

 外贸B2B建站
外贸B2B建站  高端定制设计
高端定制设计  系统功能优势
系统功能优势 


 Google SEO优化
Google SEO优化  Google SEM广告
Google SEM广告  网站内容营销
网站内容营销  优化案例
优化案例  设计赏析
设计赏析  搜索引擎优化
搜索引擎优化  付费广告
付费广告  社媒运营
社媒运营  公司介绍
公司介绍  渠道共赢
渠道共赢  联系我们
联系我们 什么是robots.txt文件?
一个robots.txt文件是一组指令,告诉搜索引擎要抓取哪些页面以及要避免哪些页面,指导爬虫访问,但不一定会将页面排除在Google的索引之外。
一个robots.txt文件看起来像这样:
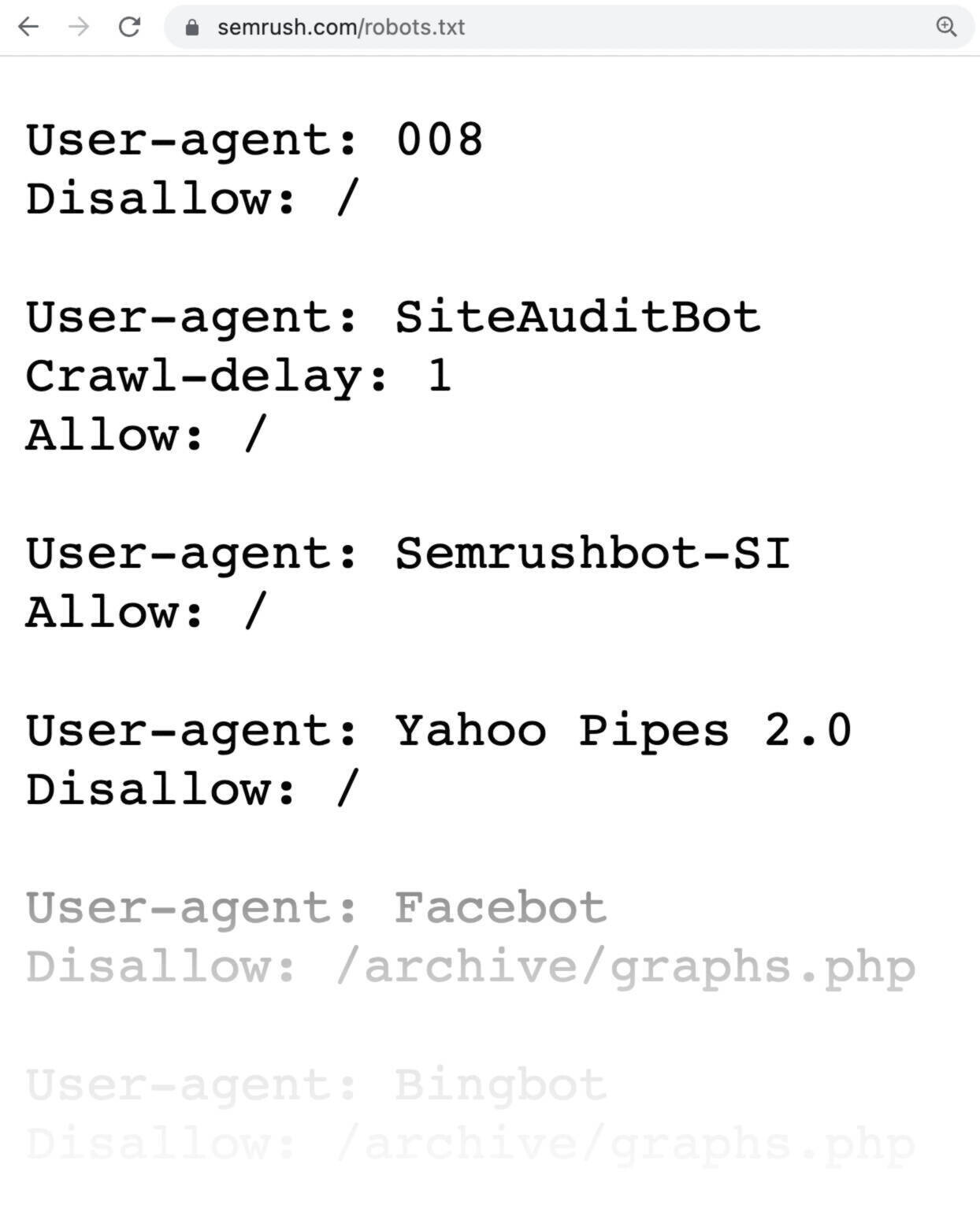
robots.txt文件可能看起来很复杂。 但是,语法(计算机语言)很简单。
在解释机器人的细节之前。txt,我们将澄清如何robots.txt不同于其他听起来相似的术语。
robots.txt与元机器人与X-机器人
robots.txt文件,meta robots标签和x-robots标签指导搜索引擎处理网站内容,但它们的控制级别不同,它们是否位于以及它们控制的内容。
考虑这些细节:
- robots.txt脧脗脭脴:此文件位于网站的根目录中,并向搜索引擎爬虫提供站点范围的说明,它们应该和不应该抓取站点的哪些区域
- 元机器人标签:这些标签是个别网页的代码段,并向搜索引擎提供特定于页面的说明,说明是否索引(包括在搜索结果中)和跟随(抓取每个页面上的链接
- X-机器人标签:这些代码段主要用于非HTML文件,如Pdf和图像,并在文件的HTTP头中实现
进一步阅读: 元机器人标签&X-机器人标签解释
为什么是robots.txt对SEO很重要?
一个robots.txt文件对于SEO很重要,因为它有助于管理网络爬虫活动,以防止它们超载您的网站和抓取不打算供公众访问的页面。
以下是使用机器人的几个原因。txt文件:
1. 优化爬网预算
