上的活动。 这有助于您识别不寻常的峰值或下降。
你还会看到不同的细分状态代码和请求的文件类型。
向下滚动到"按页点击"表,以获取有关单个页面和文件夹的更具体见解。
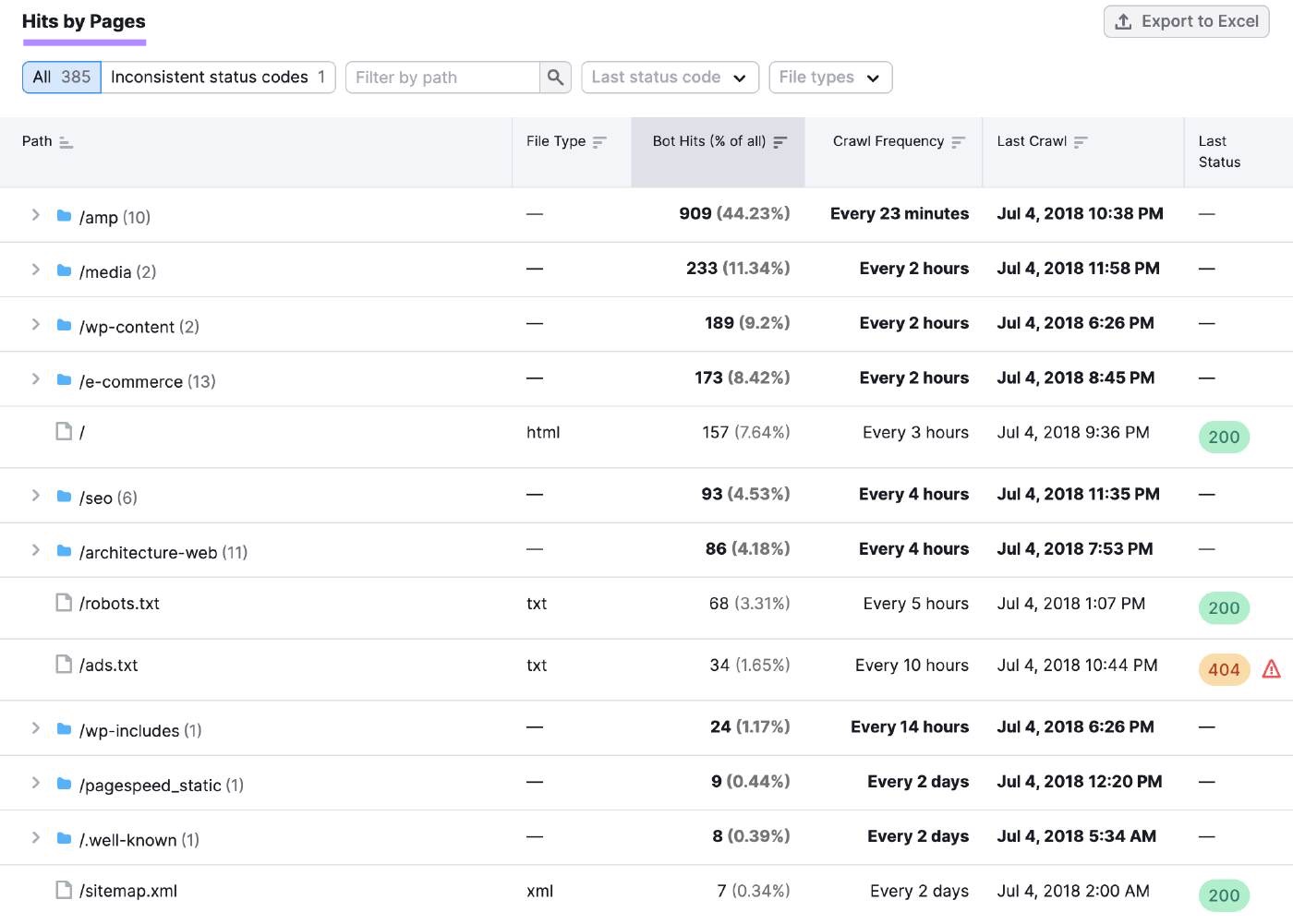
您可以使用此信息查找响应代码中的模式。 并调查任何可用性问题。
例如,跨多个页面的错误代码(如404或500)突然增加可能表明服务器问题导致广泛的网站中断。
然后,您可以联系您的网站托管服务提供商,以帮助诊断问题并使您的网站回到正轨。
如何阻止Googlebot
有时,您可能希望阻止Googlebot对您网站的整个部分进行爬网和索引。 甚至特定页面。
这可能是因为:
- 您的网站正在维护中,您不希望访问者看到不完整或损坏的页面
- 您希望隐藏Pdf或视频等资源,以免被编入索引并显示在搜索结果中
- 您希望防止某些页面公开,如intranet或登录页面
- 你需要优化你的爬行预算并确保Googlebot专注于您最重要的页面
这里有三种方法可以做到这一点:
robots.txt文件
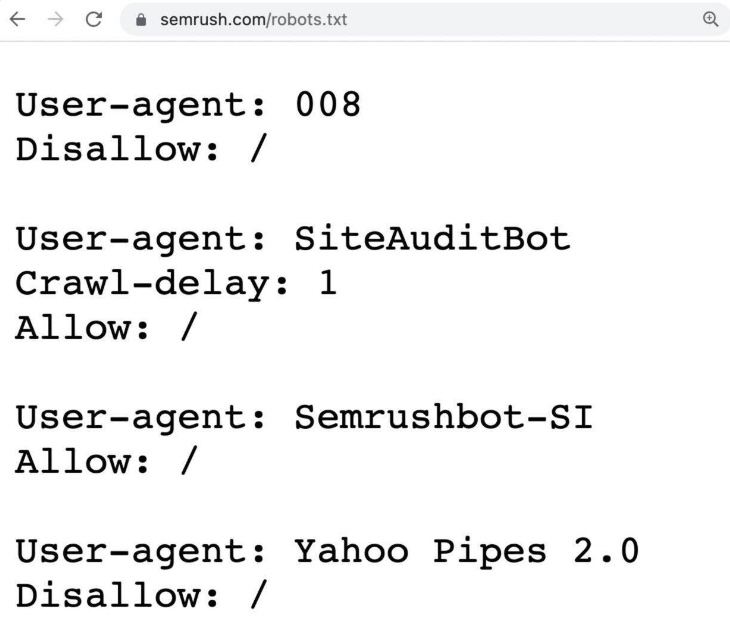