用机器人阻止不必要的页面。txt允许Google的网络爬虫在重要的页面上花费更多的抓取预算(Google将在特定时间范围内在您的网站上抓取多少页面)。
爬网预算可能会根据网站的大小、运行状况和数量而有所不同。反向链接.
如果您的网站有更多的网页比其爬网预算,重要的网页可能无法获得索引。
未索引的页面不会排名,这意味着您浪费了时间创建用户在搜索结果中看不到的页面。
2. 阻止重复和非公共页面
并非所有页面都旨在包含在搜索引擎结果页面(Serp)和机器人中。txt文件允许您阻止那些非公共页面从爬行.
考虑暂存网站、内部搜索结果页面、重复页面或登录页面。 一些内容管理系统会自动处理这些内部页面。
例如,WordPress的不允许所有爬虫的登录页面"/wp-admin/"。
3. 隐藏资源
robots.txt允许您排除Pdf,视频和图像等资源,如果您想保持它们的私密性或让Google专注于更重要的内容。
如何做一个robots.txt文件工作?
一个robots.txt文件告诉搜索引擎机器人要抓取哪些网址,以及(更重要的是)要避免抓取哪些网址。
当搜索引擎机器人抓取网页时,他们会发现并遵循链接。 这个过程导致他们从一个站点到另一个跨不同的页面。
如果一个机器人发现了一个robots.txt文件,它在抓取任何页面之前读取该文件。
语法很简单。 您可以通过识别用户代理(搜索引擎机器人)并指定指令(规则)来分配规则。
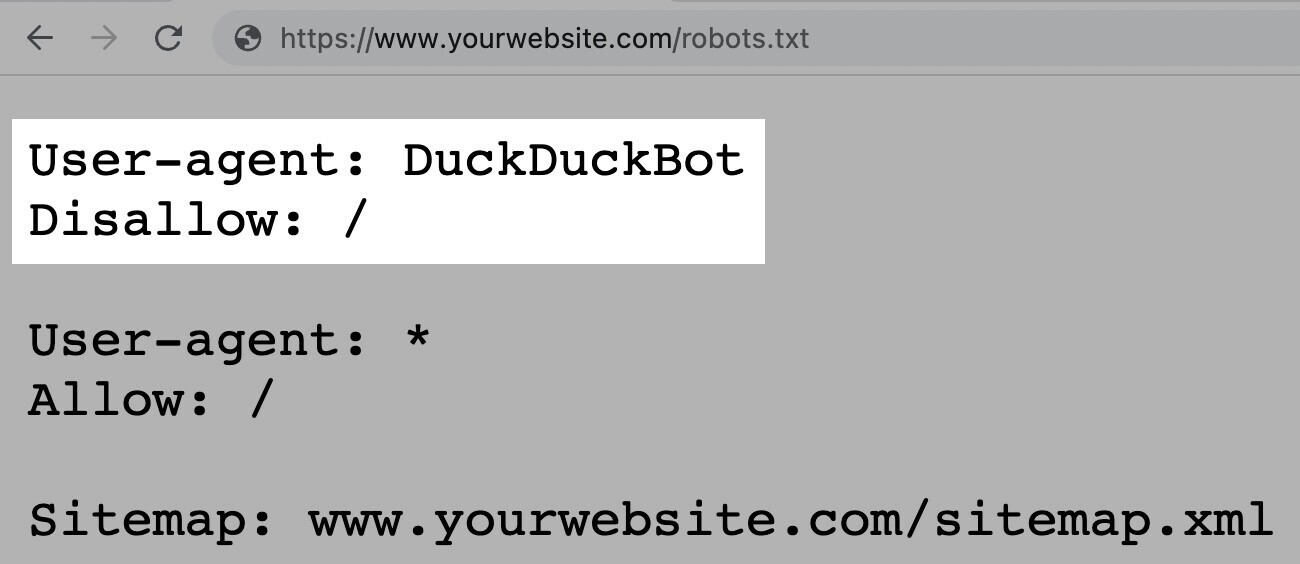
您可以使用星号(*)一次将指令分配给所有用户代理。
例如,以下指令允许除DuckDuckGo之外的所自然器人抓取您的网站:
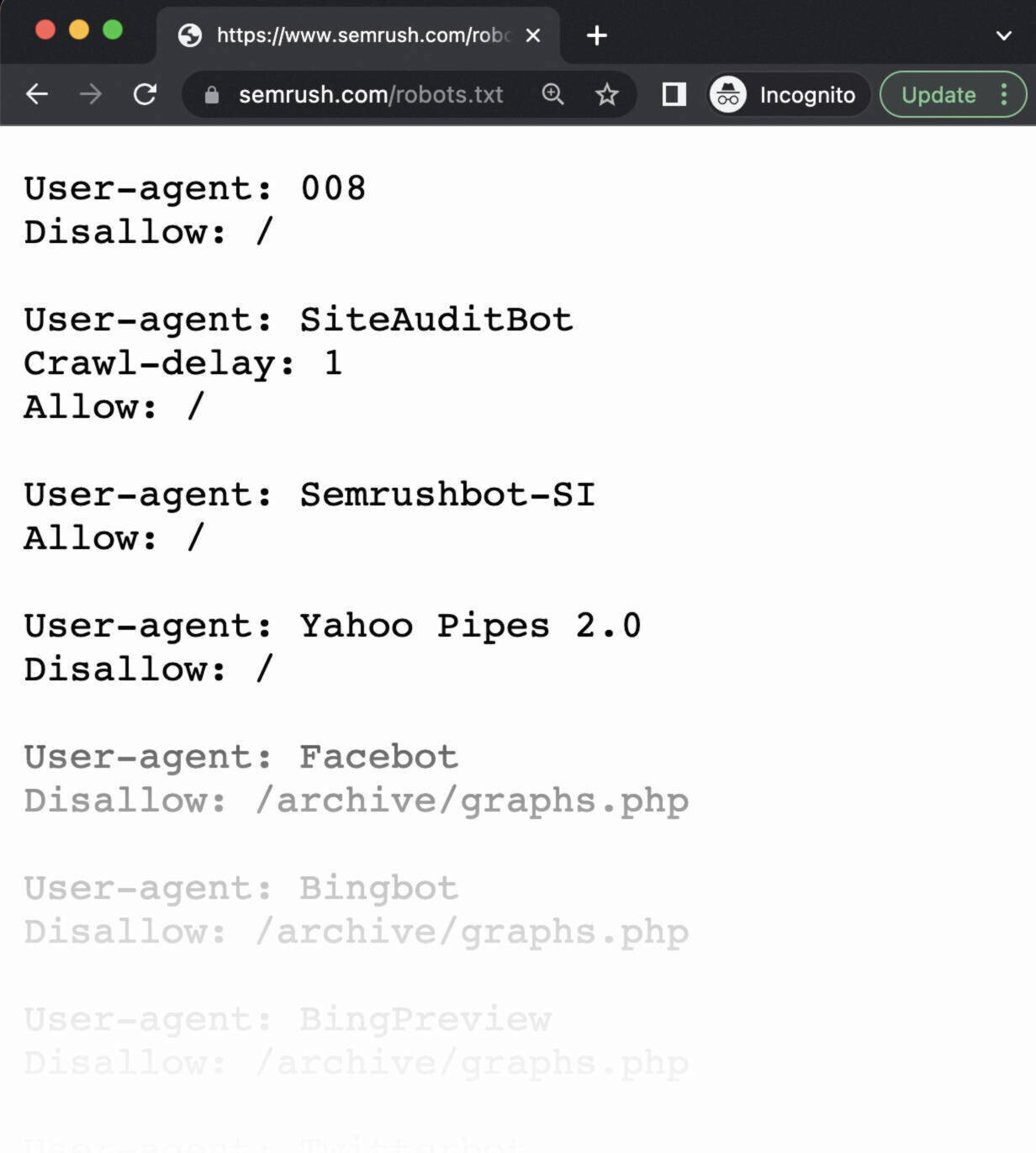
Semrush机器人爬网收集我们网站优化工具的见解,例如现场审核, 反向审计,而网页搜索引擎优化检查.
Semrush机器人尊重你的机器人的规则。txt文件,这意味着如果您阻止Semrush机器人爬行,它们将不会抓取您的网站。
但是,阻止Semrush机器人限制了某些Semrush工具的使用。
例如,如果您阻止SiteAuditBot抓取您的网站,则无法使用现场审核工具。 此工具可帮助分析和修复网站上的技术问题。
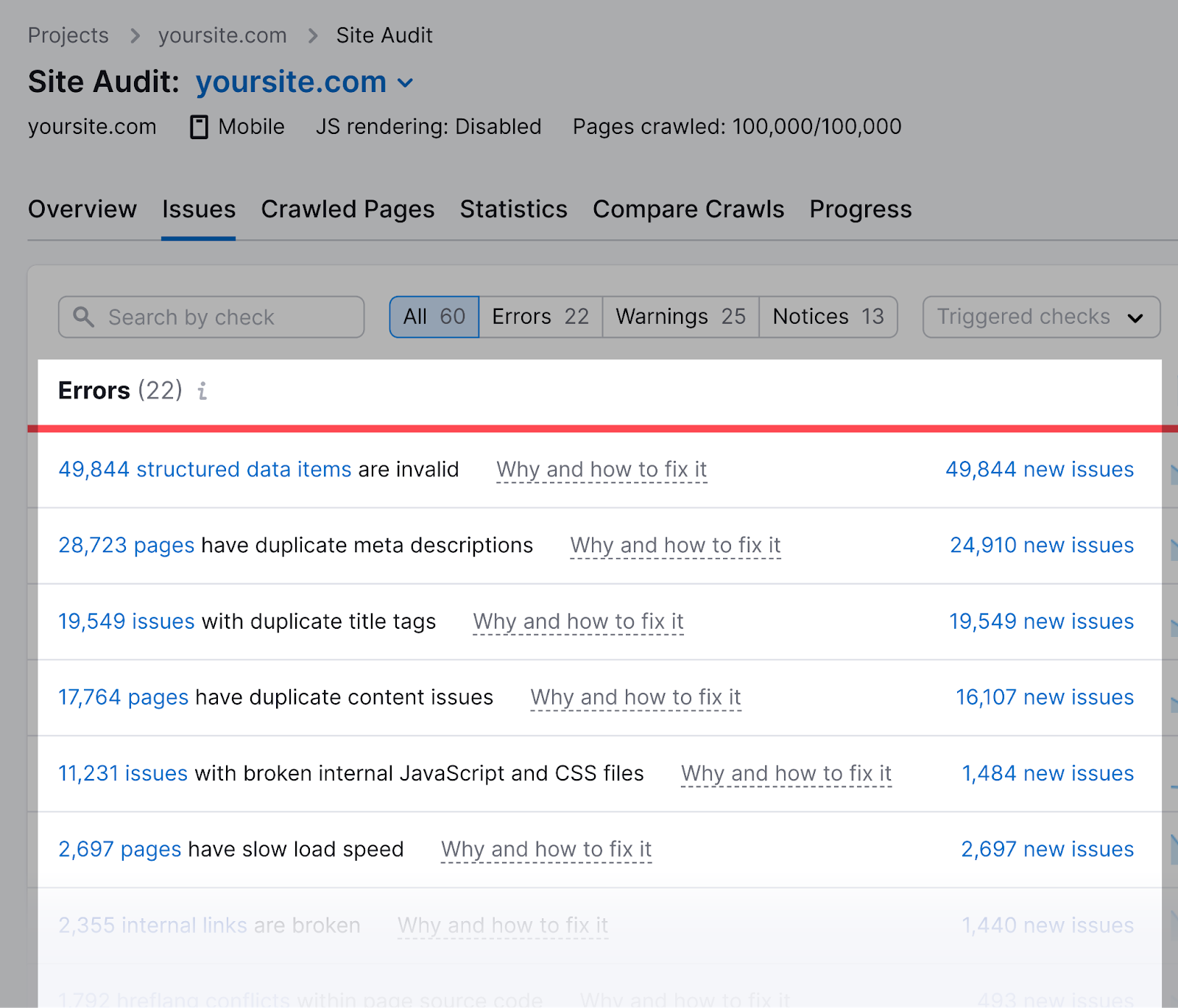
如果您阻止SemrushBot-SI抓取您的网站,则无法使用网页搜索引擎优化检查有效的工具。
因此,您失去了生成可以提高网页排名的优化想法的机会。
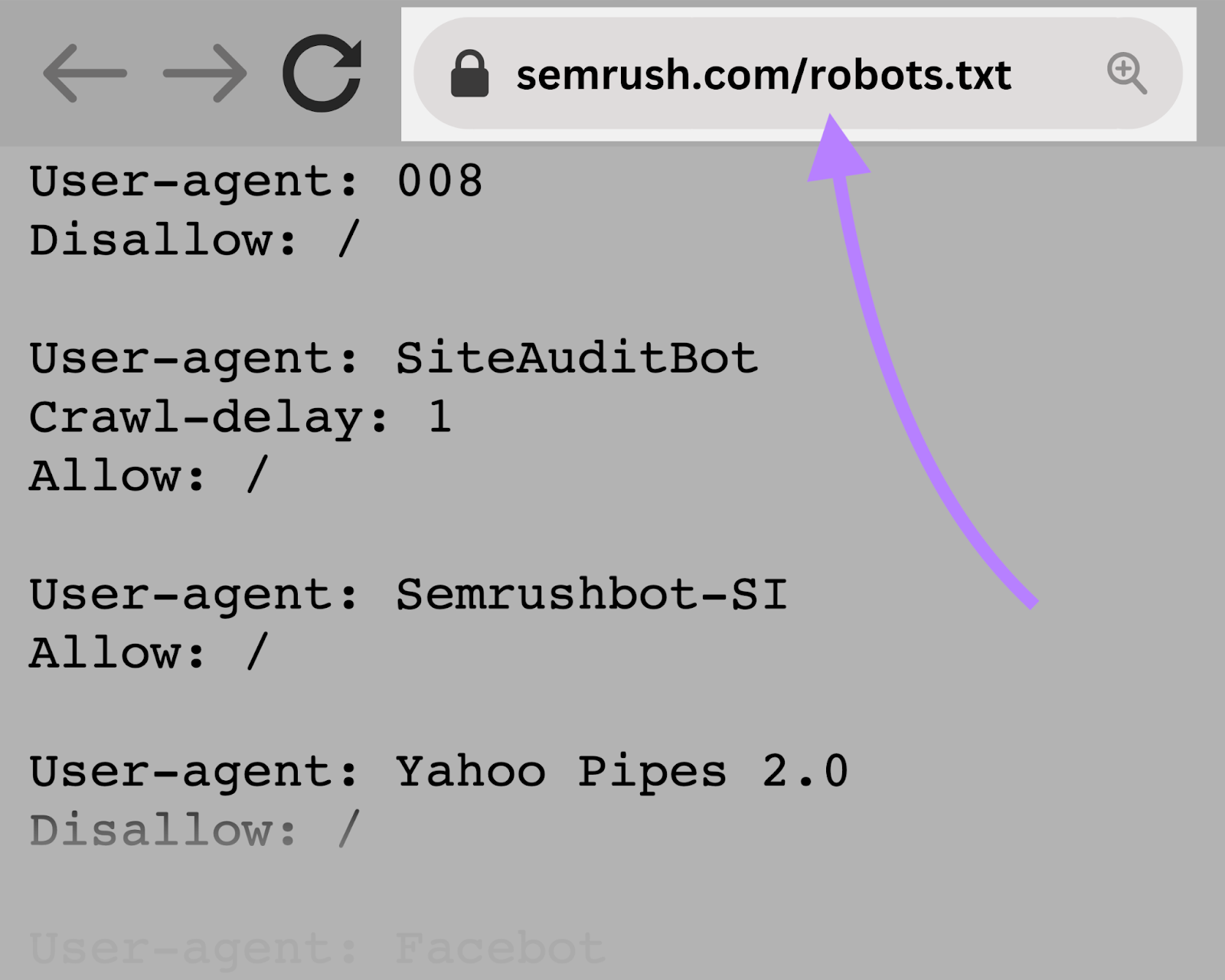
如何找到一个robots.txt文件
你的robots.txt文件托管在您的服务器上,就像您网站上的其他文件一样。
您可以查看任何网站的robots.txt文件通过键入网站的主页URL到您的浏览器,并添加"/robots.txt"的结尾。
例如:"https://semrush.com/robots.txt。"
机器人的例子。txt文件
这里有一些真实世界的robots.来自热门网站的txt示例。
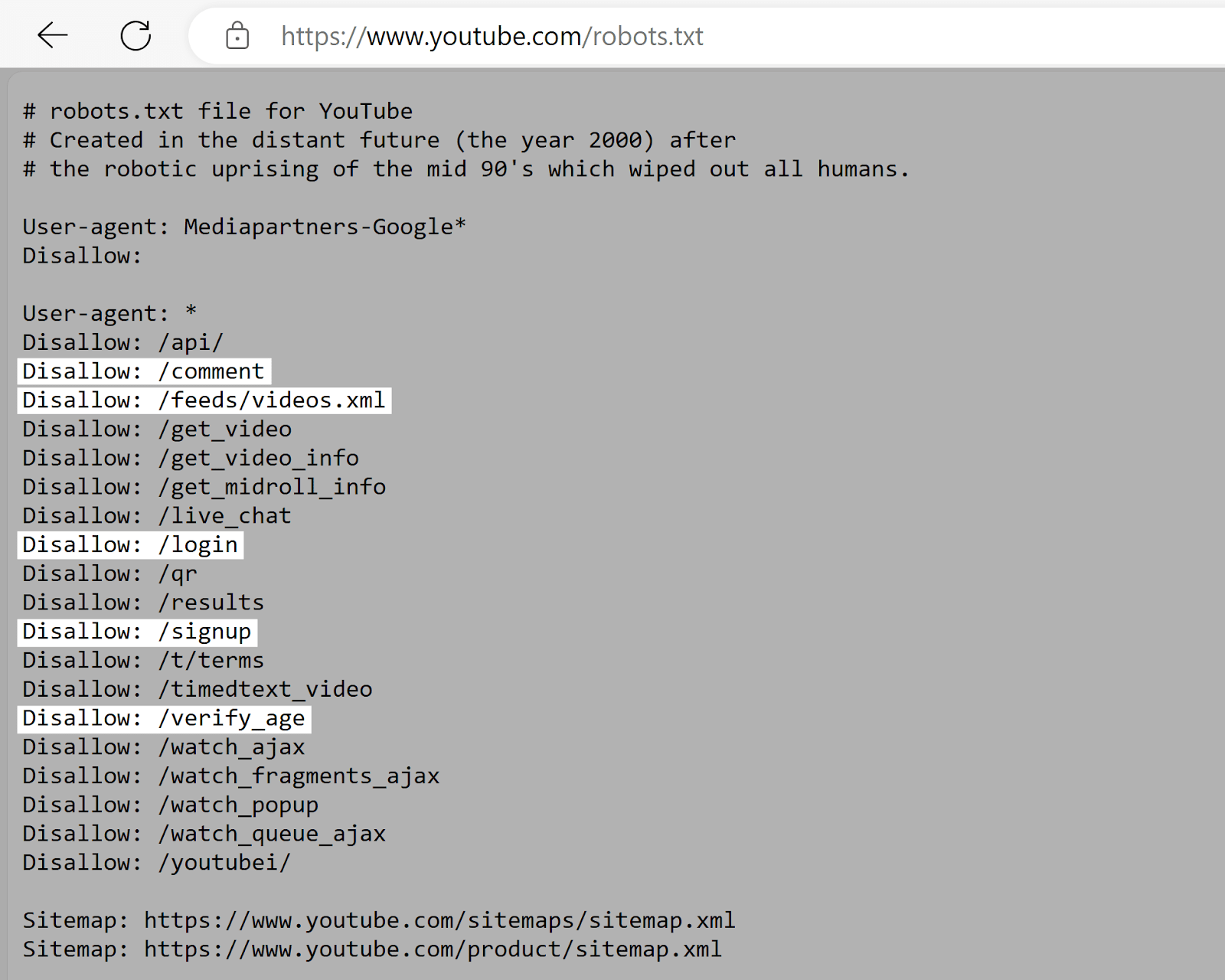
YouTube的
YouTube的的robots.txt文件告诉爬虫不要访问用户评论,视频源,登录/注册页面和年龄验证页面。
YouTube的的机器人中的规则。txt文件不鼓励索引用户特定的或动态内容这对搜索结果没有帮助,可能会引起隐私问题。
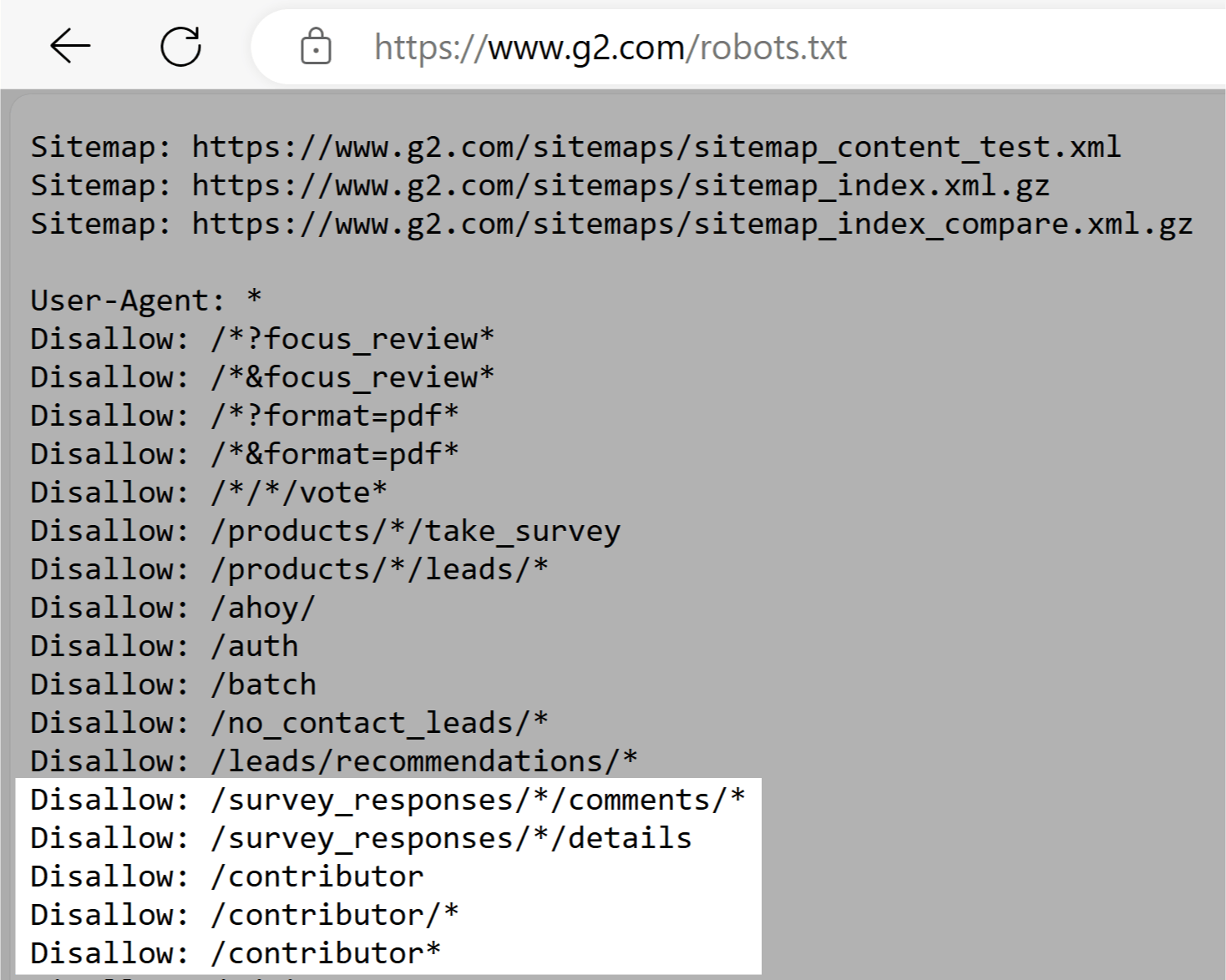
G2
G2的robots.txt文件告诉抓取工具不要访问包含用户生成内容的部分,如调查回复、评论和贡献者配置文件。
G2机器人中的规则。txt文件通过限制对可能敏感的个人信息的访问来帮助保护用户隐私。 这些规则还防止试图操纵搜索结果。
耐克
耐克的robots.txt文件使用disallow指令阻止爬虫访问用户生成的目录,如"/checkout/"和"*/member/inbox"。”
耐克机器人的规则。txt文件防止敏感的用户数据出现在搜索结果中,并减少操纵的机会SEO排名.