一个robots.txt文件是一组指令,告诉搜索引擎抓取工具,如Googlebot,他们应该和不应该抓取您网站的哪些页面或部分。
它有助于管理爬网程序流量,并可以防止您的网站被请求超载。
这是一个机器人的例子。txt文件:
例如,您可以添加一个robots.txt规则,以防止爬虫访问您的登录页面。 这有助于使您的服务器资源集中在站点的更重要区域。
像这样:
用户代理:Googlebot
禁止:/登入/进一步阅读: robots.txt:什么是robots.txt&为什么它对SEO很重要
然而,robots.txt文件不一定会让您的页面远离Google的索引。 因为Googlebot仍然可以找到这些页面(例如,如果其他页面链接到它们),然后它们仍然可能被索引并显示在搜索结果中。
如果您不希望页面出现在Serp中,请使用meta robots标签。
元机器人标签
Meta robots标签是一段HTML代码,可让您控制单个页面在Serp中的爬网,索引和显示方式。
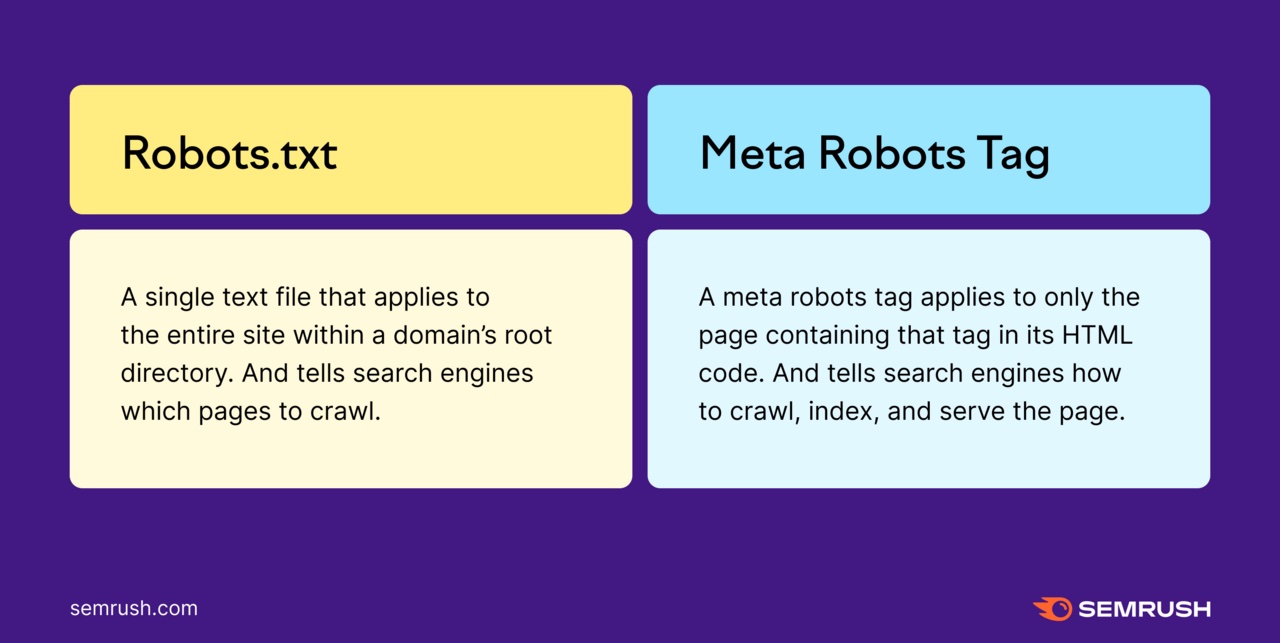
Robots标签及其说明的一些示例包括:
- 无索引:不要索引此页
- n.无影,无影:不要在此页面上索引图像