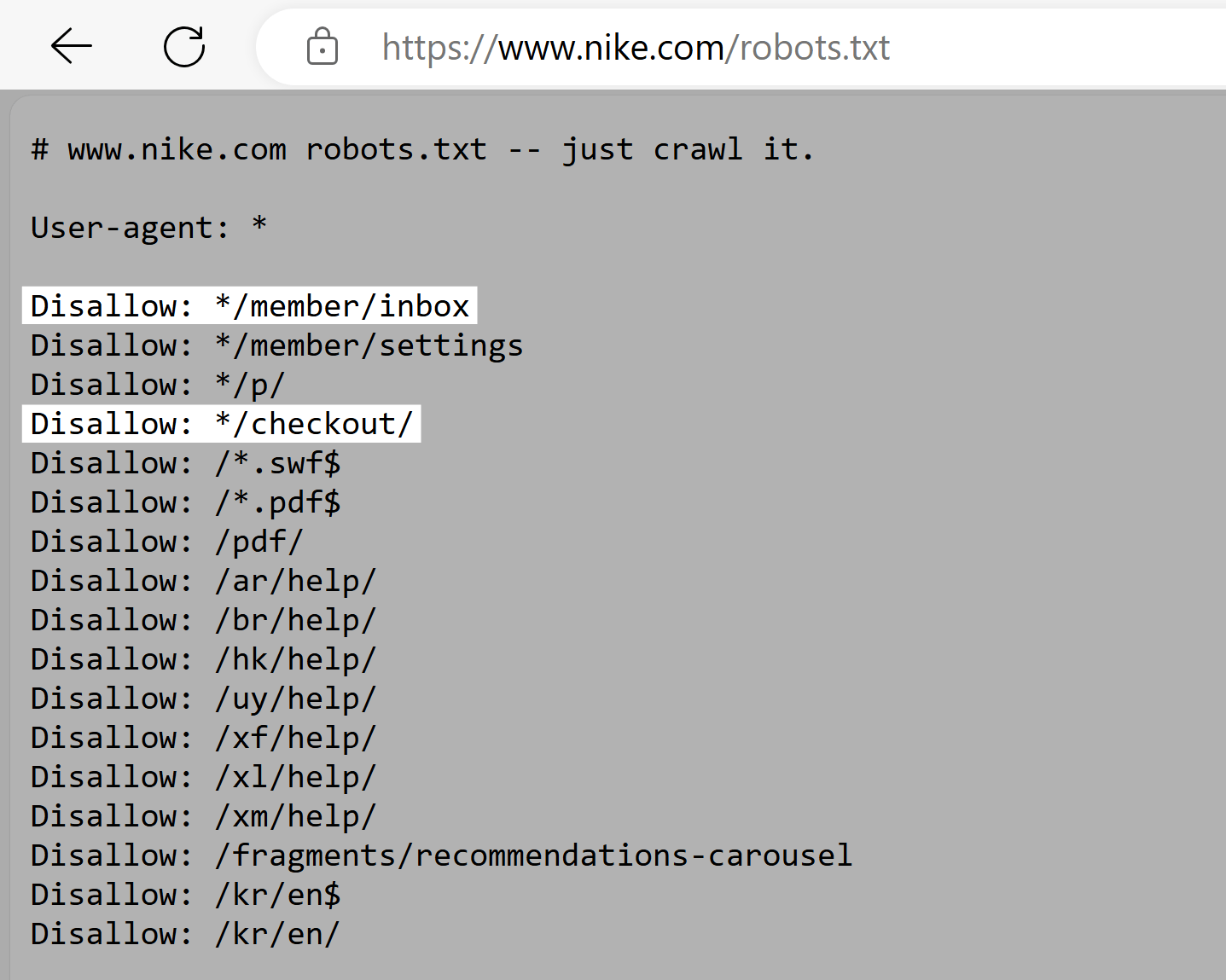
搜索引擎土地
搜索引擎土地的robots.txt文件使用disallow标签来阻止索引"/tag/"目录页面,这些目录页面通常具有较低的SEO值,并且可能导致重复内容问题。
在搜索引擎土地的机器人规则。txt文件鼓励搜索引擎关注更高质量的内容并优化网站的抓取预算-对于像搜索引擎土地这样的大型网站来说尤其重要。
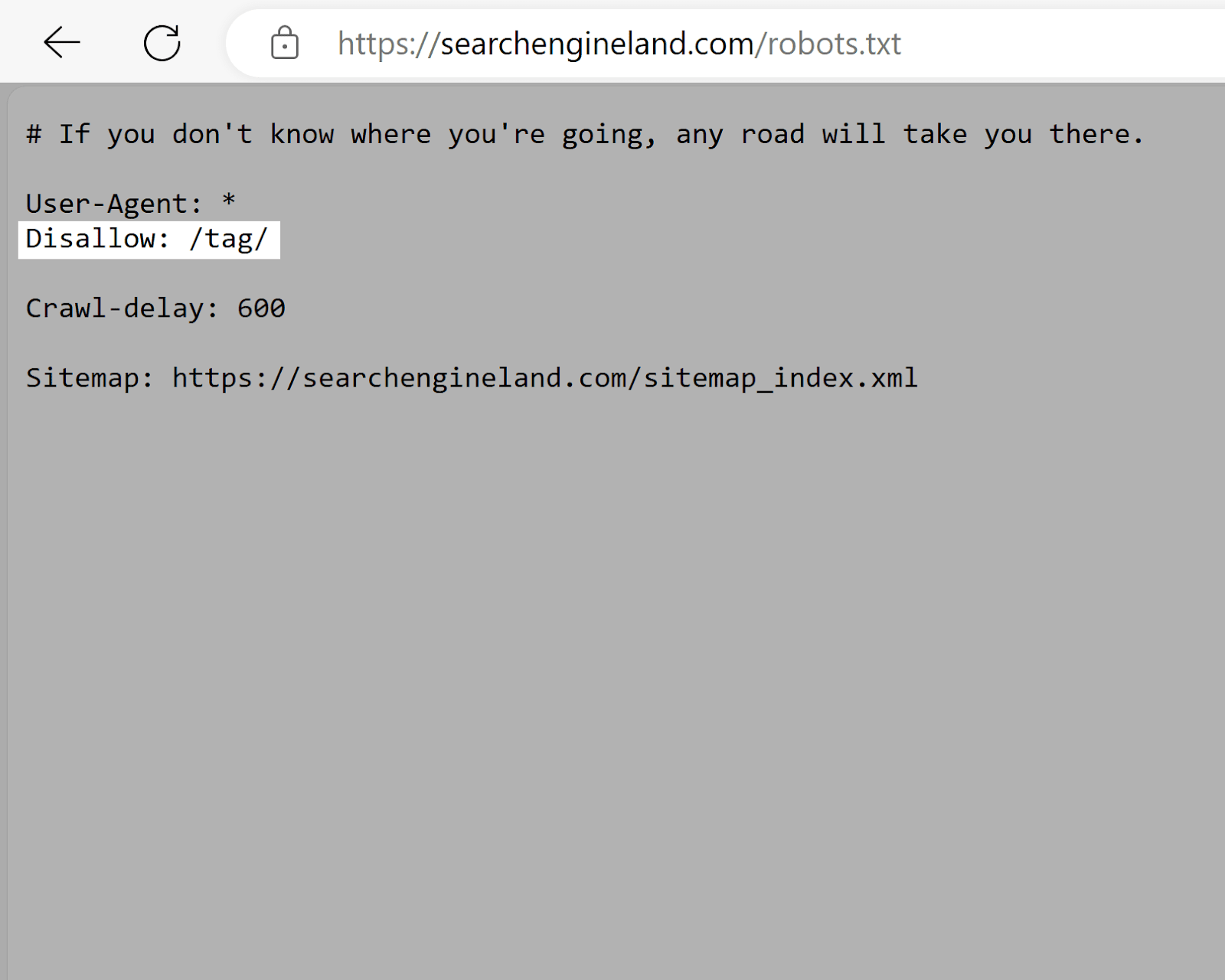
福布斯
福布斯的robots.txt文件指示Google不要抓取"/test/"目录,该目录可能包含测试或暂存环境。
《福布斯》机器人的规则。txt文件防止未完成或敏感的内容被索引,假设它没有链接到其他地方。
解释robots.txt语法
一个robots.txt文件由一个或多个指令块组成,每个块指定一个用户代理(搜索引擎机器人)并提供"允许"或"不允许"指令。
一个简单的块可能看起来像这样:
用户代理:Googlebot
不允许:/不为谷歌
用户代理:DuckDuckBot
不允许:/不为duckduckgo
网站地图:https://www.yourwebsite.com/sitemap.xml用户代理指令
每个指令块的第一行指定标识爬网程序的user-agent。
例如,使用这些行来防止Googlebot抓取您的WordPress的管理页面:
用户代理:Googlebot
不允许:/wp-admin/当存在多个指令时,机器人可以选择最具体的一个。
假设您有三组指令:一组用于*,一组用于Googlebot,一组用于Googlebot-Image。
如果Googlebot-News用户代理抓取您的网站,它将遵循Googlebot指令。
但是,Googlebot-Image用户代理将遵循更具体的Googlebot-Image指令。
不允许robots.txt指令
Disallow指令列出了爬网程序不应该访问的站点部分。
空的disallow行表示不存在任何限制。
例如,下面的规则允许所有爬网程序访问您的整个站点:
用户代理: *
允许: /要阻止整个站点中的所有抓取工具,请使用以下块:
用户代理: *
不允许: /允许指令
Allow指令允许搜索引擎抓取子目录或特定页面,即使在其他不允许的目录中也是如此。
例如,使用下面的规则来阻止Googlebot访问除一个之外的所有博客文章:
用户代理:Googlebot
禁止:/博客
允许:/博客/示例-帖子站点地图指令
Sitemap指令告诉搜索引擎--特别是必应、燕基科斯和Google--在哪里可以找到你的XML站点地图(列出您希望搜索引擎索引的所有页面的文件)。
下图显示了sitemap指令的外观:
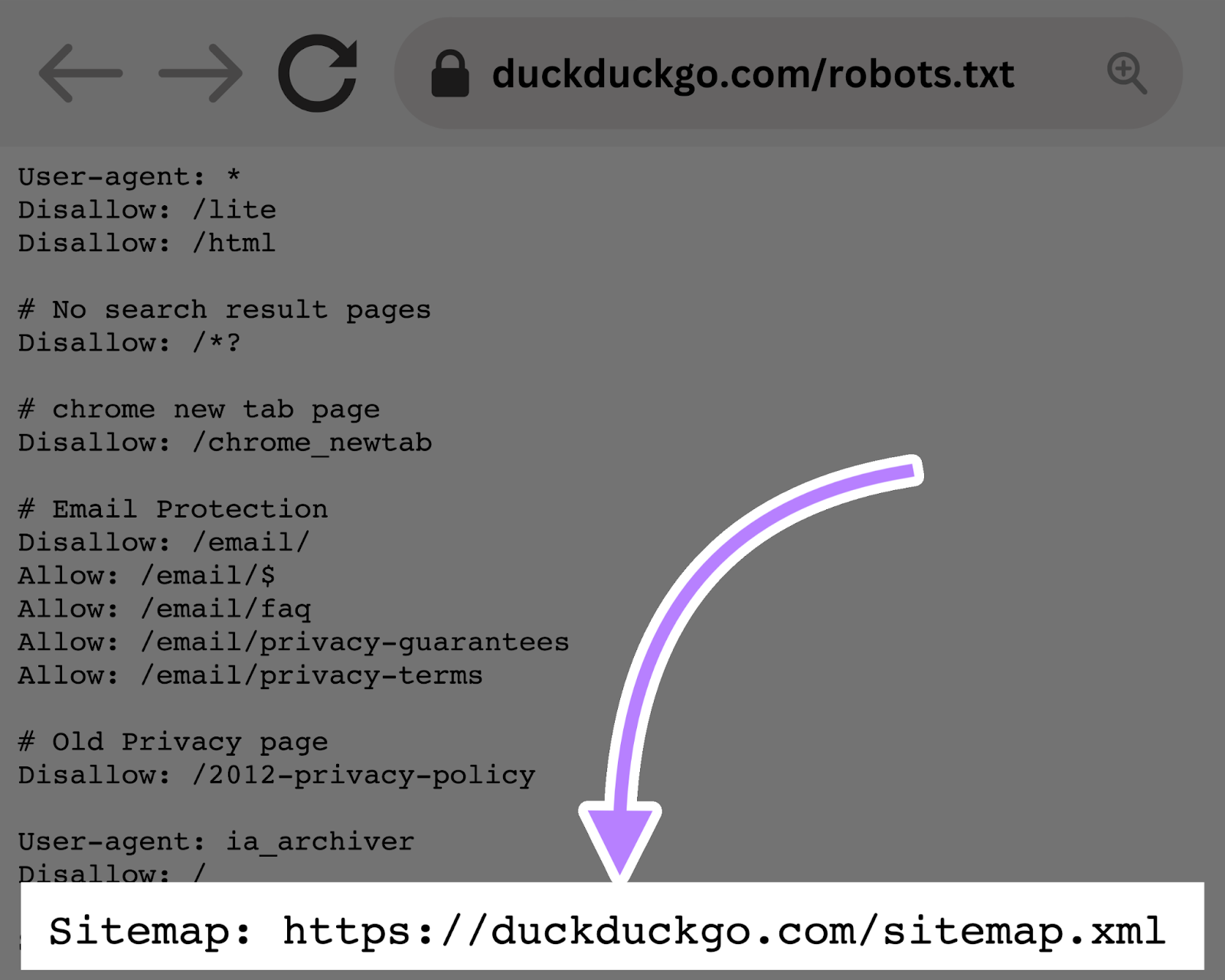
在你的机器人中包含一个站点地图指令。txt文件是一个快速的方式来分享你的网站地图。
但是,您还应该提交您的XML站点地图直接到搜索引擎通过他们的网站管理员工具,以加快爬行.
爬网延迟指令
Crawl-delay指令告诉爬虫在请求之间等待多少秒,这有助于避免服务器过载。
Google不再支持抓取延迟指令。 要设置Googlebot的爬网率,请使用谷歌搜索控制台.
必应和燕基科斯 do支持crawl-delay指令。
例如,使用以下规则设置每次爬网操作后的10秒延迟:
用户代理: *
爬行-延迟:10进一步阅读: 15可抓取性问题&如何修复它们
Noindex指令
一个robots.txt文件告诉搜索引擎什么是爬行,什么是不爬行,但不能可靠地保持一个URL的搜索结果-即使你使用noindex指令。
如果你在机器人中使用noindex。txt,页面仍然可以出现在没有可见内容的搜索结果中。
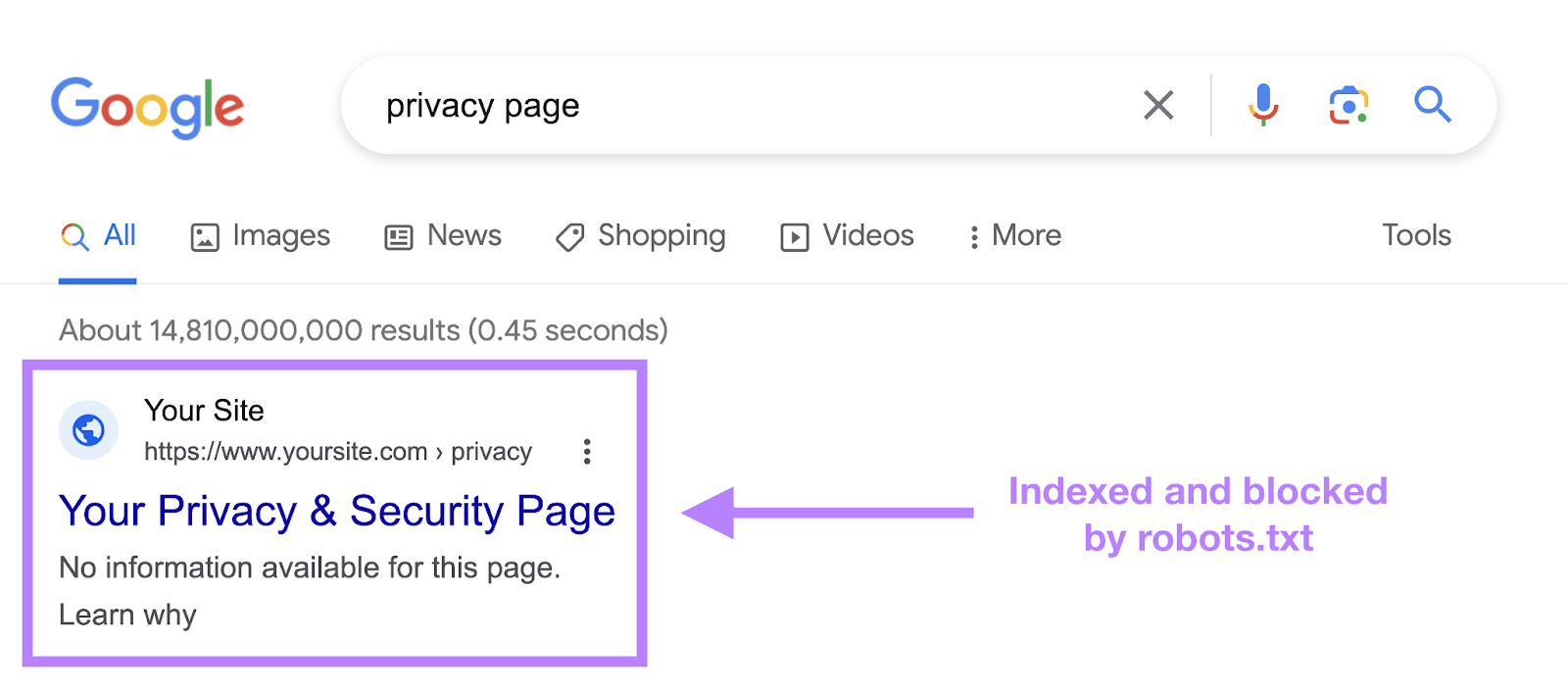
谷歌从未正式支持机器人中的noindex指令。txt和已确认所以在2019年9月。
要从搜索结果中可靠地排除页面,请使用元机器人noindex标签相反。
如何创建一个robots.txt文件
使用arobots.txt生成器工具快速创建一个robots.txt文件。
按照以下步骤创建robotx。txt文件从头开始:
1. 创建一个文件并将其命名为Robots。txt脧脗脭脴
打开a。a中的txt文档文本编辑器或web浏览器。
将文档命名为"robots.txt的。”
您现在可以开始输入指令。
2. 向机器人添加指令。txt文件
一个robots.txt文件包含一组或多组指令,每组包括多行指令。
每个组都以用户代理开始,并指定:
- 该组适用于谁(用户代理)
- 代理应访问哪些目录(页)或文件
- 代理不应访问哪些目录(页)或文件
- 站点地图(可选)告诉搜索引擎哪些页面和文件你认为重要
爬虫会忽略与上述指令不匹配的行。
想象一下,您不希望Google抓取您的"/clients/"目录,因为它仅供内部使用。
文件中的第一组看起来像这个块:
用户代理:Googlebot
禁止:/客户/之后,您可以为Google添加更多说明,如下所示:
用户代理:Googlebot
禁止:/客户/
不允许:/不为谷歌然后按enter两次以启动一组新的指令。
现在想象一下,您想要阻止所有搜索引擎访问"/archive/"和"/support/"目录。
阻止访问那些 :
用户代理:Googlebot
禁止:/客户/
不允许:/不为谷歌
用户代理: *
禁止:/存档/
禁止:/支持/完成后,添加站点地图:
用户代理:Googlebot
禁止:/客户/
不允许:/不为谷歌
用户代理: *
禁止:/存档/
禁止:/支持/
网站地图:https://www.yourwebsite.com/sitemap.xml将文件保存为"robots.txt的。”
3. 上传robots.txt文件
拯救你的机器人后。txt文件,将文件上传到您的网站,以便搜索引擎可以找到它。
上传机器人的过程。txt文件取决于您的托管环境。
在线搜索或联系您的主机提供商了解详细信息。
例如,搜索"上传robots.txt文件到[您的主机提供商]"以获取特定于平台的说明。
以下是一些解释如何上传机器人的链接。txt文件到流行的平台:
- robots.txt在WordPress的
- robots.txt在威克斯
- robots.txt在乔姆拉
- robots.txt在Shopify
- robots.txt在大商业
上传后,确认文件可访问,并且Google可以读取它。
4. 测试你的robots.txt文件
首先,验证任何人都可以查看您的robots.txt文件通过打开一个私人浏览器窗口,并输入您的网站地图网址。
例如,"https://semrush.com/robots.txt。"
如果你看到你的robots.txt内容,测试标记。
Google提供了两种测试选项:
- 该robots.txt报告在搜索控制台中
- 谷歌的开源robots.txt库(高级)
使用robots.如果您不是高级用户,txt报告在搜索控制台.