- 诺弗洛:不要跟随本页的连结
- 诺斯尼皮特:不要在搜索结果中显示此页面的片段或描述
您可以将这些标签添加到
页面代码的一部分。 例如,如果您想阻止Googlebot为您的页面编制索引,则可以添加无索引标记。像这样:
此标记将阻止Googlebot在搜索结果中显示该页面。 即使其他网站链接到它。
进一步阅读: 元机器人标签&X-机器人标签解释
密码保护
如果要阻止Googlebot和用户访问页面,请使用密码保护。
此方法可确保只有授权用户才能查看内容。 并且它可以防止页面被google编入索引。
您可能使用密码保护的页面示例包括:
- 管理仪表板
- 私人会员区
- 公司内部文件
- 网站的登台版本
- 机密项目页面
如果您使用密码保护的页面已编入索引,谷歌最终会将其删除从其搜索结果。
让Googlebot轻松抓取您的网站
搜索引擎优化的一半战斗是确保您的页面甚至显示在Serp中。 第一步是确保Googlebot实际上可以抓取您的页面。
定期监控网站的可抓取性和可索引性有助于您做到这一点。
找到可能会伤害您网站的问题很容易现场审核.
此外,它还允许您运行按需爬网和安排每天或每周自动重新抓取. 所以你总是在你的网站的健康之上。
今天就试试吧。