打开robots.txt报告.
如果您尚未将网站链接到搜索控制台,请先添加属性并验证网站所有权。
如果已验证属性,请在打开机器人后从下拉列表中选择一个。txt报告。
该工具报告语法警告和错误。
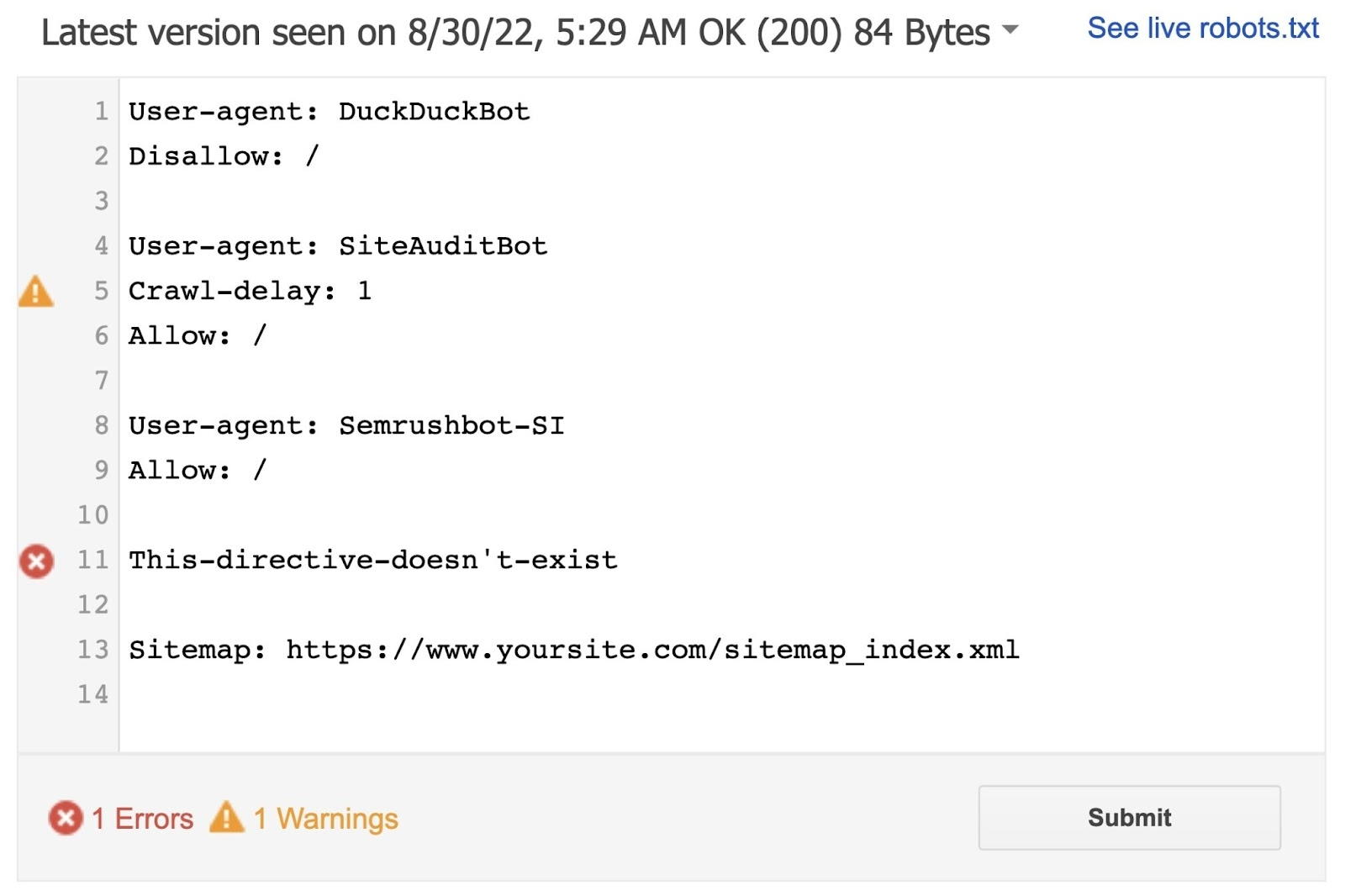
直接在页面上编辑错误或警告,然后随时重新测试。
机器人内部所做的改变。txt报告不会保存到您网站的实时robots.txt文件,所以复制和粘贴更正的代码到您的实际机器人.txt文件。
semrush氏现场审核工具也可以检查robots.txt问题。
设置项目并运行审计。
当工具准备就绪时,导航到"问题"标签和搜索"robots.txt的。”
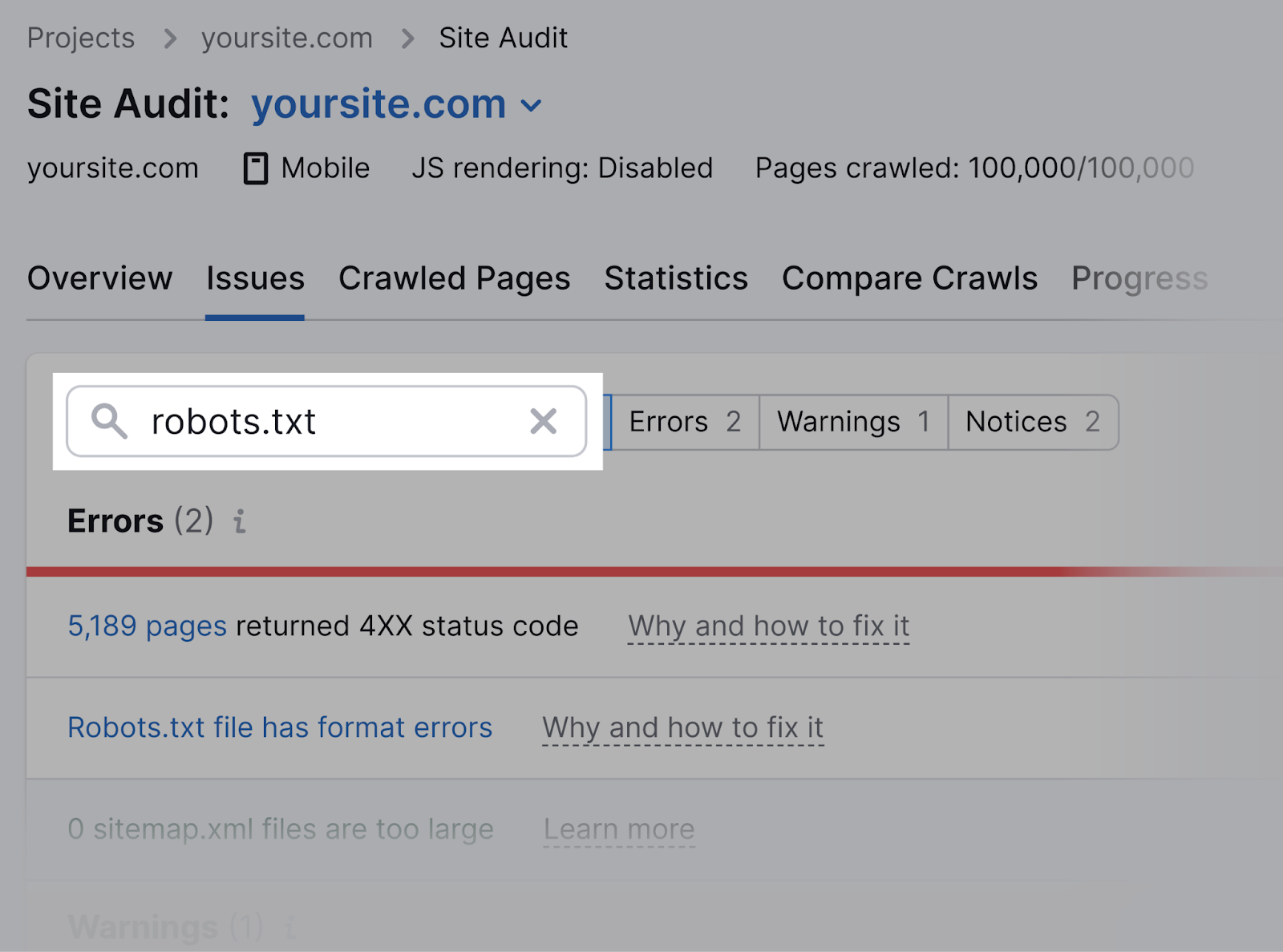
点击"robots.txt文件有格式错误"如果出现的话。
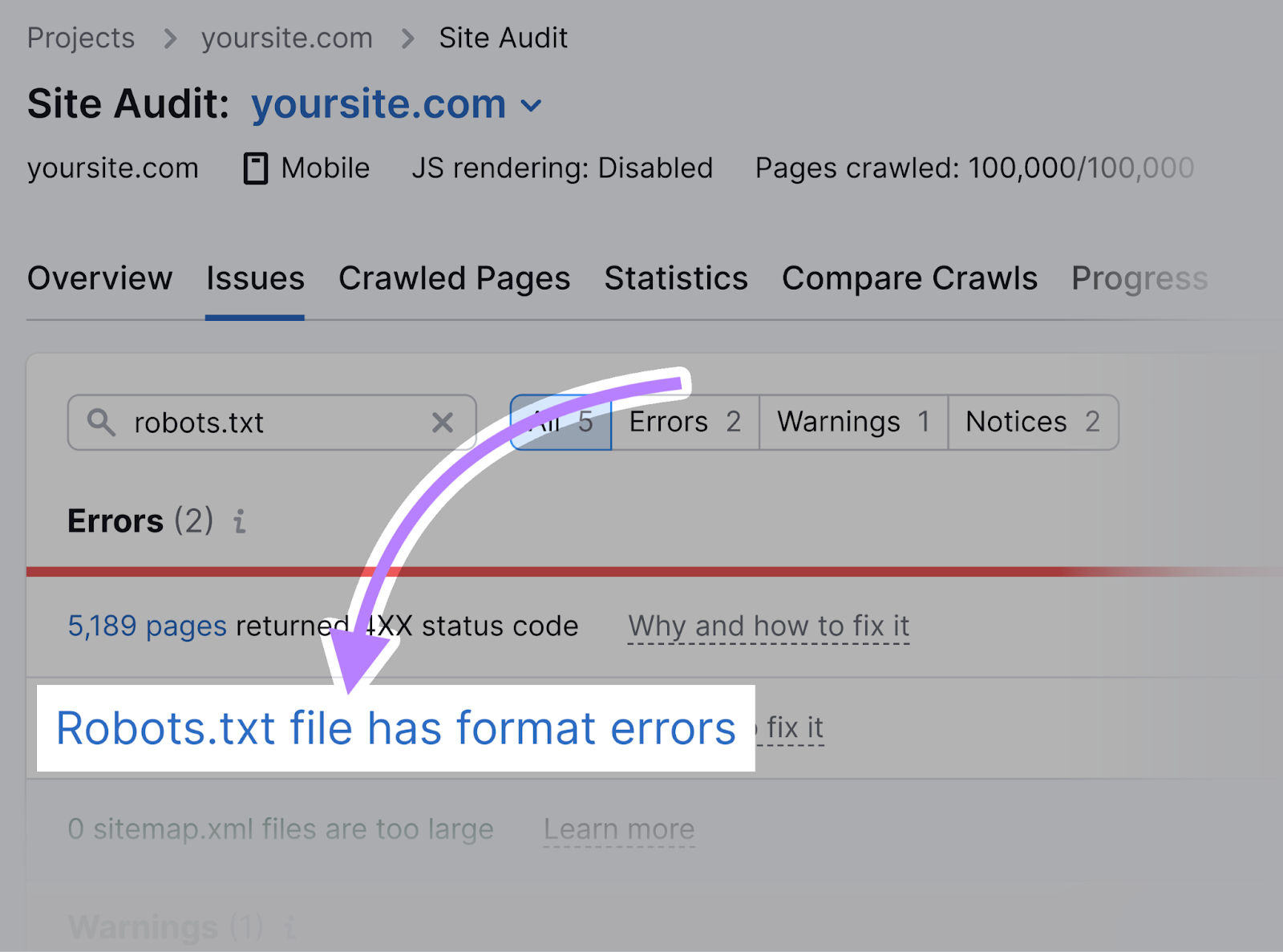
查看无效行列表。
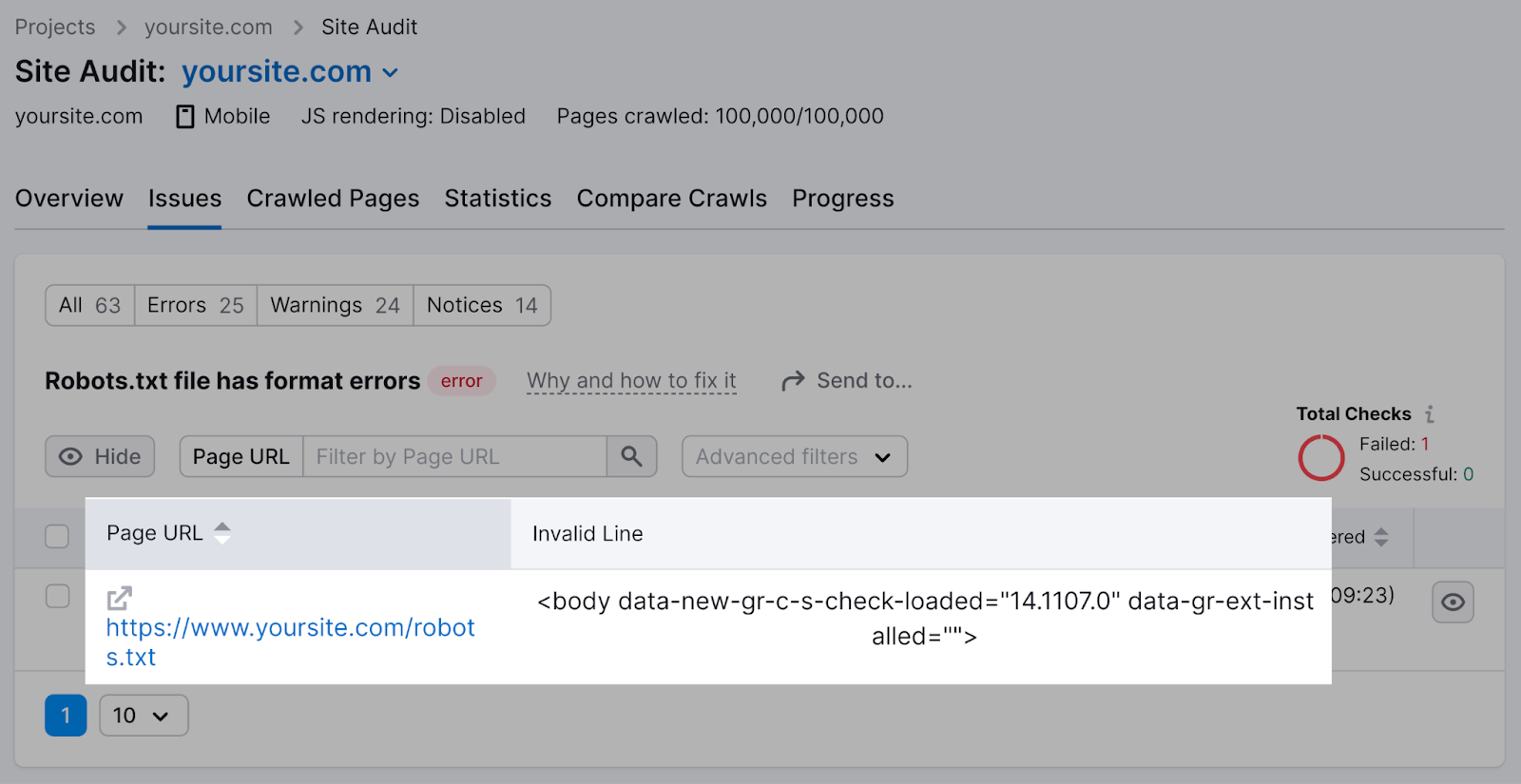
点击"为什么以及如何解决它"作具体说明。
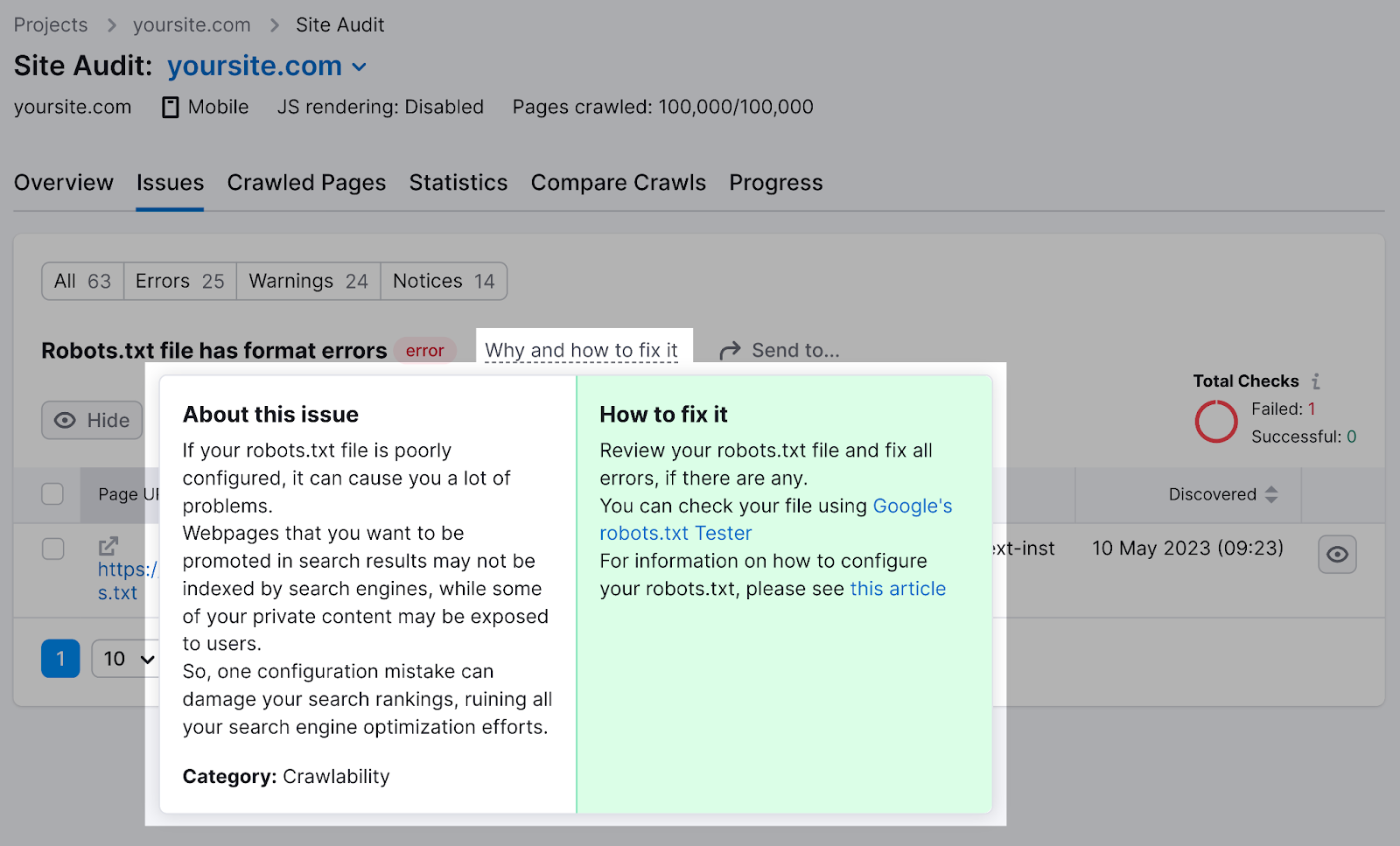
检查你的robots.定期txt文件。 即使是小错误也会影响网站的可索引性。
robots.txt最佳实践
为每个指令使用新行
将每个指令放在自己的行上,以确保搜索引擎可以阅读它们并遵循说明。
不正确的例子:
用户代理:*不允许:/管理员/
不允许:/目录/正确的例子:
用户代理: *
禁止:/行政/
不允许:/目录/每个用户代理只使用一次
列出每个用户代理一次,以保持文件的组织和减少人为错误的风险。
令人困惑的例子:
用户代理:Googlebot
禁止:/示例-页面
用户代理:Googlebot
禁止:/示例-第2页清楚的例子:
用户代理:Googlebot
禁止:/示例-页面
禁止:/示例-第2页在同一个用户代理下编写所有指令更干净,并帮助您保持井井有条。
使用通配符来澄清方向
使用通配符(*)广泛应用指令。
防止搜索引擎访问带参数的url从技术上讲,你可以把它们一个一个地列出来。
但是,您可以使用通配符简化方向。
效率低下的例子:
用户代理: *
不允许:/鞋子/面包车?
不允许:/鞋/耐克?
不允许:/鞋/阿迪达斯?有效的例子:
用户代理: *
不允许:/鞋/*?上面的示例阻止所有搜索引擎机器人抓取带有问号的"/shoes/"子文件夹下的所有Url。
使用'$'表示URL的结尾
使用"$"表示URL的结尾。
要阻止搜索引擎爬取所有特定文件类型,使用"$"可帮助您避免单独列出所有文件。
效率低下:
用户代理: *
不允许:/photo-a.jpg
不允许:/photo-b.jpg
不允许:/photo-c.jpg效率高:
用户代理: *
不允许:/*。jpg$小心使用"$",因为错误可能导致意外解锁。
使用哈希符号添加注释
通过用"#"开始一行来添加注释—爬虫忽略以哈希开头的任何内容。
例如:
用户代理: *
#登陆页面
禁止:/着陆/
不允许:/lp/
#档案
禁止:/档案/
禁止:/私人档案/
#网站
允许:/网站/*
禁止:/网站/搜索/*开发人员有时会使用哈希添加幽默注释,因为大多数用户从未看到该文件。
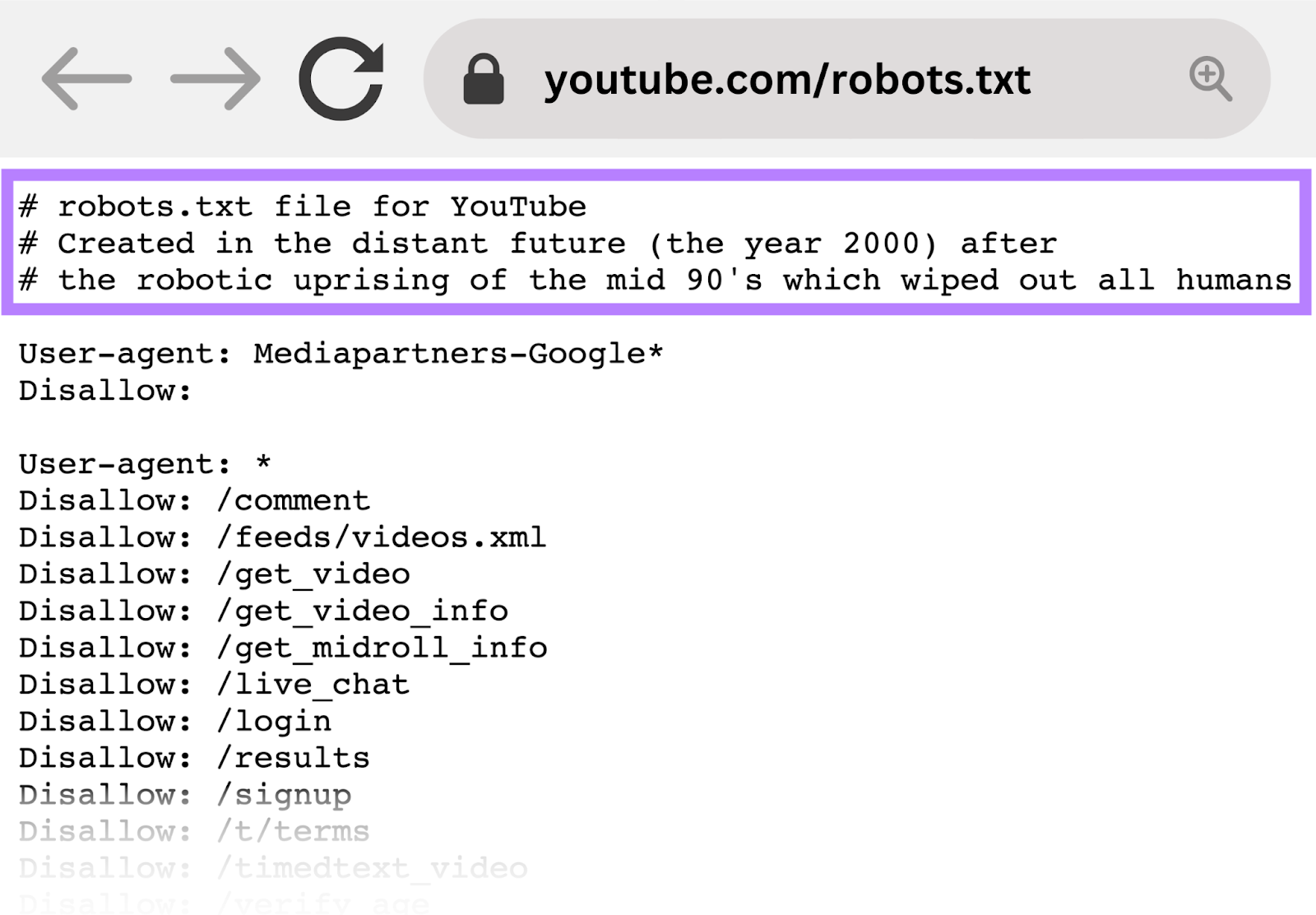
例如,YouTube的的robots.txt文件写道:"创建于遥远的未来(2000年)后,机器人起义的90年代中期,消灭了所有的人类。”
还有耐克的robots.txt读取"just crawl it"(对其"just do it"标语的点头)并具有该品牌的徽标。

使用单独的robots.不同子域的txt文件
robots.txt文件仅控制它们驻留的子域上的爬网,这意味着您可能需要多个文件。
如果您的网站是"domain.com"而你的博客是"blog.domain.com,"创建一个robots.域根目录和博客根目录的txt文件.
5个robots.txt错误,以避免
当创建你的robots.txt文件,注意以下常见错误:
1. 不包括robots.根目录下的txt
你的robots.txt文件必须位于您的网站的根目录,以确保搜索引擎抓取器可以很容易地找到它。
例如,如果您的网站主页是"www.example.com,"将文件放在"www.example.com/robots.txt。"
如果你把它放在一个子目录中,比如"www.example.com/contact/robots.txt,"搜索引擎可能找不到它,并可能假设您没有设置任何爬行指令。
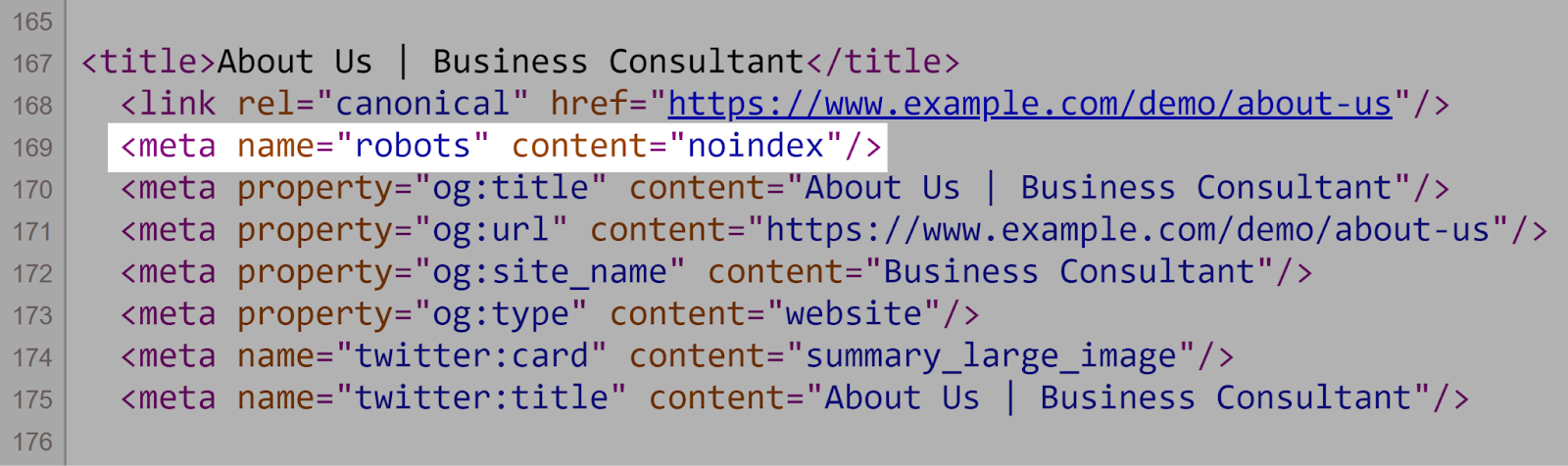
2. 在机器人中使用Noindex指令。txt脧脗脭脴
不要在机器人中使用noindex指令。txt-谷歌不支持机器人中的noindex规则。txt文件。
相反,使用meta robots标签(例如,)在各个页面上控制索引。
3. 阻止JavaScript的和CSS
避免阻止访问JavaScript的和CSS文件通过robots.txt除非必要(例如,限制对敏感数据的访问)。
阻止javascript和CSS文件的抓取使搜索引擎很难理解您的地盘结构和内容,这可能会损害您的排名。
进一步阅读: JavaScript的 SEO:如何优化搜索引擎的JS
4. 不阻止访问未完成的网站或页面
阻止搜索引擎抓取您网站的未完成版本,以防止在您准备好之前被发现(也为每个未完成的页面使用元机器人noindex标签)。
搜索引擎抓取和索引一个正在开发的页面可能会导致一个糟糕的用户体验和潜力重复内容问题.
使用robots.txt以保持未完成的内容私有,直到您准备好启动。
5. 使用绝对Url
在机器人中使用相对Url。txt文件,使其更易于管理和维护。
绝对Url是不必要的,如果您的域更改.
❌ 使用绝对Url的示例(不推荐):
用户代理: *
不允许:https://www.example.com/private-directory/
不允许:https://www.example.com/temp/
允许:https://www.example.com/important-directory/✅ 相对Url示例(推荐):
用户代理: *
不允许:/私有目录/
不允许:/temp/
允许:/重要目录/保持你的robots.txt文件无错误
现在你明白机器人是如何的了。txt文件工作,你应该确保你的优化。 即使是小错误也会影响网站在搜索结果中的爬网、索引和显示方式。
semrush氏现场审核工具可以分析你的robots.txt文件的错误容易,并提供可操作的建议,以解决任何问题.